找到了一个超好的教程,放在下面与大家共享
https://blog.coding.net/blog/principle-of-git
学习心得
1.snapshot到底是个啥?怎么用?
在版本修改之中,并不是每一次都修改了所有文件,如果每一次commit都将所有的数据保存一遍,那么会造成很大的开销。
所以在git之中,每个文件的修改版本会单独存放,但是在每一次commit的提交记录之中,只有一个SHA-1计算之后的散列值作为其key与验证文件是否完整的凭据。这个凭据就是所谓的快照(snapshot)。在这种情况之下,在文件库之中存放的全都是完整的文件而非和上一次修改之间的增量。
而在版本控制之中,存放的都是SHA-1值,其相当于存放的是目录,按照目录去找当时的版本进行处理。
2.obj文件都有啥?好处为啥全给他?
Obj文件有四类,Blob类型存放的是项目文件的内容,相当于“文件”。
Tree是目录,其中有Blob和子Tree(子目录),从树的角度来看的话,其叶子结点就是Blob。顶层的Tree对象就是该Project的Snapshot
Commit是提交,其parent字段来引用父提交,且指向一个顶层的tree代表着整个项目的snapshot。其还包含了一些其他的信息,例如author,message等等
tag是标签,经常是给一个已经可用的版本分支的一个标记,如标记一个版本号等等。像一个项目的milestone
3.暂存区的操作
暂存区的文件是 .git/index,其为一个二进制文件,一般而言是编辑完一个就放到暂存区里面,然后再编辑下一个。不断修改之后放到暂存区,直到结束修改之后,一次commit将所有内容永久保存到 本地仓库 。
当我们提交时候,git使用这些信息来生成tree对象,再永久保存到数据库之中。这么说来,暂存区是构建snapshot的区域
4.文件状态
暂存区和本地仓库之间有比较,在工作区和暂存区之间也有比较。根据一个有一个没有,或者两个都有可以分成三类(不存在都没有的情况),那么两种比较就一共有六类。
将两种比较区分开的原因是前者会涉及到是否上传本地仓库进行永久保存,而后者不会涉及这一点。
5.分支(branch)
如果当前项目有问题或者要扩展项目怎么办?如果只是在原有的版本上面进行操作,可能会引入更多的bug,导致整个项目崩溃。
为了解决这种情况,我们引进来了分支,其在Git之中也是使用一个文件表示的,在对文件进行解析之后发现其就是一个指向某一个commit的指针。
Git之中的branch如此轻量级的原因找到了!既然只是一个对于commit的指针,那么只要提交新的commit的时候,其指向跟着更新就好了。而在创建Branch的过程中根本没有什么文件复制,或者将每次的更新计算出来,仅仅是创建一个对于commit的指针而已。
6.高层命令
高层命令=几条底层命令的叠加组合
1. Add & Commit
- Touch:新建一个文件 e.g. touch README.md
- Add: 将操作保存到暂存区
- Commit:将暂存区的内容保存到本地仓库
2. Conflicts & Merge & Rebase
1. 什么是Confilict?
在创建branch的时候,某一个文件可能在许多不同分支都做了修改,添加或者删除。这种情况下就会产生conflict
如果我们想要将不同分支合并起来应该怎么做? 那就要看看该文件的改动状况,根据其改动状况进行自动Merge或者手动Merge了
若是其在Branch 1 之中没有修改,但是在Branch 2 之中有修改,那么自动的Merge就会将Branch 2 的修改过后的文件为准。若是同一个文件在Merge Base( 两个Branch的分岔点) 和Branch 1, Branch 2 之中都有修改,那么此时就需要手动Merge了,Git会将这个文件标注出来,此时需要讨论之后手动Merge
问题又来了:万一Branch 1 之中的文件A需要文件B来执行,但是在Branch 2之中文件B被删除掉了,那么在Merge之后系统会自动删除文件B,这样整个程序不就崩溃了吗?
