看到一篇文章,手把手教你构建一个高性能、高可用的大型分布式网站,其中将 大型分布式网站 的架构做了一个梳理,那就自己看着学习一下。
1. 大型网站的特点与架构目标
下面是一般的大型网站的特点:
- 用户多,分布广泛
- 大流量,高并发
- 海量数据,服务 高可用
- 安全环境恶劣,易受网络攻击
- 功能较多,迭代较快,发布比较频繁
- 从小到大,采取渐进发展的发展方式
大型网站架构目标图为:

下面是针对每一个目标的解释:
- 高性能:提供快速的访问体验,且互联网企业一般对于用户响应时间有一定的要求
- 高可用: 网站服务稳定,可以一直正常访问
- 可伸缩: 通过硬件的增加和减少,提高/降低 处理能力
- 扩展性:上一条是针对整个系统而言,那么这一条主要是针对功能而言。指的组要是可以方便的通过 新增/移除 方式,来对于 功能/模块 进行增加或者删除。对应的是上面 ”功能较多,迭代较快“。
- 安全性: 提供网站的安全访问和数据加密,安全存储等等策略
- 敏捷性:随需求应变,快速响应
2. 大型网站的架构模式
那么可以满足上面要求的大型网站的架构模式一般如下:
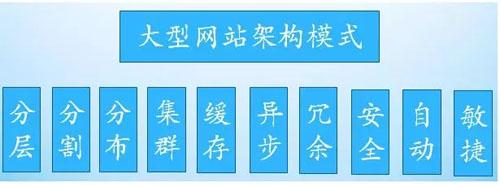
下面是针对大型网站的架构模式的分点解释:
- 分层:一般而言,都会将业务分层。业务一般可以分为 应用层,服务层, 数据层, 管理层 和 分析层。分层结构可以更好维护
- 分割: 一般按照 业务/模块/功能 特点进行划分,比如应用层这一层分为 首页,用户中心 等等
- 分布式: 将应用分开部署(比如多台物理机或者是虚拟机),通过远程调用协调工作。分布式可以降低因为单点故障整个服务宕机的情况。
- 集群: 一个 应用/模块/功能 部署多份,通过负载均衡共同提供对外访问。可以降低因为单点故障整个服务宕机的情况。
- 缓存:将数据放在距离应用或者用户最近的位置,加快数据的访问速度。CDN 缓存就是这样的一种,将内容放在离用户更近的地方。
- 异步:将同步的操作异步化。在客户端发出请求之后,不是等待服务端响应之后再进行下一步操作,而是等服务端处理完毕之后,使用 通知 或者 轮询 的方式告知请求方,一般指的是 请求——响应——通知 模式。
- 冗余:增加副本,提高可用性,安全性和性能。
- 安全:下面这个对于安全的定义非常有趣:对 已知问题 有有效的解决方案,对 未知/潜在 问题建立 发现和防御 机制。
- 自动化:将重复的,不需要人工参与的事情,通过工具的方式,使用机器完成。包括在 CI/CD pipeline 之中,要想业务多次快速迭代,要求就是自动化水平极高
- 敏捷性: 积极接受需求变更,,快速响应业务发展需求。程序跟着功能走。
3. ”大型网站架构目标”分点梳理
再次回到我们上面提到的 ”大型网站架构目标“,我们针对那六点要求进行分点的梳理:
3.1 高性能架构
高性能架构的主要目的是为用户提供较为快速的网页访问体验。主要参数有:
- 较短的响应时间
- 较大的并发处理能力
- 较高的吞吐量
- 稳定的性能参数
优化方向可以分为:
-
前端优化:网站业务逻辑 之前 的部分
-
浏览器优化:
-
减少 HTTP 请求数
-
使用浏览器缓存
-
启用压缩
-
