在看了一个GitChat之后,在自己的blog里面做一下notes和写一下自己的想法。
推荐”石杉的架构笔记“,也是这篇文章的出处。
1. 概述
消息中间件(Message Queue,简称 MQ)是我们平时经常用到的一个东西,但是对于业务而言,可能我们平时更多的是在于会实现生产信息,消费信息。但是深入思考之后可能发现下面的几个问题我们从未认真思考过:
- 为何要使用MQ
- 使用了MQ之后有什么缺点?
- 怎么保证MQ消息不丢失?
- 怎么保证MQ的高可用性?
那么下面就做一些总结。
2. 为什么要用MQ?
MQ 的核心场景有三个:
- 异步
- 解耦
- 削峰填谷
2.1 异步
异步主要是针对这种情况:调用不同系统接口所需要的时间长度不同,那么如果等待不同接口全部返回确认的消息再对用户进行返回的事件过长用户无法接受哦。
例如下面这个例子:
假设 A 系统接收一个请求,需要在自己本地写库执行 SQL,接着需要调用 BCD 三个系统的接口。自己本地写库要 3ms,调用 BCD 三个系统分别要 300ms、450ms、200ms。最终请求总延时是 3 + 300 + 450 + 200 = 953ms,接近 1s,可能用户会感觉太慢了。
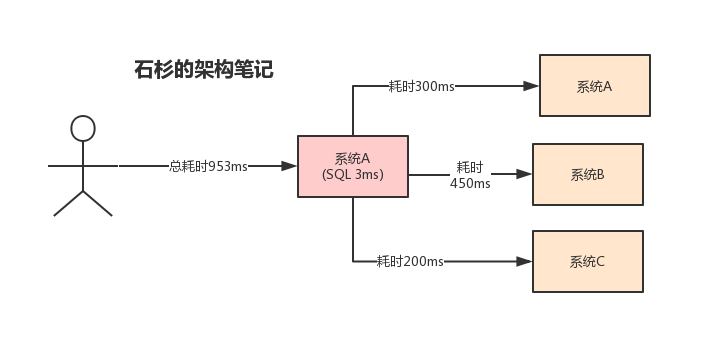
