Hashmap不管是在我们日常的编程过程之中经常用于降低复杂度,在面试之中也经常被考察。
我在最近的学习过程之中也看到了一些很好的资料,包括源码解析或者宏观层面的讲解。在这里写下来自己的一些心得体会。
附上资料地址:
https://blog.csdn.net/login_sonata/article/details/76598675
https://blog.csdn.net/v123411739/article/details/78996181
Java8的HashMap详细解读
0.简介
HashMap是Java之中的java.util.map 接口的一种实现,其继承关系如下所示:
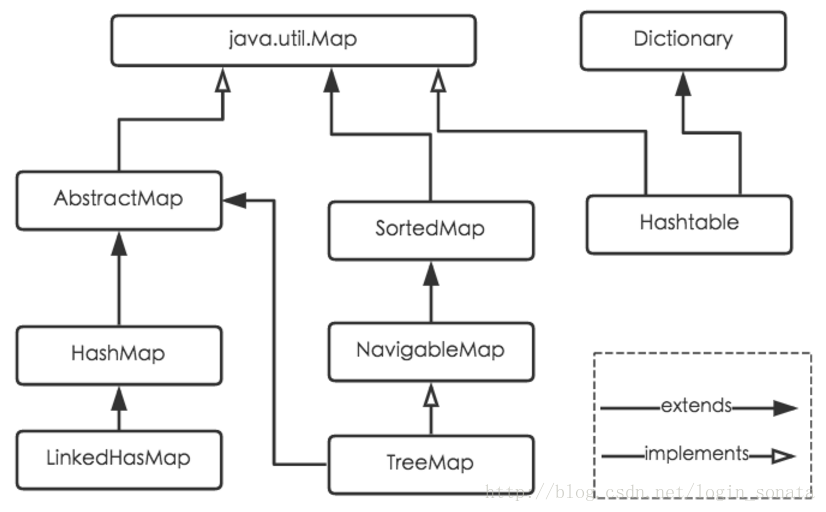
对于几个实现类的特点的一点说明:
HashMap
- 根据键的hashCode存储数据,但是其遍历数据不确定
- HashMap最多只允许一条记录的键值为null,其实其处理方式为将null的hash值处理为0,不会调用其本身的hashCode方法。而当多条键值的记录都为null的时候,会产生冲突,所以不可以。
- Hashmap是线程不安全的,统一时刻可以有几个线程一起读写HashMap,可能会导致数据的不一致。要满足线程安全,可以使用CurrentHashmap
HashTable
- HashTable继承于Dictionary类,其键和值都不可以为null
- HashTable是遗留类,不建议使用,建议用HashMap代替
- 其是线程安全的,原理为使用了Synchronized实现线程安全,但是其效率很低,并发性不如ConcurrnetHashMap
其并发性不如ConcurrentHashMap的原因在于ConcurrentHashMap引入了分段锁,分段锁可以理解为其将整个Map分成了N个Segment,在put() 和 get() 的时候,根据key.hashCode() 先找到在哪个Segment, 再在内部操作,相当于用到哪部分就锁哪部分,ConcurrentHashMap键和值都不可为null
LinkedHashMap
LinkedHashMap是HashMap的一个子类,其保存了记录的插入顺序,在使用Iterator来遍历LinkedHashMap的时候,先得到的记录是先插入的。其也可以在构造的时候加入参数,按照访问次数排序等等
TreeMap
- TreeMap底层是使用二叉树实现,其实现SortedMap 接口,可以将其保存的记录按照键的大小来排序,默认是按照键值的升序排序,也可以实现指定排序的比较器。
- 在使用TreeMap的时候,key必须实现Comparable的接口或在其中给出Comoarator,不然会抛出java.lang.ClassCastException 的异常。
对于以上这四种Map的类型,均要求映射之中的key是不可变对象,其意味着对象在创建之后其hash值不可变。如果对象的hash值可变,那么map就无法定位到映射位置了。
下面从:
- 存储结构
- 常用方法分析
- 扩容
- 安全性
讲解HashMap的工作原理。
1. 存储结构
从实现结构来看,HashMap是数组+链表+红黑树(从JDK 1.8开始)实现的,如下图所示:
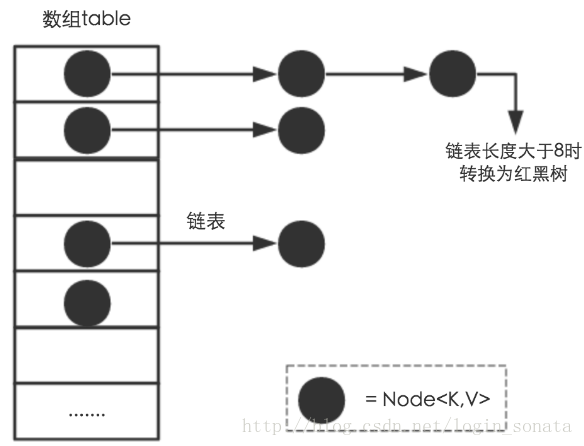
其中每一个黑点是一个最基本的存储单位,是其内部的底层类。而对于数组的每一个单元,其都有一个链表来保存hash之后相同的值的元素,且当 size>8 的时候其会转化成红黑树。
两个问题:
- 数据底层,也就是上图之中的黑点,到底存储的是什么?