CSS JS 位置(CSS 和 JS 的加载和执行会阻塞浏览器渲染)
-
JS 异步
-
减少 Cookie 传输
-
CDN 加速
-
反向代理
反向代理服务器位于机房一侧,代理网站 Web 服务器接收 HTTP 请求。不仅具有保护网站安全的作用,也可以配置缓存功能加速 Web 请求,可以将 静态内容 等等缓存在反向代理服务器上。
-
-
应用层优化:处理网站业务的服务器
- 使用缓存,异步,集群。
-
代码优化:
-
合理的架构,多线程,资源复用(对象池,线程池等等)
-
良好的数据结构
-
JVM 调优
-
单例
单例模式创建的对象可以确保 系统之中只产生一个示例, 主要好处在于省略频繁使用的对象所创建需要花费的时间,和由于 new 操作次数减少从而降低系统内存的使用频率,降低 GC 压力和缩短 GC 停顿时间
-
Cache 层面的优化(CPU内部不同 level 的 Cache 使用)
-
-
存储优化:
- 缓存,固态硬盘,光纤传输
- 优化读写,磁盘冗余
- 分布式存储(HDFS)
- NoSQL
3.2 高可用架构
大型网站要保证在任何时候都可以正常访问。因为大型网站的复杂性很高,分布式,廉价服务器,开源数据库,开源操作系统等等特点,要保证高可用是很困难的。
想要提高可用性,第一点就是从架构级别考虑。
不同层级使用的策略不同,一般采用 冗余备份 和 失效转移 解决高可用问题。
-
应用层:一般设计为无状态的。对于每次请求,使用哪一台服务器处理是没有影响的。一般采用 负载均衡 技术(需要解决 Session 在不同服务器之间的同步问题)来实现高可用。
-
服务层:
- 负载均衡
- 分级管理
- 快速失败(超时设置)
- 异步调用
- 服务降级
-
数据层:
-
冗余备份(冷备份,热备份[同步备份,异步备份],温备份)
-
失效转移(确认,转移,恢复)
数据高可用方面的著名理论是 CAP 理论,在之前的博文之中对 CAP 和 数据一致性 有说明,就不赘述了)
-
3.3 可伸缩架构
伸缩性是指在不改变原有架构设计的基础上,通过增加/减少硬件的方式,提高/降低 系统的处理能力。
- 应用层:
- 对应用进行垂直或者水平切分,然后针对单一功能进行负载均衡(DNS,HTTP,IP,链路层)
- 服务层:与应用层类似
- 数据层:
- 分库
- 分表
- NoSQL
- 常用算法 Hash
- 一致性 Hash
3.4 可扩展架构
可以方便的进行功能模块的新增/移除,提供代码/模块级别良好的可扩展性。
- 模块化,组件化:高内聚,低耦合
- 高内聚:每个模块尽可能独立的完成自己的功能,不依赖模块外部的代码
- 低耦合: 降低模块与模块之间接口的复杂程度
- 稳定接口:定义稳定的接口。在接口不变的情况下,内部结构可以变化
- 设计模式
- 消息队列:之前博文之中有讲到过,模块化的系统,通过消息队列进行狡猾,可以做到解耦。但是消息队列的引入也增加了系统的复杂性。
- 分布式服务:公用模块 服务化,提供给其他系统使用。提高可重用性,扩展性。
3.5 安全架构
对上面所提到的定义进行进一步的扩展梳理:
首先是要提高安全意识(例如不要把密码贴在显示器前面……)
安全问题包括基础设置安全,应用系统安全,数据保密安全等等。
-