但是当使用MQ 之后,系统 A 只要发送三条消息到 MQ 的三个消息队列,然后就返回给用户了。这样的话所有耗时就是发送到 MQ 的耗时,再加上发送给用户的耗时。假设发送消息到 MQ 中耗时 20ms,那么用户感知到这个接口的耗时仅仅是 20 + 3 = 23ms,用户几乎无感知。
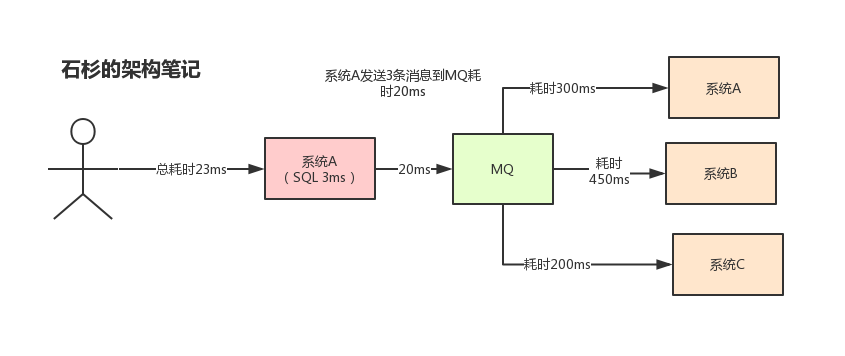
可以看到在这种情况下,系统会将整个系统需要执行的部分在后端利用消息队列进行通知,而对客户只要返回结果就好。那么会大大提高接口的性能。
2.2 解耦
假设 A 系统在用户发生某个操作的时候,需要把用户提交的数据同时推送到 B,C两个系统,如果通过 Http 或者 RPC 接口进行操作的时候,会是下面的这种模式:
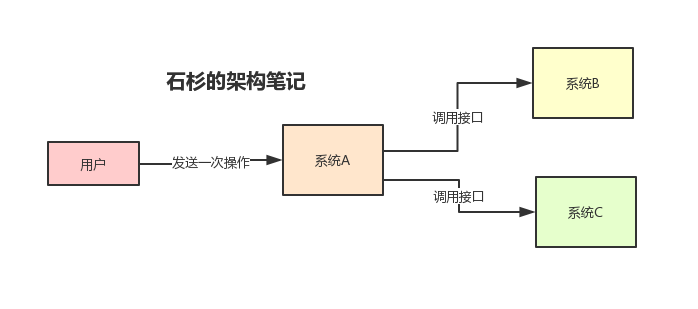
这种模式的确简单美好,但是业务如果发生迭代,多了几个系统也要这个数据,我们拿D,E,F举例,那么就需要修改源代码,将数据也传给其他几个系统。
这种纯粹增加系统的场景还好,如果有多种操作,例如还有其他数据要发送给某几个系统C,D,E,或者某些场景D又不需要这个数据了,那么应对多种系统之间的业务调整会让开发人员陷入一种非常被动的境地。
而且上面提及的这些部分也只是说增加或者减少系统的情况,如果还有其他要求,例如重试,超时等等情况,那么代码的复杂程度会急剧增加,对整个开发过程极其不利。