- 这样的存储方式优势在哪?
下面是上面两个问题的回答:
HashMap之中有一个非常重要的字段,其为Node[] table,就是哈希桶数组。那么这个Node 类就是我们上面提到过的“ 黑点 ” 的本质。
static class Node<K,V> implements Map.Entry<K,V> {
final int hash; //用来定位数组索引位置
final K key;
V value;
Node<K,V> next; //链表的下一个node
Node(int hash, K key, V value, Node<K,V> next) { ... }
public final K getKey(){ ... }
public final V getValue() { ... }
public final String toString() { ... }
public final int hashCode() { ... }
public final V setValue(V newValue) { ... }
public final boolean equals(Object o) { ... }
}
其中 Node 是HashMap 的一个内部类,可见例如 getKey() ,getValue()等等,其实现了 Map.Entry 的接口。
其中final int hash和final K key 都是final修饰,其不可以再进一步的修改,这也和我们之前说的一旦key 产生,那么其值不可以变动相呼应。
HashMap 使用的是哈希表来存储值,哈希表为了解决冲突问题,可以采用链地址法(separate chaining) 或者是开地址法(open addressing) 来处理问题,Java 之中采用的方法是链地址法(separate chaining) 来解决这个问题。
其简而言之,就是上面的示意图之中所说的,整个数据结构是数组加链表的组合,在数组的每个元素之中都加上一个链表结构。
当数据被Hash之后,得到数组下标,将数据放在对应下标元素的联表上。比如
map.put("Google","Haiming");
系统会首先调用”Google”这个key的hashCode() 方法得到其 hashCode() 的值,然后通过 Hash 算法的后两步运算(高位运算和取模运算)来定位该键值对的存储位置。 若是几个 key 定位到了相同的位置,那么表示发生了 Hash 碰撞。
为了在空间成本和时间成本之中均衡,Hash 算法之中引入了扩容机制。
下面是 HashMap 之中的默认构造函数, 其即对下面这些字段进行初始化:
int threshold; // 扩容阈值
final float loadFactor; // 负载因子
transient int modCount; // 出现线程问题时,负责及时抛异常
transient int size; // HashMap中实际存在的Node数量
对于HashMap而言,其 Node[] table的初始化长度是16, Load factor,也即其负载因子,默认是0.75。 所以threshold=loadFactor*length,当数组之中的元素达到这个个数之后就会触发其扩容。