基础设施安全:硬件采购,操作系统等等的安全。
-
应用系统安全:在程序开发的时候,对已知常用问题,使用正确的方式,在代码层面解决掉
-
防止跨站脚本攻击(XSS)
这篇美团的文章写的很好:https://tech.meituan.com/2018/09/27/fe-security.html
XSS 攻击主要是恶意代码未经过过滤,和网站正常的代码混合在一起,Browser 无法分辨哪些脚本是可信的,导致恶意脚本被执行。
-
注入攻击:指的是 SQL 注入攻击。
-
跨站请求伪造(CSRF)
https://zh.wikipedia.org/wiki/%E8%B7%A8%E7%AB%99%E8%AF%B7%E6%B1%82%E4%BC%AA%E9%80%A0
CSRF 和上面提到过的 XSS 相比,XSS 利用的是用户对于指定网站的信任,CSRF 利用的是 网站对 用户网页浏览器 的信任。
假如一家银行用以运行转账操作的URL地址如下: http://www.examplebank.com/withdraw?account=AccoutName&amount=1000&for=PayeeName
那么,一个恶意攻击者可以在另一个网站上放置如下代码:
<img src="http://www.examplebank.com/withdraw?account=Alice&amount=1000&for=Badman">如果有账户名为Alice的用户访问了恶意站点,而她之前刚访问过银行不久,登录信息尚未过期,那么她就会损失1000资金。
-
HTML 注释
https://www.owasp.org/index.php/Comment_Injection_Attack 这里有一个例子:
If the attacker has the ability to manipulate queries which are sent to the database, then he’s able to inject a terminating character too. The aftermath is that the interpretation of the query will be stopped at the terminating character:
SELECT body FROM items WHERE id = $ID limit 1;Let’s assume that the attacker has sent via the GET method the following data stored in variable $ID:
"1 or 1=1; #"In the end the final query form is:
SELECT body FROM items WHERE id = 1 or 1=1; # limit 1;After the # character everything will be discarded by the database including “limit 1”, so only the last column “body” with all its records will be received as a query response.