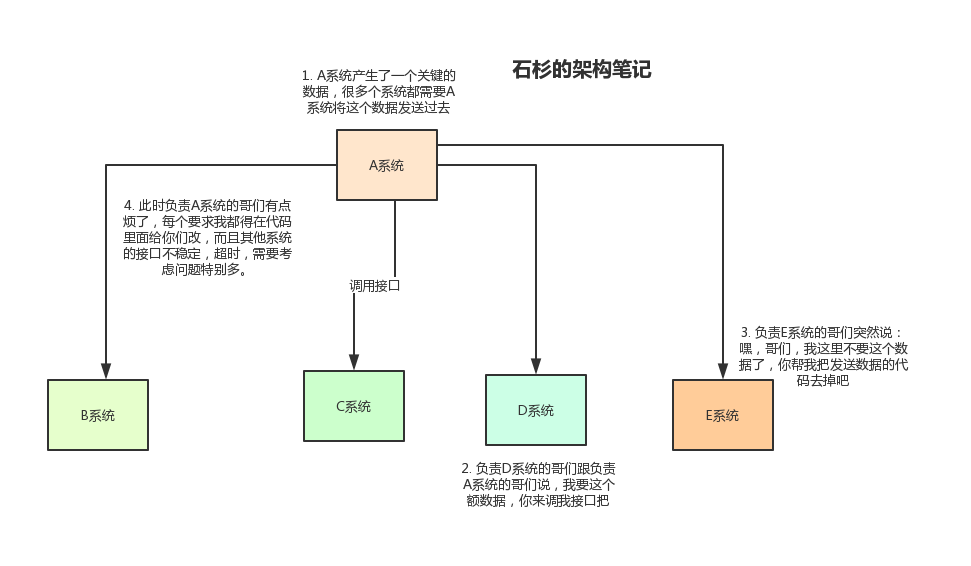
这种情况下,非常适合利用 MQ 来进行解耦,这样负责 A 系统的开发者只需要将消息传到 MQ 之中,其他系统来订阅消息就好。就算某个系统不需要,或者某个系统突然需要这个数据,也不需要A 系统来改动任何代码。
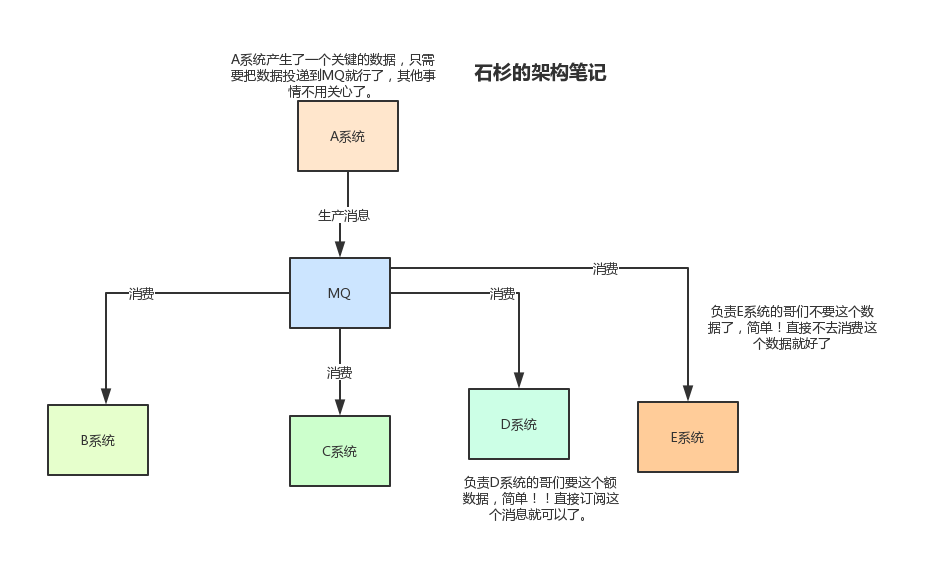
2.3 削峰填谷
比如某些订单系统,下单的时候会向数据库之中写入数据,但是数据库只能支持一定量,比如 每秒1000次 左右的并发写入,并发量再高就会死机。但是数据总是有高峰和低谷的情况出现,可能平时的写入量只有 每秒100次 左右,但是高峰期是 每秒5000次。那么数据库会直接 down 掉,一点挣扎都不会有的,就像这样:
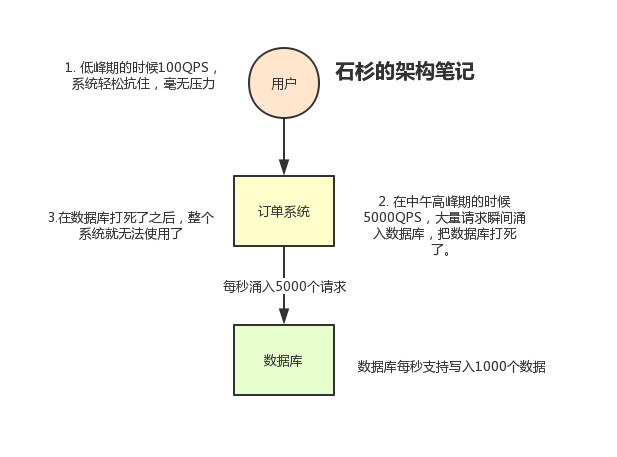
但是如果使用了 MQ 之后,消息可以被 MQ 保存起来,那么系统可以按照自己的能力来进行消费,比如 每秒1000个 数据,这样慢慢写入数据库,就不会一下子将数据库打死了:
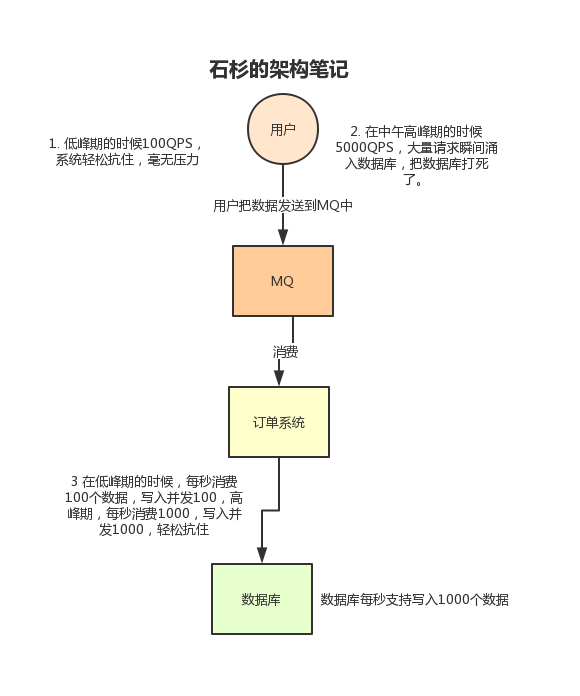
削峰填谷的由来请看下图:
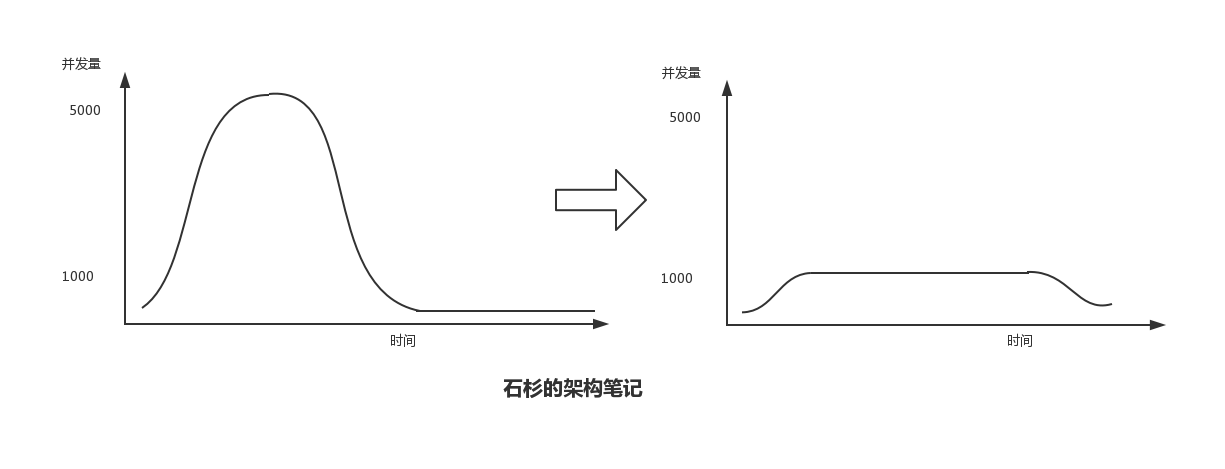