答:不可能。为什么?首先我们假定每次Commit的都是经过测试的可用分支。(故意捣乱谁遭得住啊),那么在Branch 2之中,其commit 的版本是可用的,且文件A没有经过修改,说明文件A不需要文件B就可以运行。这样合并之后自动删除文件B的Merge后的分支也一定可用。
2. Rebase
Rebase是将之后的Branch的所有改动放到Master的branch之后。其相当于将新的Branch的所有改动一步步改到Master这个Branch的最后端,相当于将Base点从Master和Branch的分歧点改到了Master的最后一个Commit之上,因此称为Rebase。
个人不建议这么做。因为这样最后收获的是一个线性的Master分支,但是在上面我们所说的那个删除依赖的问题不能解决。
3. Checkout,revert,Reset
1. Checkout
Checkout用来切换分支,或者切换到某一次提交,Checkout的状态修改是修改HEAD指针的指向位置来做的
其并没有修改提交的历史记录,而只是将对应版本的内容提取出来
2. Revert
反向提交是也。反向提交,顾名思义,就是一个反向操作,加进去的删掉,删掉的加回来。
在分支已经推送到远程仓库的情况下尤其有用。
其并不会修改历史纪录,而是首先将上一个版本的工作代码存入工作区和缓存区,然后直接commit出去完成操作
3.Reset
Reset,按照曾经的经验也是如此,其会“清除”一些东西,实际在Git之中也是这样。
其会修改历史纪录。
与上面的Revert区别在哪呢?Revert是在原有基础之上再加入了一个新的commit,相当于是重新commit在原有的Branch之上。但是Reset是整个指针指向了之前的Commit,相当于在Branch上面做了“回退”操作。
Reset有三种区别的操作,一种是–soft, 一种是– mixed, 一种是 – hard模式。其除了在Branch上面进行操作之外,还会依次操作暂存区,操作工作区和暂存区。而当操作某个区域代码时候,就会导致某个区域的代码“消失”。
4.Stash
工作做到一半发现要切换Branch怎么办?
可以直接做一次提交,在message里面写上half of work,然后切换分支,但是这样不方便,怎么办?
这时候就看到stash的好处了:其将工作区和暂存区的内容做一个提交,然后使用reset hard恢复工作区和暂存区内容,之后可以随时使用stash apply将其修改回来。
5.bisect
一百个版本之后发现有bug怎么办?找不到bug的原因怎么办?就用它了!
原理是使用二分法来每次折中查找,这样效率极高,如果查找可以运行就对其进行标记之后再查找下一个,最后很快就可以找到最后一个可以运行的版本啦~
Basics
1.Git Commit
Git Commit是将当前目录下面的所有问额见的快照上传到Git仓库(Git Repositry)之中,且在其中记录好对于父节点的代码变化。
2.Git Branch
在理解Git的快照(snapshot)之时遇到了一些问题,其主要是不太理解其含义。 下面是一个很好的知乎回答:总而言之,快照是在已有数据基础上进行的改动记录,方便在需要修改回曾经的版本。但是若是数据损坏,在这种情况之下,快照无法做到数据恢复。试想一下,一个数据从根上就破坏掉了,记录了改变又有何用呢?
快照与备份有什么区别?快照是备份的其中一种么?还是两种不同的概念? 作者:木头龙 链接:https://www.zhihu.com/question/20374919/answer/499376887 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
一句话答案:快照是数据存储的某一时刻的状态记录;备份则是数据存储的某一个时刻的副本。这是两种完全不同的概念。先说背景知识:我们现在电脑上的数据,记录方式都是地址->数据这样存放的。例如我们最熟悉的机械硬盘,最小存储单位是扇区,老式硬盘一个扇区512字节,新式硬盘一个扇区4096字节。每个扇区都有自己的地址,现在主流的LBA寻址方式,就是从0开始,0,1,2,3,……,N这样。
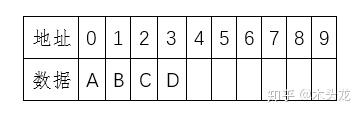
数据的物理存储当然,对于外部存储,我们一般不会这样直接存放数据,我们可能通过硬盘分区,并且格式化对应分区后存放数据,于是就变成这样的情况:
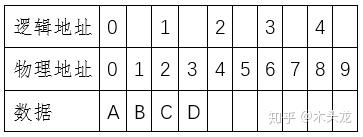