相当于使用注释格式来屏蔽设定好了的 SQL 语句之中的某些限制条件,达到其本身的目的。
-
-
数据保密安全:
- 存储安全
- 保存安全(重要的信息加密保存)
- 传输安全
- 使用常见的加密解密算法等等
3.5 敏捷性
网站的架构设计,运维管理要适应变化,提供之前所说的 高伸缩性,高扩展性。
除了上面提到的所有要素之外,还要引入敏捷管理,敏捷开发的思想,让业务,产品,技术,运维等听一起来,随需求应变,快速响应。
4. 大型架构举例
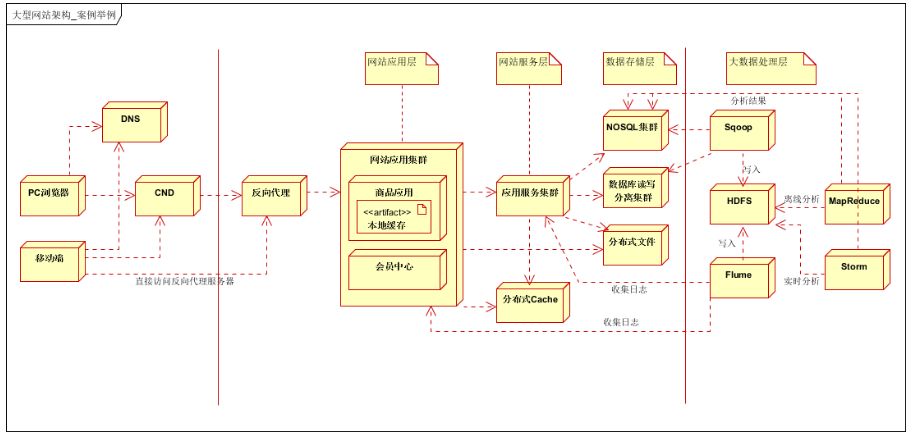
图片有点糊,下面具体介绍一下:
- 第一层:客户层。支持 PC Browser 和 手机 App。差别是 App 可以通过 IP 直接访问反向代理服务器。反向代理服务器之前提到过,就不赘述了。
- 第二层:前端层。使用 DNS 负载均衡,CDN 本地加速 和 反向代理服务
- 第三层:应用层。网站应用集群,按照业务进行垂直拆分,比如商品应用,会员中心等等不同业务划分。
- 第四层:服务层。提供公用服务,比如用户服务,订单服务,支付服务等等。
- 第五层:数据层。支持关系型数据库集群(支持读写分离),NoSQL 集群,分布式文件系统集群,以及分布式 Cache等等。
- 第六层:大数据存储层。支持应用层和服务层的日志数据手机,关系数据库和 NoSQL 数据库的结构化和半结构化数据收集
- 第七层:大数据处理层。通过 MapReduce 进行离线数据分析,或者 Storm 实时数据分析,并且将处理之后的数据存入关系型数据库。
5. 大型电商网站系统架构演变过程
真正成熟,或者正在走向成熟的大型网站的系统架构,往往不是一开始设计的时候就已经具备我们上面所说到的: 高性能, 高可用, 高伸缩 等等特性(一开始可能都是“能跑就成”),其一般都是随着用户量的增加,业务功能的扩展逐渐完善的。
成熟的系统架构会随着业务的扩展而逐步完善,并不是一蹴而就。不同业务特征的系统,更是会有各自的侧重点。
作者以 BAT 三家为例:
- 淘宝要解决海量的商品信息的 搜索,下单,支付
- 腾讯要解决数亿用户的实时消息传输
- 百度要处理海量的搜索请求
除开每个系统的不同要求,我们可以从这些不同的网站北京之中,找到其共用的技术。
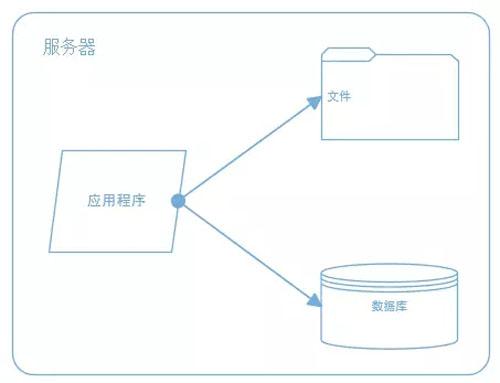
5.1 最开始的网站架构
就像自己电脑上面搭建的 Demo ,最开始的架构或许是 “All on one server”,就像:应用程序,数据库,文件等等全在一个服务器上。”能跑就行“是这个阶段的宗旨。
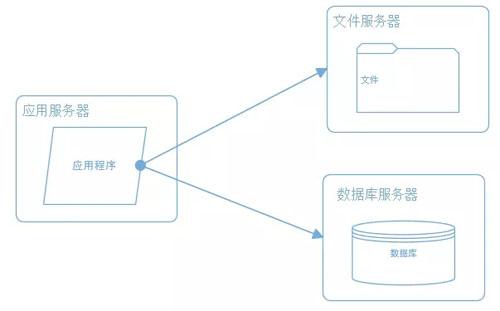
5.2 应用,数据,读写分离
随着业务的逐步扩展,一台服务器已经不能满足性能的需求,那么就多买几台,然后将前面提到过的 应用程序,数据库, 文件 各自部署在独立的服务器上,并且根据不同服务器的 不同用途配置不同的硬件,这样可以达到最佳的性能效果。
5.3 利用缓存改善网站性能
在硬件优化性能的同时,也通过软件进行性能优化,在大部分的网站系统之中,都会利用缓存技术改善系统的性能。