像我们之前提到过的,业务量总有高峰和低谷,那么在高峰的时候系统容量不够,在低谷的时候系统性能又没有被完全利用。没有使用 MQ 的情况之下,并发量高峰期是有一个顶峰的,在高峰期过后又是一个低并发的谷。
但是使用了 MQ 之后,限制消费信息的速度为 1000, 这样一来,高峰期产生的数据可以暂时先压在 MQ 之中,在高峰期过了之后,数据库可以依旧以 1000次/ 秒 的速度继续进行数据处理。直到将所有积压的信息全部消费完成,这就是“填谷”。
3. 使用 MQ 的缺点
上面讲了这么多 MQ 的优点,下面来谈谈 MQ 的缺点,毕竟不可能有完美的事物,MQ 相当于在系统之中引入了另外一个组成部分,对原有的架构一定会有影响。
3.1 系统可用性降低
拿上面提到过的解耦举例子,本来 A 系统要将关键数据发送给系统 B 和 系统 C,突然加入一个 MQ,那么如果 MQ down 了该怎么办?这就引入了 系统稳定性 的问题,加入了 MQ 之后,系统不稳定的变量是不是增加了? 只要 MQ 挂掉了,数据没有了,系统运行就不对了。
3.2 系统复杂度提高
有人会问了,你前面不是说 MQ 可以降低复杂度吗?这就得注意看前面了,之前提到的,是对于开发人员来说,系统的维护成本复杂度变低了。但是对于整个系统而言,本来调用一下接口就可以的事情,在加入 MQ 之后,又要考虑 消息重复消费 , 消息丢失 ,甚至 消息顺序性 的问题,为了解决这些问题,又要引入很多机制,这下是不是系统的复杂度提高了?
