针对一些问题做一下梳理。
1. 操作系统和网络
1.1 进程和线程有什么区别?
进程(process) 和线程(thread) 之间的区别为:
一个程序下至少有一个进程,一个进程下至少有一个线程。
一个 process 也可以有多个 thread 来加快程序的执行速度
1.2 进程(process) 之间有哪些通信方式?
参考:https://www.jianshu.com/p/c1015f5ffa74
每个进程都有各自不同的用户地址空间,任何一个进程的全局变量在另一个进程之中都看不到,因此进程之间的交换数据必须通过内核,在内核之中开辟一块缓冲区,进程1将数据放入缓冲区之中,进程2将数据从内核缓冲区之中读走。
内核提供的这种机制叫做进程间通信,(IPC, Inter Process Communication)
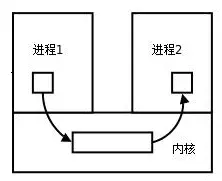
1.2.1 管道/匿名管道(pipe)
-
pipe 是半双工的,数据只可以往一个方向流动。
需要双方通信的时候,要建立起两个管道。
-
只可以用于父子进程或者兄弟进程之间(需要进程之间具有亲缘关系)
-
单独构成一种独立的文件系统:管道对于管道两端的进程而言,就是一个文件。但其不是普通文件,也不属于某种文件系统,而是自立门户,单独构成一种文件系统,且只存在于内存中。
-
数据的读取和写入:一个进程向管道之中写的内容被管道另一端的进程读出,写入的内容每次都添加在管道缓冲区的末尾,而且每次都从缓冲区的头部读数据(FIFO)
管道的实质
管道的实质是一个内核缓冲区(Kernel buffer),进程使用先进先出的方式从缓冲区之中读取数据。
这个 Kernel Buffer 可以看作是一个循环队列,读和写的位置都是自动增长的,不可以随意改变。一个数据只可以被读一次,之后此数据便不会在缓冲区之中存在。
当缓冲区读空或者写满的时候,有一定的规则控制读进程或者写进程进入等待队列。
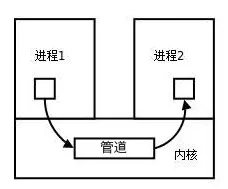
1.2.2 有名管道(FIFO)
在 1.2.1 节之中所提到的是匿名管道,匿名管道由于没有名字,只可以用于亲缘关系的进程之间通信。
为了客服这个缺点,提出了有名管道。
有名管道和匿名管道之间的区别在于:
有名管道提出了一个路径名与之关联,以有名管道的文件形式存在于文件系统之中。
即使有名管道的创建进程不存在亲缘关系,只要可以访问此路径,就能够彼此通过有名管道进行相互通信。
有名管道的名字存在于文件系统之中,内容存放在内存之中。
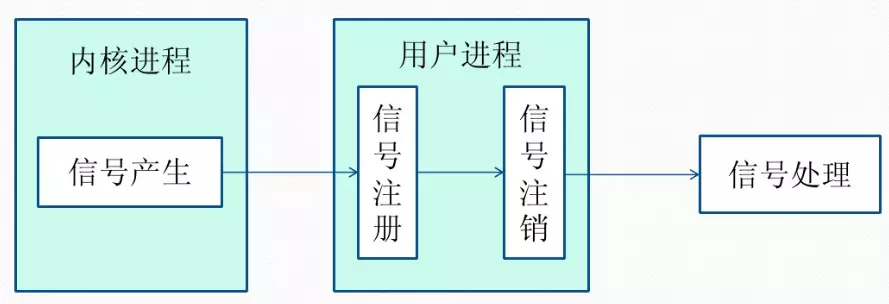
1.2.3 信号(Signal)
- 信号是 Linux 系统之中用于进程之间相互通信或者操作的一种机制。信号可以在任何时候发送给某一个进程,而无需知道对方进程的状态
- 若该进程当前未处于执行状态,则该信号就由内核(kernel)先保存起来,直到该进程回复执行并且传递给他为止。
- 如果一个信号被进程设置为阻塞,则该信号的传递被延迟,直至该阻塞(Block) 被取消才被传递给进程。
Linux系统中常用信号: (1)SIGHUP:用户从终端注销,所有已启动进程都将收到该进程。系统缺省状态下对该信号的处理是终止进程。 (2)SIGINT:程序终止信号。程序运行过程中,按