可以使用缓存的原因在于有 热点数据 的存在,大部分网站访问都遵循 2-8 原则,所以对于热点数据进行缓存是有意义的。
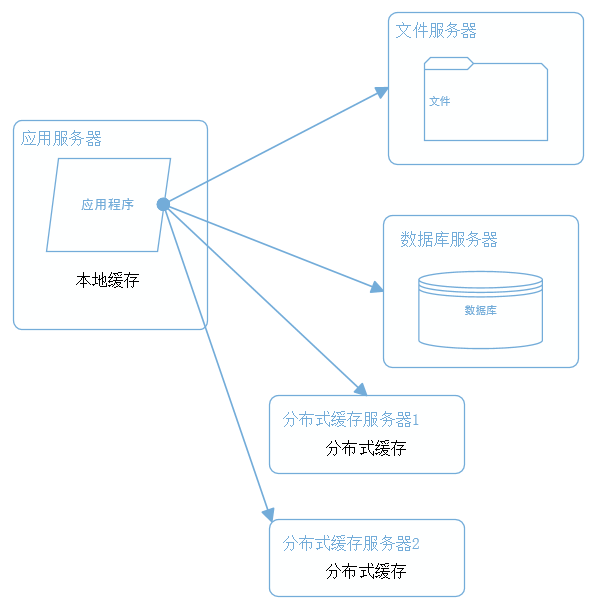
缓存常见的实现方式有:本地缓存,分布式缓存。
CDN,反向代理等等也算是一种缓存。
本地缓存,顾名思义是将数据缓存在应用服务器本地,可以存在内存之中,也可以存在文件之中。其特点是速度快,但是本地空间有限,所以缓存数量也有限。
分布式缓存 的特点是,可以缓存海量数据,且扩展较为容易。速度一般而言没有本地缓存快。常用的分布式缓存是 Redis,Memcached
5.4 使用集群改善应用服务器性能
应用服务器作为网站的日寇,会承担大量的请求,往往使用应用服务器集群来分担请求数。
应用服务器前面部署 负载均衡服务器,调度客户请求,根据分发策略将请求分发给多个应用服务器节点。
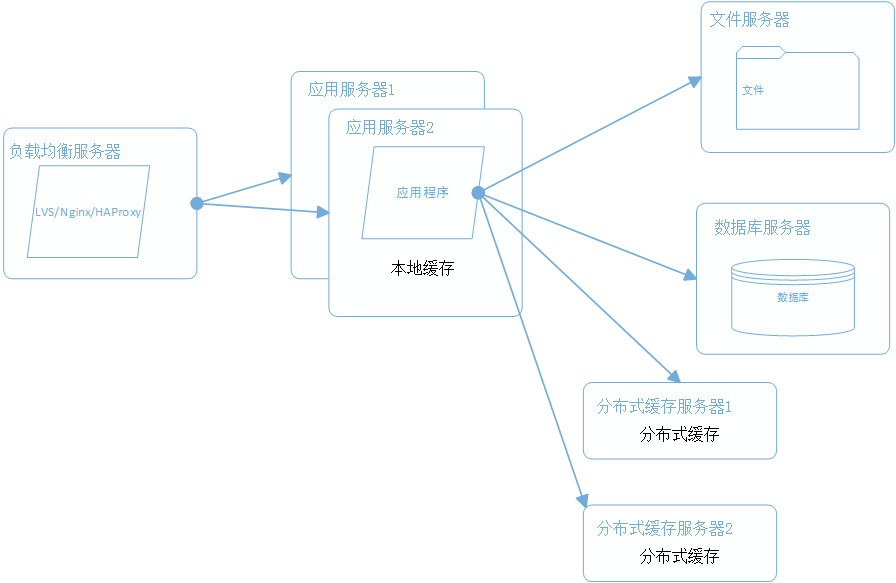
负载均衡技术硬件是 F5(Google 了一下发现好贵……),软件技术主要有 LVS,Nginx,HAProxy
LVS 是四层负载均衡,根据 目标地址 和 端口 选择内部服务器。而后两者都是 七层负载均衡,可以根据 报文内容 选择内部服务器。
根据上面的特点,可以知道 LVS 的分发路径优于 Nginx 和 HAProxy, 性能要高一些。而 Nginx 和 HAProxy 则更具配置型,例如可以用来实现 动静分离(根据请求报文的不同特征来选择静态资源服务器或者是应用服务器)
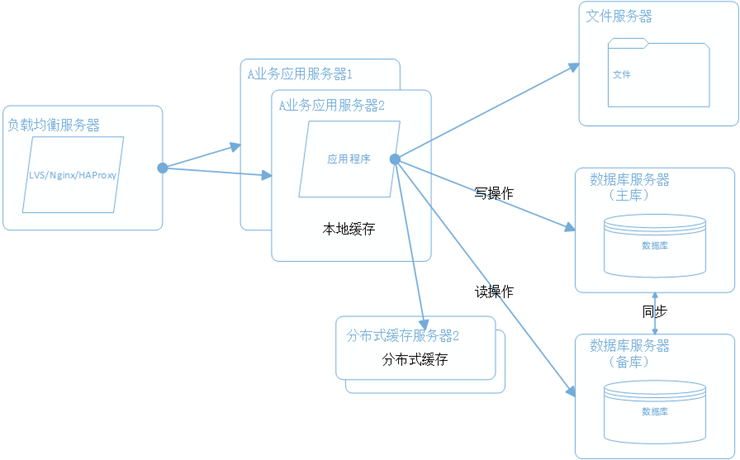
5.5 数据库读写分离和分库分表
随着用户量的增加,数据库成为了最大的瓶颈。改善数据库性能的常用手段是进行了 读写分离 和 分库分表。
读写分离,顾名思义是将数据库分开,分为 读库 和 写库, 不同库之间通过主备功能实现数据同步。
分库分表,则是分为 水平切分 和 垂直切分, 水平切分 指的是将一个数据库特别大的表进行拆分,比如用户表,分为几个不同的部分。垂直切分 指的是根据业务的不同来切分,如用户业务,商品业务等等不同业务的表放在不同的数据库之中。
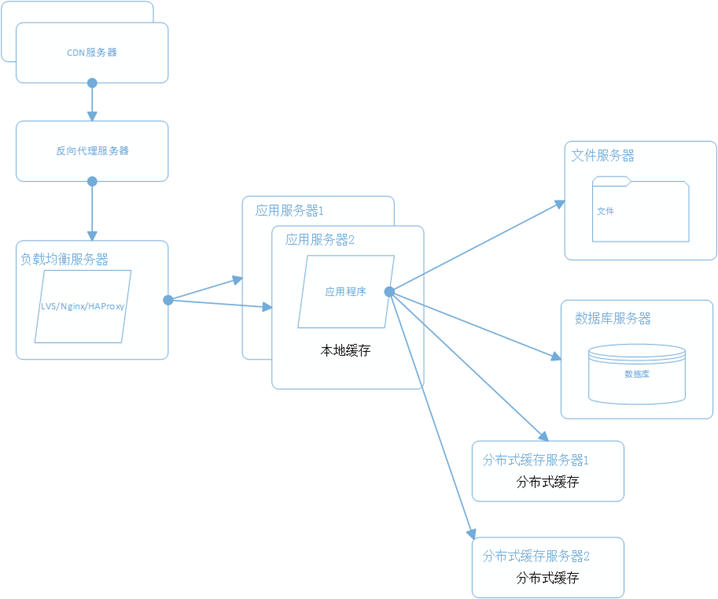
5.6 使用 CDN 和 反向代理 提高网站性能
CDN 主要用来解决因为地域不同而造成的资源获取过慢问题。
反向代理,通常部署在网站的机房,之前提到过,反向代理服务器上面可以部署缓存。当用户请求到达的时候,首先访问反向代理服务器,反向代理服务器将缓存的数据返回给用户,当没有缓存数据的时候,才会继续访问应用服务器来获取。这样子减少了获取数据的成本。反向代理有 Squid, Nginx
5.7 使用分布式文件系统
用户量和业务量的不断增加,产生的文件会越来越多,单台的文件服务器已经不能满足需求。这个时候就需要分布式文件系统的支撑,常用的有 GFS,HDFS,TFS
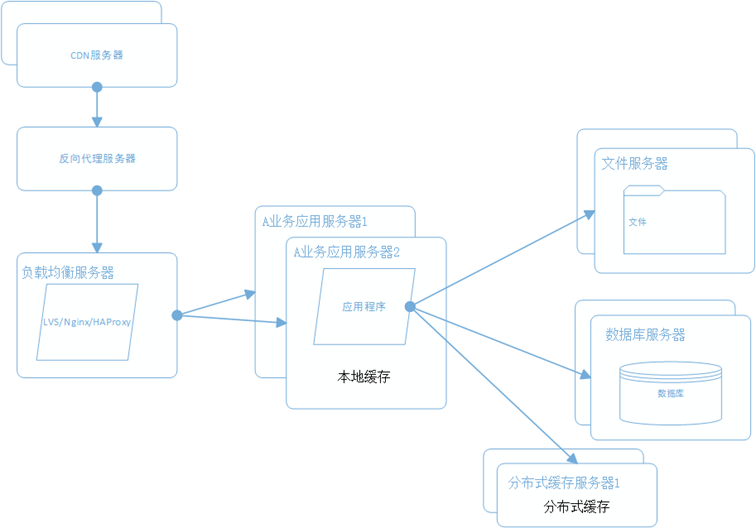
5.8 使用 NoSQL 和搜索引擎
使用这两者的原因是,在海量数据的查询和分析之中,我们使用 NoSQL 数据库加上搜索引擎可以达到更好的性能。