modCount 字段是用来记录HashMap内部结构发生变化的次数,注意这个部分之中的变化次数指的是结构发生变化,例如put了一个新的键值对,但是某个 key 所对应的 value 值被覆盖不属于结构变化。这个字段是 HashMap 的fail-fast 策略的基石,也就是在 Iterator 之中,每次都会先记录这个字段的值是多少,在迭代过程之中判断modCount和exceptedModCount 是否相等,不相等则直接抛出异常。
在HashMap之中,table的长度length大小必须为2的n次方。实际在Hash 函数的设计之中,如果其长度为素数(prime number),那么冲突的概率会更小。这里这样的设计方法主要是为了在取模和扩容时候做优化,同时减少冲突。我们后文会讲。
2.功能实现
首先对Java之中的移位计算符进行一点提及:
java中有三种移位运算符
« : 左移运算符,num « 1,相当于num乘以2
>> : 右移运算符,num » 1,相当于num除以2
>>> : 无符号右移,忽略符号位,空位都以0补齐
2.1 确定哈希桶数组索引的位置
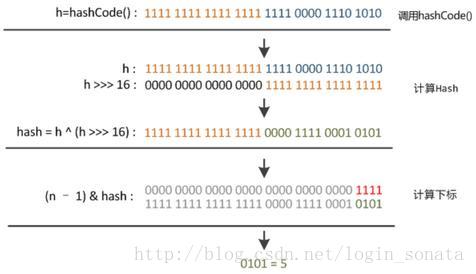
Hash 算法在此处分为三步:
(1) 取key的hashCode值,h = key.hashCode(); (2) 高位参与运算,h ^ (h »> 16); 也就是向右移16位之后做异或xor (3) 取模运算,h & (length-1)。
下面是图片说明,其中 n 为 table 的长度:
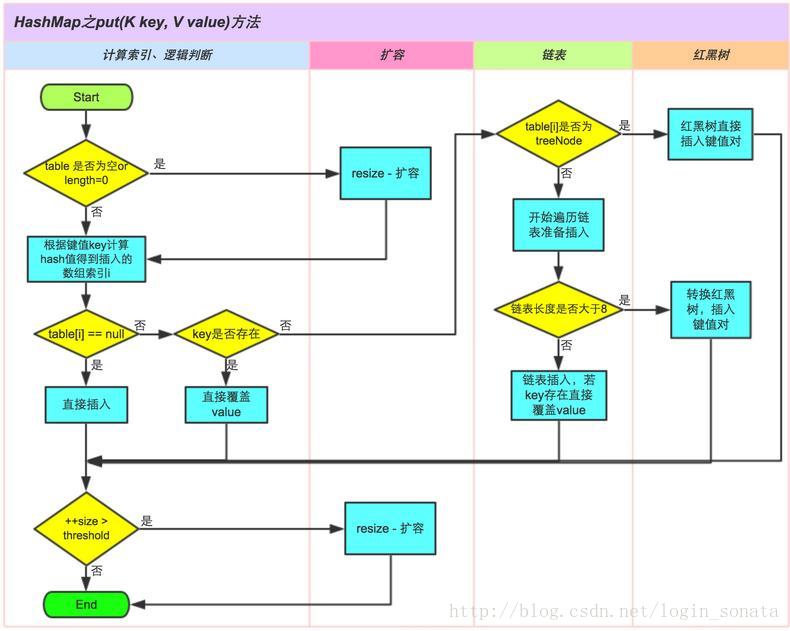
2.2 分析 HashMap 的 put 方法
个人认为其主要是分为一下几个比较大的步骤:
- 计算Hash,逻辑判断(包括key是否为null与为null之后的处理)
- 扩容
- 链表与红黑树
下面的这个图之中并没有包括key是否为null的判断,其应该位于table是否为空之后。
2.3 扩容机制
扩容机制的亮点在于:每次都扩容为之前的2倍,那么可以直接通过位运算而不需要对每一个元素执行完整的Hash计算过程。
我们使用的是2的n次幂的扩展,所以元素的位置要么是原位置,要么是原位置移动2次幂的位置。
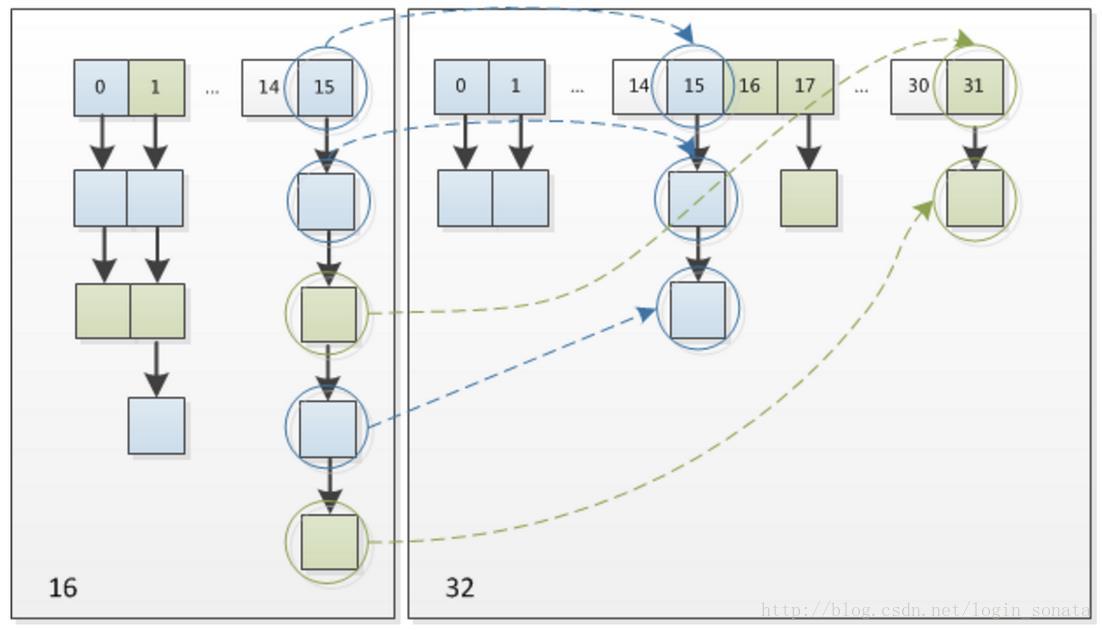
在扩充 HashMap 的时候,不需要重新计算Hash,只要看原来的hash值新增的bit是0还是1就可以,新增的bit如果为0,那么索引就不变。新增的bit为1,那么索引就变为“原索引+oldCap” 。下面是16扩展为32的resize示意:
2.4 线程安全性
HashMap 不是线程安全的,在多个线程同时put的情况下可能会造成死循环,(Infinity Loop)。
参考地址:https://coolshell.cn/articles/9606.html
多个线程同时put的时候,如果同时触发了rehash操作,那么HashMap之中会出现循环节点,进而使得后面的get出出现死循环。这种情况之下应该使用 CurrentHashMap 进行处理。
2.5 遍历Map对象
由于java 之中所有Map的实现类都实现了 Map 接口,所以以下方法适合所有的 Map 实现:
方法1:在 for-each 之中使用 entities 来遍历