Ctrl+C键将产生该信号。 (3)SIGQUIT:程序退出信号。程序运行过程中,按Ctrl+\\键将产生该信号。 (4)SIGBUS和SIGSEGV:进程访问非法地址。 (5)SIGFPE:运算中出现致命错误,如除零操作、数据溢出等。 (6)SIGKILL:用户终止进程执行信号。shell下执行kill -9发送该信号。 (7)SIGTERM:结束进程信号。shell下执行kill 进程pid发送该信号。 (8)SIGALRM:定时器信号。 (9)SIGCLD:子进程退出信号。如果其父进程没有忽略该信号也没有处理该信号,则子进程退出后将形成僵尸进程。
信号来源
信号是软件层次上面对中断机制的一种模拟,是一种异步通信的模式。
信号可以在用户空间进程(process)和内核(Kernel)之间直接交互,内核可以利用信号来通知用户空间的进程发生了哪些系统事件,信号事件主要有两个来源:
- 硬件来源:用户按键输入
ctrl+c退出,硬件异常,如无效的存储访问等。 - 软件终止:终止进程信号,其他进程调用 kill 函数,软件异常产生信号
信号生命周期和处理流程
- 信号被某个进程产生,并设置此信号传递的对象(一般为对应进程的 pid ),然后传递给操作系统。
- 操作系统根据接收进程的设置(是否阻塞)选择性的发送给接收者
- 接收者接受信号后,根据当前进程对此信号设置的预处理方式,暂时终止当前代码的执行,保护上下文,执行中断服务程序。
1.2.4 消息(Message) 队列
- 消息队列是存放在内核之中的消息链表,每个消息队列由消息队列标识符表示。
- 和管道(pipe)不同的是(无名管道:只存在内核之中的文件;命名管道:存在于实际的磁盘介质或者文件系统),消息队列存放在内核之中,只有当内核重启(OS 重启)或者显式的删除一个消息队列的时候,该消息队列才会被真正的删除。
- 与管道不同,消息队列在某一个进程往队列写入消息之前,并不需要某个进程在该队列上等待消息的到达。
消息队列特点总结:
消息队列是消息的链表,具有特定的格式,存放在内核之中并且由消息队列标识符标识
消息队列允许一个或多个进程向其写入或者读取消息。
消息队列可以实现消息的随机查询,消息不一定要按照FIFO的次序,也可以按照消息的类型读取。
目前有两种主要的消息队列:POSIX 消息队列和 System V 消息队列。
被广泛使用的是 System V 消息队列,其为随内核持续的,只有当内核重启或者人工删除的时候,消息队列才会被删除。
1.2.5 共享内存(shared memory)
-
多个内存可以直接读写同一块内存空间,是最快的 IPC 形式。
针对其他通信机制运行效率较低设计的。
-
为了多个进程之间交换信息,内核专门留出了一块内存区,可以由需要访问的进程将其映射到自己的私有地址空间,进程可以直接读写这一块内存而不需要进行数据的拷贝,提高效率。
-
由于多个进程共享一块内存,需要依靠某种同步机制(如信号量)来达到进程之间的同步或者互斥。
1.2.6 信号量(semaphore)
参照:https://blog.csdn.net/ljianhui/article/details/10243617
一、什么是信号量
为了防止出现多个程序同时访问一个共享资源引发的一系列问题,我们需要一种方法,可以让一个时间内只有一个执行线程访问代码的临界区域。(临界区域:执行数据更新的代码需要独占式的进行)。而信号量就可以提供这样的一种访问机制。