常用的 NoSQL 有 MongoDB,HBase,Redis;搜索引擎有 Lucene,Solr,Elasticsearch。
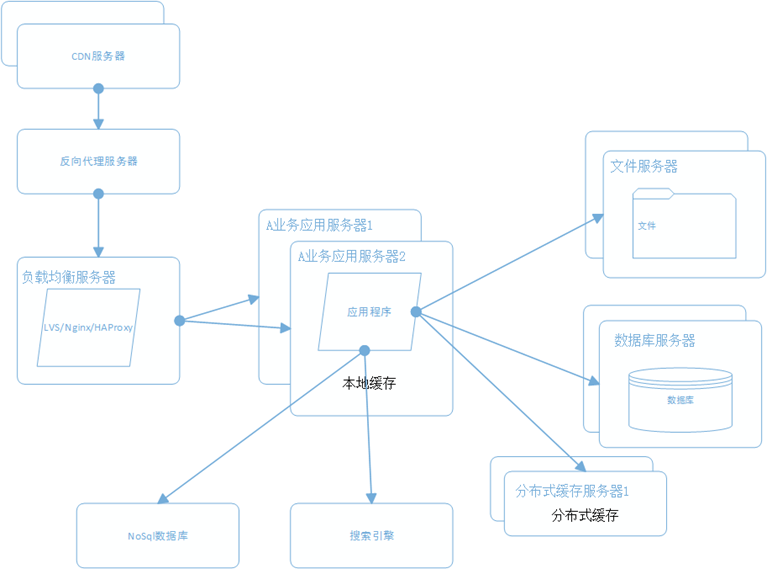
上面这几步可以发现一个很有趣的事情,就是这几步其实都是在存储上面做文章,包括读写分离,使用缓存,CDN,NoSQL等等,本质上都是因为存储部分的速度已经是计算机的瓶颈。
5.9 将应用服务器进行业务拆分
业务进一步扩展,应用程序变得十分臃肿,这时候需要将应用程序进行业务拆分,比如将百度分为 新闻,网页,图片等等业务,每个业务应用负责相对独立的业务运作。业务之间通过消息进行通信,或者共享数据库来实现。
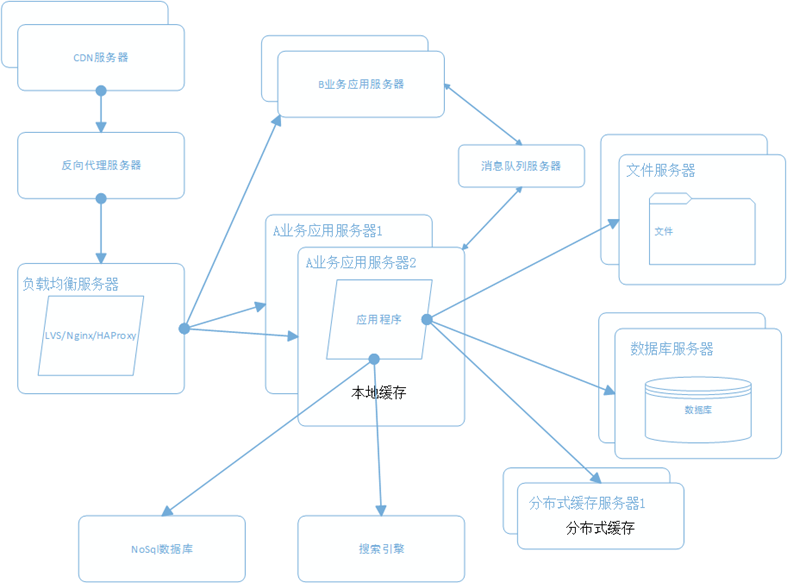
5.10 搭建分布式服务
随着梳理可以发现,各个业务之间会用到一些基本的业务服务,比如 用户服务,订单服务,支付服务,安全服务。那么我们将这些服务抽取出来,利用分布式框架搭建分布式服务。
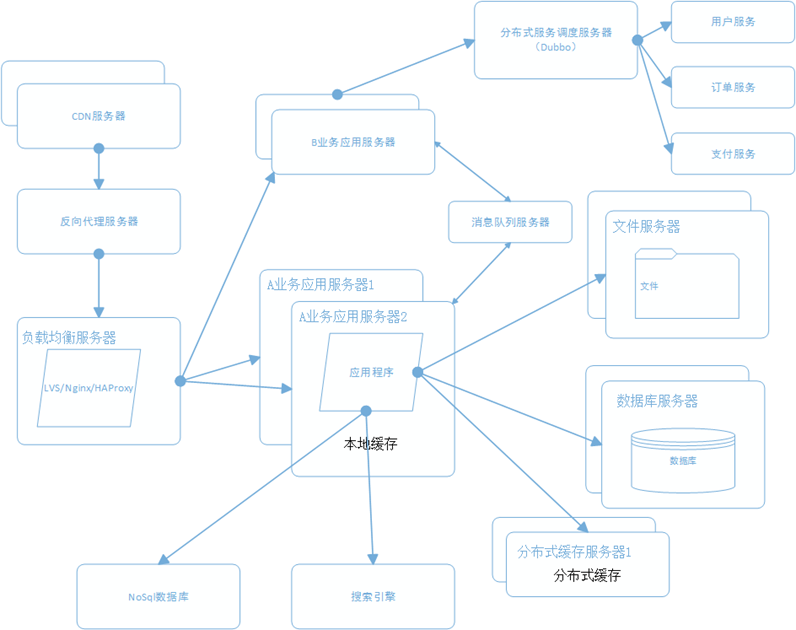
6. 一张图说明电商架构
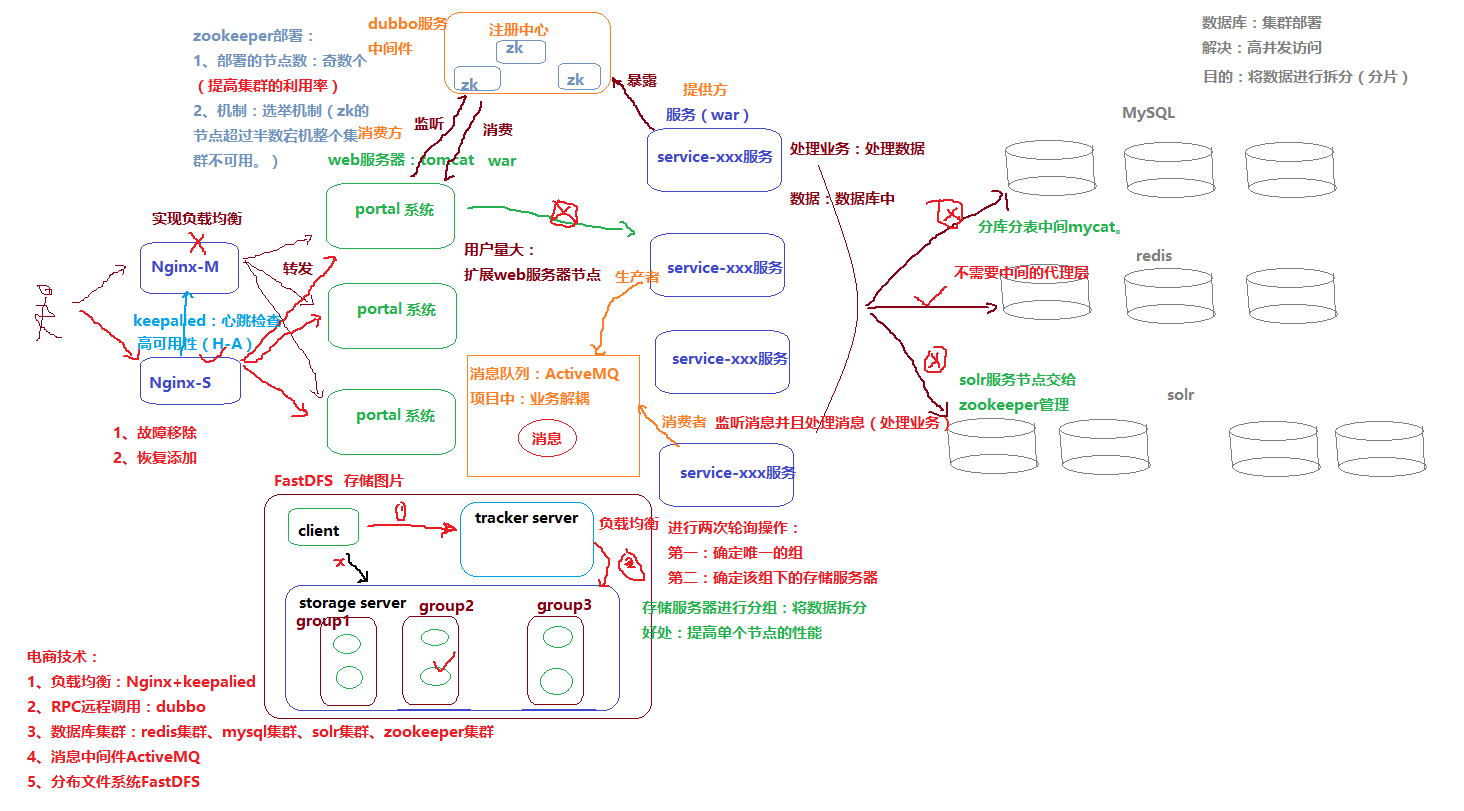
7. 大型电商网站架构案例
7.1 为什么采用电商网站作为案例
分布式大型网站的种类,目前看有:
- 大型门户:网易,新浪等等
- SNS 网站:校内,开心网(全黄了……
- 电商网站:阿里巴巴,京东等等
大型门户一般是新闻类的信息,可以使用 CDN, 静态化等方法优化。开心网等交互性比较多,可能要更多的 NoSQL,分布式缓存,使用高性能的通信框架(不然用户偷一个菜要10秒没人玩),但是电商网站具备以上两类所有的特点,比如 产品详情 页面可以使用 CDN,静态化。交互性高的要使用 NoSQL 等技术。因此,我们采用电商网站做案例。
7.2 电商网站需求
客户爸爸的需求是:
- 建立一个全品类的电子商务网站(B2C),用户可以在线购买商品,可以在线支付,也可以货到付款;
- 用户购买时可以在线与客服沟通;
- 用户收到商品后,可以给商品打分,评价;
- 目前有成熟的进销存系统;需要与网站对接;
- 希望能够支持3~5年,业务的发展;
- 预计3~5年用户数达到1000万;
- 定期举办双11、双12、三八男人节等活动;
- 其他的功能参考京东或国美在线等网站。
客户不会告诉你具体要什么功能,只会告诉你他想要什么东西。那么经过引导,挖掘客户需求之后,第一步是提出需求功能矩阵。
需求功能矩阵
传统的需求管理做法,会使用 例图 或者 模块图(需求列表)来进行需求的描述,但是这样做常常忽视掉非功能的需求。因此建议使用需求功能矩阵进行需求描述。
本网站的需求矩阵如下:
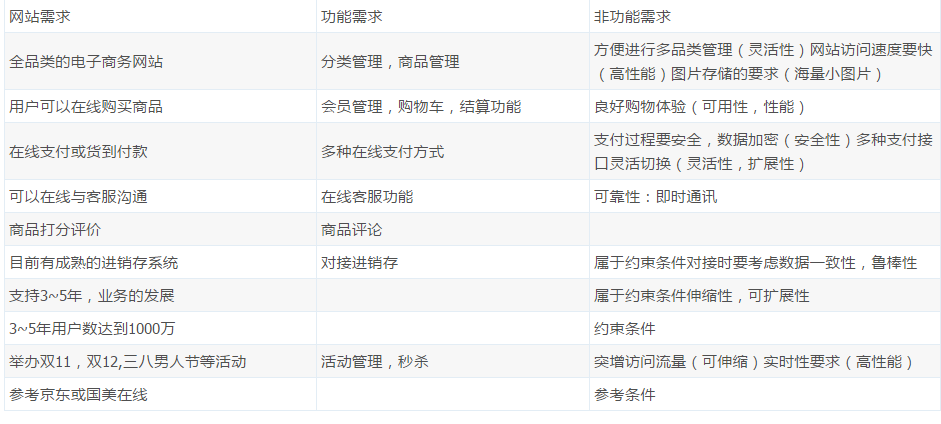
可见功能需求是”what”,非功能需求是”how”,在什么程度下面实现需求。
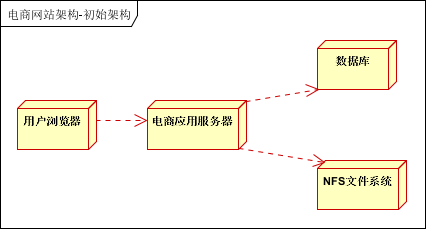
7.3 网站初级架构
之前的架构,一般是三台服务器,一台部署应用,一台部署数据库,一台部署NFS文件系统。
但是,目前主流的网站架构已经发生了翻天覆地的变化。一般都会采用集群的方式。