3.3 数据一致性问题
在之前的系统之中,由于系统 A 和 系统 B,C 是相互耦合的关系,那么如果 B,C 系统出错了,可以抛出异常返回到 A 系统,让 A 系统知道其有错误,从而进行回滚操作。但是在使用 MQ 之后,A系统将消息发送到消息队列之后就认为已经成功了,但是万一刚好系统 C 在写数据库的时候发现已经失败了,但是 A 并不知道,以为 C 写数据库成功了怎么办?
4. 怎么保证 MQ 消息不丢失
使用了 MQ 之后,还要关心消息丢失的问题。下文举例皆是 RabbitMQ
4.1 生产者弄丢了数据
RabbitMQ 生产者将数据发送到 RabbitMQ 的时候,如果数据在网络传输之中丢了,此时 RabbitMQ 收不到消息,那么消息就丢了。
RabbitMQ 提供了两种方式来解决:
事务方式:
在生产者发送消息之前,通过 channel.txSelect 开启一个事务,接着再发送消息。如果消息没有成功被 RabbitMQ 接收到,那么生产者会接收到异常。此时就可以进行事务回滚 channel.txRollback 然后重新发送。假如 RabbitMQ 收到了这个消息,就可以提交事务 channel.txCommit。
但是缺点是这样一来,生产者的吞吐量和性能都会非常大的降低,因为每次传输消息之前都需要进行事务的开启等等。下面是另一种方式:
confirm 机制:
confirm 机制是在 生产者 这里设置的。其具体操作是:每次写消息的时候会分配一个唯一的 ID,当 RabbitMQ 收到之后会回传一个 ACK, 告诉生产者这个消息已经被成功收到。看到这里大家是不是觉得似曾相识?没错,就是 TCP 的 ACK 机制,其原理是相同的。有时候觉得也很有趣,网络协议之中的传输也是相似,并不能保证其传递结果是 100% 正确的,与 RabbitMQ 之中的情况极其类似,那么借鉴过来是很聪明的做法。
那么如果 RabbitMQ 没有收到这个消息,那么就回调一个 nack 的接口,这个时候生产者就可以重发。
事务机制和 confirm 机制的最大不同点在于,事务机制是同步的,提交一个事务之后,会直接阻塞在那里。但是 confirm 机制是异步的,发送一个之后可以接着发送下一个消息(和 TCP 之中一样,不可能等待回传结束之后再发送下一个报文), 消息在 RabbitMQ 收到之后会异步回调一个接口,告诉这个消息已经收到了。
所以相对而言,在 生产者 这里避免数据丢失,一般是使用 confirm 机制。
4.2 RabbitMQ 弄丢了数据
RabbitMQ 集群也会弄丢东西,这个问题在官方教程之中也提到过,就是万一当消息发送到 RabbitMQ 之后,在默认没有落地磁盘的情况下,一旦 RabbitMQ 宕机,那么消息就会丢失。
为了防止这种情况的出现, RabbitMQ 提供了一个持久化的机制,消息在写入之后,会持久化到磁盘,这样哪怕宕机,恢复之后也会自动恢复之前存储的数据,这样就可以确保消息不会丢失。
设置持久化的步骤:
-
第一个是创建
queue的时候,将其设置为 持久化 的,这样的情况可以保证 RabbitMQ 持久化 queue 的元数据,但是不会持久化 queue 里面的数据。个人理解,其意思为 持久化 queue 的设置数据,但是不会持久化 queue 之中包含的 message 元素。A queue is the name for a post box which lives inside RabbitMQ. Although messages flow through RabbitMQ and your applications, they can only be stored inside a queue. A queue is only bound by the host’s memory & disk limits, it’s essentially a large message buffer. Many producers can send messages that go to one queue, and many consumers can try to receive data from one queue. This is how we represent a queue:

Queue元数据:队列的名称和声明队列时设置的属性(是否持久化、是否自动删除、队列所属的节点) Exchange元数据:交换机的名称、类型、属性(是否持久化等) Bindding元数据:一张简单的表格展示了如何将消息路由到队列。包含的列有 Exchange名称、Exchange类型、routing_key、queue_name等 vhost元数据:为vhost内队列、交换机和绑定提供命名空间和安全属性
-
第二个,是发送消息的时候,将 deliveryMode 设置为 2, 这样做就是将消息设置为 持久化 的,此时 RabbitMQ 就会将消息持久化到磁盘上面去。
要是还有人会问,万一消息发送到 RabbitMQ 之后,还没来得及持久化,磁盘就挂掉了(虽然这种情况非常少见),数据也丢失了,那么怎么办?