信号量是一个特殊的变量:
- 程序对其只可以进行原子操作
- 程序对信号量只可以进行等待(即P)和发送(即V)操作。
最简单的信号量是只可以取0或1的信号量,叫二进制信号量(Binary semaphore)。可以取多个正整数的信号量成为通用信号量。
二、信号量的工作原理
由于信号量只可以进行两种操作:等待(P)和发送(V):
- P(sv):如果 sv 的值大于0,就减一;如果值为0,就挂起该进程的执行
- V(sv):如果有其他进程因为等待 sv 而被挂起,就让它恢复运行;如果没有进程等待 sv 而被挂起,就+1
例子:两个进程共享信号量 sv, 一旦一个进程执行了 P(sv)操作,其将得到信号量,并且可以进入临界区,使 sv 减一。而第二个进程将被阻止进入临界区,因为其执行P(sv) 时,信号量 sv =0,所以其会被挂起。
当第一个进程离开临界区域之后,执行V(sv)释放信号量,这时候第二个进程就可以恢复执行。
1.2.7 套接字(socket)
套接字是一种通信机制,其作用为让不在一台计算机但是通过网络连接计算机上的进程进行通信。
套接字特性
套接字的特性由三个属性确定:
- 域(field)
- 端口号(port number)
- 协议类型(protocol)
1.域
指定套接字通信之中使用的网络介质,最常见的有两种:
- AF_INET 指的是 internet 网络
- AF_UNIX 指的是 UNIX 文件系统
2.端口号
没错,和TCP/IP 里面的端口号是一个东西,一点区别没有。
16 位无符号整数,范围0-65535。
3.套接字协议类型
Internet 提供三种通信机制(对于字节流和报文的概念的不同下面有梳理):
1.流套接字
流,也就是字节流,是和TCP 相关的。所以这部分使用的是 TCP/IP 连接实现。
流套接字的优点,也是 TCP/IP 的优点:面向连接,可靠,等等。
2.数据报套接字
数据报,也就是面向报文的传输方式,自然是通过 UDP/IP 连接实现。
那么数据报套接字的优点和缺点就也和 UDP 的优点和缺点相似:其传输的速度更快,但是不保证对方收到。也不保证报文顺序。
3. 原始套接字
原始套接字的层次比上面提到的,面向 TCP 和 UDP 协议的两个都要低。
其甚至可以对 ICMP 或者 IP 协议进行直接操作,通常不用于业务数据的传输,而是用于访问配置的新设备,或者是检验新的协议实现。
1.3 TCP和UDP的区别
TCP 和 UDP 是 OSI 模型之中的传输层的协议。 TCP 提供可靠的通信传输,而 UDP 常常用于广播或者细节控制交给应用的通信传输。
二者的区别如下:
- TCP 面向连接(三次握手四次挥手),UDP 面向非连接,即发送之前不需要建立连接(随缘)
- TCP 提供可靠的服务(使用滑动窗口等进行流量控制和拥塞控制),UDP 不保证(一股脑发过去就完事了)
- TCP 面向字节流,UDP 面向报文
面向字节流和面向报文的区别:
UDP 是面向报文的传输方式:
应用层交给 UDP 多长的报文, UDP 就直接发送,一次发送一个报文。因此应用程序必须选择合适的报文长度,报文太长的话 IP 层需要分片,降低效率。
TCP 是面向字节流的传输方式:
虽然应用程序和 TCP 的交互是一次一个数据块(大小不等),但是 TCP 将其看作是一连串的无结构字节流,TCP 有一个缓冲或者其他方式作为处理。
1.4 Post 和 Get 有什么区别?
参考:https://www.zhihu.com/question/28586791/answer/145424285
1. 从现象来看
Get是将请求放在 URL 之中,Post 是将请求放在 request body 之中。
所以 Get 请求的特点就是浏览器对于 URL 请求处理的特点:
- GET 后退/刷新无害,POST 会被重新提交
- GET 书签可以收藏,POST 书签不可以收藏
- GET 可以被缓存,POST 不可被缓存
- GET 对数据结构有限制,发送的时候,GET 向 URL 之中添加数据,而 URL 的长度是收到限制的(最长2048字符)。POST 没有任何限制
2. 从RFC来看
首先看与之相关的 RFC7231 之中定义的 HTTP 方法的几个性质:
- Safe:安全。这里面所指的安全是其不对服务器端(Server)进行状态的变化。
- Idempotent:幂等:执行多次和执行一次的效果是一样的
- Cacheable:可缓存:该方法是否可以被缓存:RFC 之中 GET,HEAD 和某些情况下的 POST 都是可以缓存的,但是绝大多数的浏览器实现只支持 GET 和 HEAD。
在所有的协议之中一直在强调一个事情:协议不等于实现。也就是 specification 和 implementation 的关系。
下面是 GET 的 RFC:
The GET method requests transfer of a current selected representation for the target resource. GET is the primary mechanism of information retrieval and the focus of almost all performance optimizations. Hence, when people speak of retrieving some identifiable information via HTTP, they are generally referring to making a GET request. A payload within a GET request message has no defined semantics; sending a payload body on a GET request might cause some existing implementations to reject the request.
下面是 POST 的 RFC:
The POST method requests that the target resource process the representation enclosed in the request according to the resource’s own specific semantics.
GET 的语义是请求获取指定的资源,其方法是 安全,幂等,可缓存的。
POST 的语义是请求根据负荷(报文主体)对指定的资源做出处理,其不安全,不幂等,(大部分实现)不可缓存。
2. Java
2.1 Java 内存管理由哪些组成?
https://blog.csdn.net/suifeng3051/article/details/48292193
2.1.1 JVM 内存划分
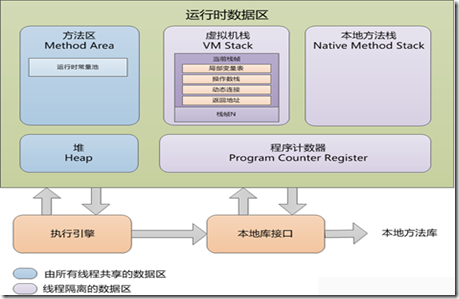
JVM 之中将内存分为了如下几个区域:
- 方法区
- 堆(heap)
- 本地方法栈
- 虚拟机栈
- 程序计数器
其中,方法区 和 堆 是所有线程共享的。
2.1.1.1方法区(Method Area)
方法区之中有:运行时常量池
方法区之中存放了:
- 要加载的类的信息:类名,修饰符等等
- 类中的静态变量(static)
- final 之中定义的常量
- 类之中的 field
- 方法信息
方法区是全局共享的。
在 HotSpot 虚拟机中(这款虚拟机是 JDK 自带的虚拟机),这部分内容对应的是 Permanent Generation(持久代),一般的,方法区上面执行的 GC 是很少的。
运行时常量池(填坑)
运行时常量池(Runtime Constant Pool) 是方法区的一部分,用于存储编译期就已经生成的字面常量,符号引用,翻译出来的直接引用等等:
- 符号引用:用字符串表示某个变量或者接口的位置。
- 直接引用:根据符号引用翻译出来的地址
2.1.1.2 堆(Heap)
在 JVM 管理的内存之中,堆是最大的一块,也是 JavaGC 机制所管理的主要内存区域。
堆由所有线程共享,在虚拟机启动时创建。
堆之中使用了分代管理方式:
年轻代(young generation)
对象在被创建时,内存首先是在年轻代进行分配(但是大对象可以直接在老年代分配)。年轻代需要回收的时候会触发 Minor GC
老年代(Old generation)
老年代的垃圾回收称作 Major GC