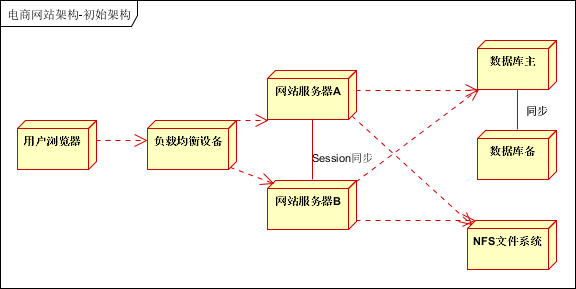
原因在于:
- 使用集群对 应用服务器 进行冗余,实现高可用。负载均衡设备可以和应用一起部署
- 使用 数据库主备模式。实现数据备份和高可用。
7.4 系统容量预估
预估步骤:
- 注册用户数——日均UV(Unique visitor, 独立访客)——日均PV(Page view,页面浏览量)——每天的并发量
- 峰值预估取平常量的2-3倍
- 根据并发量(并发,事务数),存储容量计算系统容量。
根据客户需求:3~5年用户数达到1000万注册用户,可以做每秒并发数预估:
- 每天的UV为200万(二八原则);
- 每日每天点击浏览30次;
- PV量:200*30=6000万;
- 集中访问量:240.2=4.8小时会有6000万0.8=4800万(二八原则);
- 每分并发量:4.8*60=288分钟,每分钟访问4800/288=16.7万(约等于);
- 每秒并发量:16.7万/60=2780(约等于);
- 假设:高峰期为平常值的三倍,则每秒的并发数可以达到8340次。
- 1毫秒=1.3次访问;
服务器预估:(使用 tomcat 举例)
按照一台服务器每秒支持300个并发计算,平时需要10台左右的服务器,(tomcat 默认配置150),高峰期需要 30 台服务器。
容量预估:70/90 原则
系统CPU一般维持在 70% 的水平,高峰期维持在 90%的水平,是不浪费资源,并且比较稳定的。内存和IO 的比例与之类似。
7.5 网站架构分析
根据以上预估,有几个问题:
- 需要部署大量的服务器,高峰期计算,可能要部署30台Web服务器。并且这三十台服务器,只有秒杀,活动时才会用到,存在大量的浪费。
- 所有的应用部署在同一台服务器,应用之间耦合严重。需要进行垂直切分和水平切分。
- 大量应用存在冗余代码
- 服务器Session同步耗费大量内存和网络带宽
- 数据需要频繁访问数据库,数据库访问压力巨大。
大型网站一般用到一下架构优化:(优化的定义为:优化是架构设计时,就要考虑的,一般从架构/代码级别解决,调优主要是简单参数的调整,比如JVM调优;如果调优涉及大量代码改造,就不是调优了,属于重构)
- 业务拆分
- 应用集群部署(分布式部署,集群部署和负载均衡)
- 多级缓存
- 单点登录(分布式 Session):简称为 SSO,是目前比较流行的企业业务整合的解决方案之一。SSO的定义是在多个应用系统中,用户只需要登录一次就可以访问所有相互信任的应用系统。
- 数据库集群(读写分离,分库分表)
- 服务化
- 消息队列
- 其他技术等等
7.6 网站架构优化
7.6.1 业务拆分
首先,根据业务属性进行垂直切分,以功能为切分点进行子系统的划分,如将整个系统分为产品子系统,购物子系统,支付子系统,评论子系统,客服子系统,接口子系统(对接如进销存,短信等外部系统等等。
根据业务子系统进行等级定义,可以将系统分为核心系统和非核心系统。
核心系统有:产品子系统,购物子系统,支付子系统;
非核心:评论子系统,客服子系统,接口子系统。