非常常见,且在大多数情况下可取的遍历方式。在键和值都需要的时候使用。
但是!!如果遍历的是一个空的map对象, for-each 循环将抛出 NullPointerException, 所以在遍历之前应该检查空引用。
Map<Integer, Integer> map = new HashMap<Integer, Integer>();
for (Map.Entry<Integer, Integer> entry : map.entrySet()) {
System.out.println("Key = " + entry.getKey() + ", Value = " + entry.getValue());
}
方法2:在for-each 循环之中遍历 keys 或者 values
如果仅仅需要map之中的键或值,可以通过 keySet() 或者 values() 来实现遍历,而不是使用 entrySet() 。
Map<Integer, Integer> map = new HashMap<Integer, Integer>();
//遍历map中的键
for (Integer key : map.keySet()) {
System.out.println("Key = " + key);
}
//遍历map中的值
for (Integer value : map.values()) {
System.out.println("Value = " + value);
}
方法3:使用 Iterator 遍历
Map<Integer, Integer> map = new HashMap<Integer, Integer>();
// 使用泛型
Iterator<Map.Entry<Integer, Integer>> entries = map.entrySet().iterator();
while (entries.hasNext()) {
Map.Entry<Integer, Integer> entry = entries.next();
System.out.println("Key = " + entry.getKey() + ", Value = " + entry.getValue());
}
- 在老版本java 之中,这是唯一一种遍历 Map 的方式。
- 可以在遍历时候使用
iterator.remove()来删除,但是另外两个方法则不可以。
小结
HashMap是如何工作的?
HashMap在Map.Entry静态内部类实现中存储key-value对。HashMap使用哈希算法,在put和get方法中,它使用hashCode()和equals()方法。当我们通过传递key-value对调用put方法的时候,HashMap使用Key hashCode()和哈希算法来找出存储key-value对的索引。Entry存储在LinkedList中,所以如果存在entry,它使用equals()方法来检查传递的key是否已经存在,如果存在,它会覆盖value,如果不存在,它会创建一个新的entry然后保存。当我们通过传递key调用get方法时,它再次使用hashCode()来找到数组中的索引,然后使用equals()方法找出正确的Entry,然后返回它的值。