2.1.1.3 本地方法栈(Native Method Stack)
本地方法栈用于支持 native 方法的执行,存储了每个 native 方法调用的状态。
本地方法栈和 虚拟机方法栈 的运行机制一致,其唯一区别在于, 虚拟机是执行 Java 方法的,而本地方法栈 是用来执行 native 方法的。
2.1.1.4 程序计数器(Program Counter Register)
程序计数器是一个比较小的内存区域,可能是CPU寄存器或者 操作系统内存。
其用于指示当前线程的字节码执行到了第几行。
2.1.1.5 虚拟机栈(JVM Stack)
虚拟机栈占用的是操作系统内存,每个线程都对应着一个虚拟机栈。
一个线程的每个方法在执行的同时,都会创建一个栈帧。
栈帧之中存储的有
- 局部变量表
- 操作栈
- 动态链接
- 方法出口等。
当一个方法被调用的时候,方法入栈,方法执行完成之后,方法出栈。
2.1.2 Java 对象访问方式
一般来说,一个 Java 的引用访问涉及到三个内存区域:
- JVM 栈
- 堆(Heap)
- 方法区(Method Area)
存疑
填坑
以本地变量引用Object objRef = new Object()而言:
- Object objRef 代表着一个本地引用,存储在 JVM 栈的本地变量表之中,表示一个 reference 类型的数据
- new Object() 作为实例对象存储在堆中
- 堆中还记录了可以查询到这个 Object 对象的类型数据(接口,方法,field,对象类型),实际的数据则存放在方法区中
2.1.3 JVM 内存分配
Java 对象所占用的内存主要是在堆上面实现。因为堆为线程共享,因此当堆上分配内存的时候需要加锁。当堆上面空间不足的时候,会发生GC,GC之后空间如果仍然不足,会抛出 OutOfMemory 异常。
填坑
2.1.3.1 Young/New Generation
有两种方式:bump-the-pointer 和 TLAB(Thread-Local Allocation Buffers)
bump-the-pointer
由于Eden区是连续的,因此bump-the-pointer 就是直接跟踪最后创建的一个对象,在对象创建的时候,只需要检查最后一个对象后面是否有足够的内存即可。
TLAB
对于多线程
2.1.4 内存的回收方式
Java GC 机制,主要完成三件事:
- 确定哪些内存需要回收
- 确定什么时候需要执行GC
- 如何执行GC
JVM 主要采用 收集器 的方式来实现 GC,主要的收集器有 引用计数收集器 和 跟踪收集器
2.1.4.1 引用计数收集器
引用计数器采用分散式管理方式,通过计数器记录对象是否被引用。当计数器为0的时候,说明这个对象已经不再被使用,可以进行回收。
但是对于循环引用的场景没法实现。
填坑
2.1.4.2 跟踪收集器
跟踪收集器采用集中式的管理方式,会全局记录数据引用的状态。
主要有:
- 复制(copying)
- 标记-清除(Mark-sweep)
- 标记-压缩(Mark-Compact)
三种实现。
复制(Copying)
从根集合之中扫描出存活的对象,并且将找到的存活对象复制到一块新的完全未被使用的空间之中。
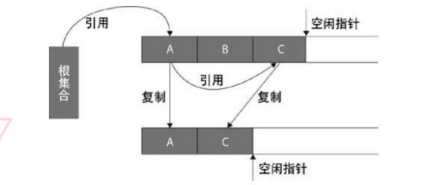
标记-清除(Mark-sweep)
其采用的方式为从根集合开始扫描,对存活的对象进行标记,标记完毕之后,再扫描未被标记的对象并删除。
会造成内存碎片
填坑
标记-压缩(Mark-Compact)
在 标记-清除 之上进行了移动规整操作,解决了内存碎片问题,但是需要对对象进行移动,其成本较高
2.1.5 虚拟机之中的GC过程
young generation 之中的几个区域被不断的对调,
2.2 哪些对象可以作为GCRoot对象?
先说一下什么是根搜索算法:
跟搜索算法是 JVM 之中用来判断对象是否存活的算法,此算法通过一系列的 “GC Roots” 对象作为起始点,从这些节点往下搜索,当一个对象和GC Root 不可达的时候,就说该对象是无用的,可以被回收的。
可以作为 GC Roots 的对象有:
- 虚拟机栈:栈帧之中的本地变量表中引用的对象
- 方法区中的类静态属性引用的对象
- 方法区中常量引用的对象
- 本地方法栈之中 JNI (java native)之中引用的对象。
2.3 HashMap 和 ConcurrentHashMap 的关系
HashMap 之前已经讲过
https://crossoverjie.top/2018/07/23/java-senior/ConcurrentHashMap/
ConcurrentHashMap:
存疑
原理上而言:ConcurrentHashMap 采用了分段锁技术,其内部组成的 Segment() 继承于 ReentrantLock。 不会像 HashTable 那样,不论是put 还是 get 操作都需要做同步处理,理论上 ConcurrentHashMap 应该支持 CurrencyLevel(Segment) 数量的线程并发(同时在每个 Segment 之上进行操作)。当一个线程占用锁访问一个 Segment 的时候,不会影响到其他的 Segment
3. MySql
3.1 在一个oracle里面一般如何优化一个 SQL?