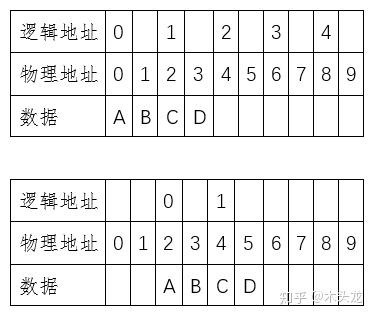
物理地址和逻辑地址例如上图,我们建立一张逻辑地址和物理地址的映射表,每个逻辑地址对应两个物理存储单元。当然,这是比较简单的情况:物理硬盘,上面有一个磁盘分区,格式化的时候一个分配单元(Windows叫“簇”)占两个扇区。复杂一点的,可能会有多层逻辑地址,例如分区上有一个虚拟磁盘文件,作为虚拟机的“物理”设备。而虚拟盘的每一个物理扇区号,其实只是虚拟磁盘文件的某个逻辑地址,又对应着文件系统的某个分配单元,同时又是物理磁盘的某个物理扇区号。也就是说可能存在多层逻辑地址,而每一层逻辑地址都会把上一层逻辑地址看做是物理地址对待,这个就不展开了。如果这个时候,我们做一个快照,快照的数据大概类似这么一个东西:
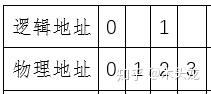
如果我们要把保存的ABCD改成AACD,在没有快照的时候,是这么一个情况
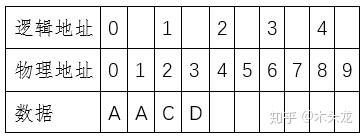
很显然,我们找不回ABCD这个数据了。而如果我们做了快照,快照地址0、1对应的物理地址[0-3]就被锁定不可更改了,结果会类似这么一个情况
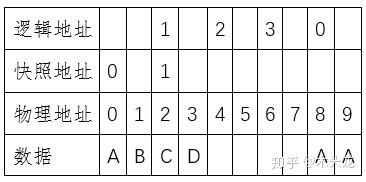
这个时候,我们按照0-1-2-3这样的逻辑地址,读取出来的就是AACD,两个空单元。按照快照地址0-1读取数据,我们就能读取到原来的ABCD了。同时,我们可以看到,原来的逻辑地址4没有了,换句话说,我们的存储空间少了一个逻辑存储单元。当然,上面这是最简单的快照。事实上,我们要考虑将来,逻辑地址1可能要从CD改成EF;将来我们需要再做快照2、快照3,更复杂的,我们可能做了快照3之后,回滚到快照1,然后继续修改数据,之后再做一个快照4……又或者这是一个虚拟硬盘文件,放入一份原始数据之后,做了一个快照;然后我们在这个基础上创建了虚拟硬盘2、3、……、N,用于存放不同逻辑的数据处理结果。这些更复杂的情况就不展开说了。一般来说,原则就是就是快照时锁定物理单元内容,并记录本次快照和上一次快照的所对应的物理地址(或者是上一层逻辑地址)的差异。上面例子中,快照完成后,物理地址0-3的数据是不可改动的。如果改写后再做第2次快照,则物理地址8-9也会锁定,同时第二次快照会记录下逻辑地址0所对应的物理地址从0改为8。因为快照仅仅记录逻辑地址和物理地址的对应关系,因此快照的速度非常快。在上面例子中,一个逻辑地址对应2个物理扇区,按照现代硬盘一个扇区4KiB,就算按照ZFS的地址宽度128bit=16Byte算,加上物理地址宽度,做一次快照的写入的数据量可能只有整体数据量的0.5%不到。而备份,则是另外一份数据副本,例如这样的
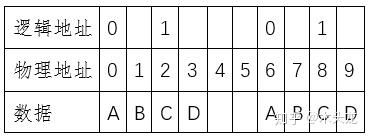
同一物理设备上的备份或者这样的:
不同物理设备上的备份另外,备份又分全量备份和增量备份,全量备份就是上面的情况了。增量备份则类似快照,但不同的地方在于两次快照之间只记录了两层地址之间的对应关系的差异,而增量备份则把这些差异中,新增地址所对应的底层数据也复制了一份出来。快照和备份的不同在于:备份的数据安全性更好:如果原始数据损坏(例如物理介质损坏,或者绕开了快照所在层的管理机制对锁定数据进行了改写),快照回滚是无法恢复出正确的数据的,而备份可以。快照的速度比备份快得多:生成快照的速度比备份速度快的多。也因为这个原因,为了回避因为备份时间带来的各种问题(例如IO占用、数据一致性等)很多备份软件是先生成快照,然后按照快照所记录的对应关系去读取底层数据来生成备份。占用空间不同:备份会占用双倍的存储空间,而快照所占用的存储空间则取决于快照的数量以及数据变动情况。极端情况下,快照可能会只占用1%不到的存储空间,也可能会占用数十倍的存储空间。(PS:不过如果同一份数据,同时做相同数量的快照和增量备份的话,备份还是会比快照占用的存储空间多得多。)最后,快照在很多地方都有使用,例如文件系统层面,ZFS、BtrFS、NTFS(MS管快照叫卷影复制,Volume Shadow copy Service,VSS)这些文件系统都提供快照功能;各种虚拟机有快照;很多关系数据库也有快照。
3.Git Rollback
在Git的操作之中,可以使用 Git checkout HEAD^ 来将其parent找出来,而无需每次都要使用log查找其Hash值