对于这个问题,其实是配合上面的 confirm 机制一起来保证的,就是当 消息持久化到磁盘 之后,才会给生产者发送 ACK 消息。万一真的特别极端的情况,生产者是可以感知到的,此时可以通过重试发送消息给其他的 RabbitMQ 节点。
4.3 消费端弄丢了数据
RabbitMQ 消费端弄丢了数据的情况如下:
在消费消息的时候,刚拿到消息,结果进程挂了,这时候 RabbitMQ 会认为你已经消费消息成功了,这条数据就弄丢了。
首先讲一下 RabbitMQ 的消费消息的机制: 在消费者收到消息的时候,会发送一个 ACK 给 RabbitMQ ,告诉 RabbitMQ 这条消息被消费到了,这样 RabbitMQ 就会把消息删除。
默认情况下,这个发送 ACK 的操作是自动提交的,也就是说消费者一旦收到这个消息就会自动返回 ACK 给 RabbitMQ,所以出现丢消息的问题。
针对这个问题的解决方案就是: 关闭 RabbitMQ 消费者的自动提交 ACK ,改成在消费者处理完这条消息之后,再手动提交 ACK。这样,哪怕遇到上面的情况,RabbitMQ 也不会将这条消息删除,在程序重启恢复之后,会重新发这条消息过来。
5. 怎么保证 MQ 的高可用性?
使用了 MQ 之后,肯定是希望 MQ 有高可用性,因为不可能接受机器只要宕机了,就无法收发消息的情况。
RabbitMQ 是比较有代表性的,因为基于 主从结构 做高可用性的,就以其为例子,讲一下第一种 MQ 的高可用性如何实现。
RabbitMQ 有三种模式:单机模式,普通集群模式,镜像集群模式。
单机模式:
单机模式就是 demo, 只有一台机器部署了一个 RabbitMQ 程序。这个一般只适用于本地玩玩,生产条件下没法使用单机模式。
普通集群模式:
这个模式代表着:在多台机器上面启动多个 Rabbit MQ 实例,类似 master-slave, 但是创建的 queue 只会放在一个 master RabbitMQ 实例上,其他实例都同步那个接收消息的 RabbitMQ 元数据。
在消费消息的时候,如果连接到的 RabbitMQ 实例不是存放 Queue 数据的实例,而只有 queue 的元数据的话,RabbitMQ 会从存放 Queue 数据的实例上面拉取数据,然后返回给客户端。
总的而言,这种方式并没有做到真正的分布式,每次消费者连接一个实例之后,拉取数据,如果连接到不是存放 queue 数据的实例,那么会造成额外的性能开销(要去那个具有数据的实例拉取数据),如果从存放 Queue 的实例拉取数据,会导致单实例性能瓶颈。
而且这种做法也无法应对宕机:如果存放 queue 的实例宕机了,会导致其他实例无法拉取数据,那么 整个集群 都无法消费信息了,没有做到真正的高可用。
所以这种模式其实根本没有所谓的”高可用“ 而言,只是主要用于提高吞吐量,即让集群之中多个节点服务于 同一个queue 的读写操作。
镜像集群模式:
镜像集群模式,才是真正的 RabbitMQ 高可用模式。和普通集群不同的是,创建的 queue ,无论是元数据,还是 queue 里面的消息,都会存在于多个实例之上,每次写消息到 queue 的时候,都会自动将消息到多个实例的 queue 之中进行消息同步。
世间并无万全法,这种模式的缺点在于:
- 性能开销过高:消息需要同步所有机器,会导致网络带宽的压力和消耗很重。
- 扩展性低:无法解决某个
queue数据量特别大的情况,导致queue无法线性扩展。就算机器的个数增加,增加的机器上面也是包含着queue的所有数据,queue的数据并没有做到分布式存储。
一般做法是开启 镜像集群模式, 这样至少做到了高可用。
6. 总结
通过本篇文章,分析了对于 MQ 的一些常规问题:
- 为什么使用 MQ?