https://www.cnblogs.com/rootq/archive/2008/11/17/1334727.html
填坑
3.1.2 WHERE 之中的子句连接顺序
ORACLE 之中采用自下而上的顺序解析 WHERE 子句,根据这个原理:
- 表之间的连接必须写在其他WHERE条件之前
- 可以过滤掉最大数量的条件必须写在 WHERE 的末尾
3.1.3 SELECT 之中避免使用 *
ORACLE 在解析的过程之中,将会把 * 依次转换成所有的列名,这个工作是通过查询字典完成的,这意味着消耗更多的时间。
3.1.4 删除重复记录
3.2 如何查看一个SQL 是否使用索引?
https://www.cnblogs.com/acm-bingzi/p/mysqlExplain.html
填坑
explain 显示了 MySql 如何使用索引来处理 select 语句以及连接表。
将 explain 放在 select 前面即可
比如:explain select * from company_info where cname like '%小%'

explain select * from company_info where cname like '小%'

type 如果是 all, 就说明其并没有使用到索引。如果是 _range ,就说明其使用到了索引。
3.3 如何创建/删除/查看一个索引?
https://www.cnblogs.com/tianhuilove/archive/2011/09/05/2167795.html
3.3.1 创建索引
在执行 CREATE_TABLE 的同时可以创建索引,也可以使用 CREATE_INDEX 或者 ALTER TABLE 来加入索引。
1. ALTER TABLE
ALTER TABLE 用于创建普通索引,UNIQUE 索引或者是 PRIMARY KEY 索引。
ALTER TABLE table_name ADD INDEX index_name(column list)
ALTER TABLE table_name ADD UNIQUE (column_list)
ALTER TABLE table_name ADD PRIMARY KEY (column_list)
2. CREATE INDEX
CREATE INDEX 可以用于对表增加普通索引或者UNIQUE 索引
CREATE INDEX index_name ON table_name(column_list)
CREATE UNIQUE INDEX index_name ON table_name(column_list)
3.3.2 删除索引
可以利用 ALTER_TABLE 或者 DROP INDEX 语句来删除索引。类似于 CREATE INDEX ,DROP INDEX 在ALTER_TABLE 内部也可以作为一条语句处理。
DROP INDDEX index_name ON table_name
ALTER TABLE table_name DROP INDEX index_name
ALTER TABLE table_name DROP PRIMARY KEY
其中,前两条语句是等价的,删除掉 table_name 之中的索引 index_name。 第三条语句之中只在删除 PRIMARY KEY 索引之中使用,因为一个 table 最多只有一个 PRIMARY_KEY 索引,因此不需要指定索引名。
如果某个表格没有 PRIMARY_KEY,但是有多个 UNIQUE 索引,MySQL 会删除掉第一个索引。
3.3.3 查看索引
SHOW index from table_name
SHOW keys from table_name
3.4 如何判断是否需要创建索引(索引的适合条件)
- 查询较为频繁的字段应该创建索引
- 唯一性太差的字段不适合单独创建索引(如状态字段,类型字段),会产生大量的随机 IO
随机 IO 的缺点在于,当下很多硬盘都是机械硬盘,所以寻道时间会比较长,大量随机 IO 比少量的顺序 IO 性能要差很多,即使后者可能查询数据稍微多一些
- 更新频繁的字段不适合创建索引。
由于作为索引的column会直接和索引的结构与数据相关,那么如果经常更新字段数据,那么就也要经常更新索引数据,这样会造成 IO 访问量较大的增加。