- 使用 MQ 有什么优缺点
- 如何保证消息不丢失
- 如何保证 MQ 高可用性
本文仅仅是针对 RabbitMQ 的场景举例子。还有其他比较的消息队列,比如 RocketMQ、Kafka,不同的 MQ 在面临上述问题的时候,要根据他们的原理机制来做对应的处理。
7. 各种 MQ 的性能比较
此处引用 https://github.com/doocs/advanced-java/blob/master/docs/high-concurrency/why-mq.md 的文章
Kafka、ActiveMQ、RabbitMQ、RocketMQ 有什么优缺点?
| 特性 | ActiveMQ | RabbitMQ | RocketMQ | Kafka |
|---|---|---|---|---|
| 单机吞吐量 | 万级,比 RocketMQ、Kafka 低一个数量级 | 同 ActiveMQ | 10 万级,支撑高吞吐 | 10 万级,高吞吐,一般配合大数据类的系统来进行实时数据计算、日志采集等场景 |
| topic 数量对吞吐量的影响 | topic 可以达到几百/几千的级别,吞吐量会有较小幅度的下降,这是 RocketMQ 的一大优势,在同等机器下,可以支撑大量的 topic | topic 从几十到几百个时候,吞吐量会大幅度下降,在同等机器下,Kafka 尽量保证 topic 数量不要过多,如果要支撑大规模的 topic,需要增加更多的机器资源 | ||
| 时效性 | ms 级 | 微秒级,这是 RabbitMQ 的一大特点,延迟最低 | ms 级 | 延迟在 ms 级以内 |
| 可用性 | 高,基于主从架构实现高可用 | 同 ActiveMQ | 非常高,分布式架构 | 非常高,分布式,一个数据多个副本,少数机器宕机,不会丢失数据,不会导致不可用 |
| 消息可靠性 | 有较低的概率丢失数据 | 基本不丢 | 经过参数优化配置,可以做到 0 丢失 | 同 RocketMQ |
| 功能支持 | MQ 领域的功能极其完备 | 基于 erlang 开发,并发能力很强,性能极好,延时很低 | MQ 功能较为完善,还是分布式的,扩展性好 | 功能较为简单,主要支持简单的 MQ 功能,在大数据领域的实时计算以及日志采集被大规模使用 |
综上的对比之后,有以下的建议:
一般的业务如果想要引进来 MQ,最早大家使用的是 ActiveMQ, 但是由于其没有经过大规模吞吐量的验证,现在使用的不多了。
后来开始使用 RabbitMQ,但是 erlang 对于 Java 工程师有一定的难度。但是开源且社区活跃。
RocketMQ 是阿里出品,目前越来越多的系统在使用。
总结之后,中小型公司,技术实力一般,技术挑战也不是特别高,使用 RabbitMQ 是最好的选择。大型公司,基础架构研发实力比较强的,用 RocketMQ 是更好的选择。
如果在大数据领域的实时计算,日志采集等等,用 Kafka 是业内标准的,绝对没问题。社区活跃度也很高,且为全世界这个领域的事实性典范。