- 业务拆分的具体作用:提升为子系统,可以由专门的团队和部门负责。专业的人做专业的事情,可以解决模块之间耦合和扩展性的问题。每个子系统单独部署,避免集中部署导致其中一个应用挂掉,全部应用宕机的问题。
- 等级定义作用:在降级的时候选好应该牺牲哪个。
拆分之后的架构图:
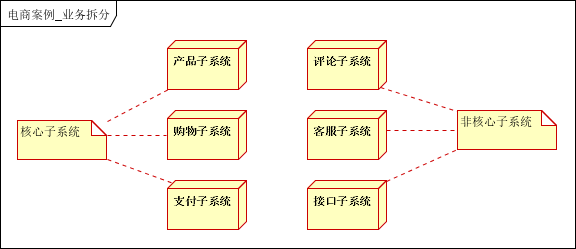
参考的部署方案为:
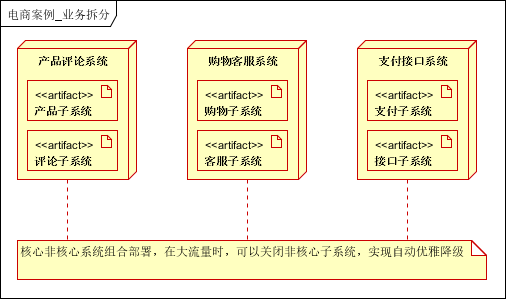
可以看到按照上面这种形式进行 核心系统 和 非核心系统 的组合部署,可以在必要的时候直接牺牲 非核心系统, 换来整个应用的保障性。
7.6.2 应用集群部署(分布式,集群,负载均衡)
下面是对这三点的具体描述:
- 分布式部署: 将业务拆分,之后单独部署。应用直接通过 RPC(Remote Procedure Call,远程过程调用) 进行远程通信。
- 集群部署:电商网站的高可用要求,每个应用至少部署两台服务器,进行集群部署
- 负载均衡:一般系统都通过负载均衡实现高可用,分布式服务通过内置的负载均衡实现高可用,关系型数据库通过主备方式实现高可用。
集群部署之后的架构图:
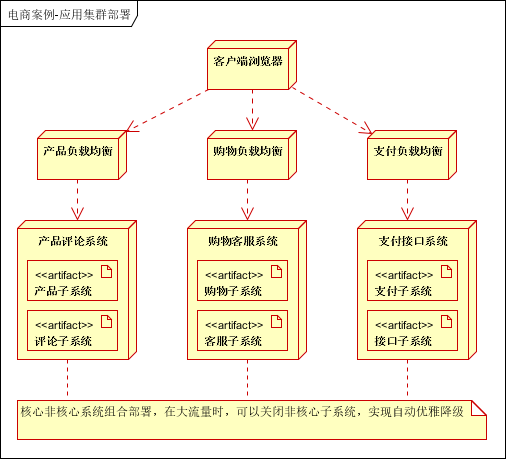
7.6.3 多级缓存
缓存按照存放的位置,一般可以分为两类:本地缓存和分布式缓存。在前面提到过这两种缓存之间的区别,此处就不再赘述了。
在本案例之中,采用二级缓存的方式,一级缓存为本地缓存,二级缓存为分布式缓存,这样综合的方式可以取长补短,让系统达到更好的性能。
一级缓存用来缓存数据字典和常用热点数据等等 基本不可变/有规则变化 的信息。二级缓存用来缓存其他所有缓存。当一级缓存没有命中的时候,访问二级缓存,再不行就访问数据库。
数据字典(Data Dictionary),是一种用户可以访问的记录 数据库 和 应用程序元数据 的目录。其相当于对整个数据进行简单的建模,是描述数据的信息集合。
缓存的比例,一般在 1:4 左右,就可以考虑使用缓存了。
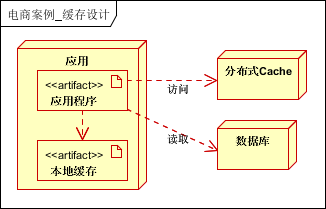
根据业务特性,可以使用以下的缓存过期策略。
- 缓存自动过期
- 缓存触发过期(缓存过期的时候自动触发事件)
7.6.4 单点登录(分布式 Session)
在将一个完整的系统分割为几个子系统进行部署之后,不可避免的会遇到会话管理的问题。一般对于这种问题,我们使用 Session 同步 和 分布式 Session 。电商网站一般采取 分布式 Session 实现。
可以根据分布式 Session, 建立完善的 单点登录 或者 账户管理系统。
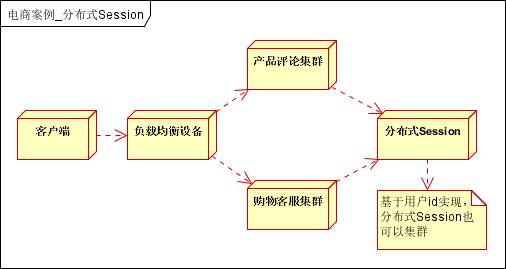
流程说明:
- 用户第一次登录的时候,将会话信息(用户ID和用户信息),比如以 用户ID 为 Key,写入 分布式 Session。
- 用户再次登录的时候,获取 分布式 Session, 是否有会话信息,没有会话信息就调到登录页面。
- 一般采取的是 Cache 中间件实现,建议使用 Redis, 因为其具有持久化功能,万一 分布式 Session 宕机的情况下,可以从持久化存储之中再加载会话信息。
- 存入会话的时候,可以设置会话的保持时间,比如 15 min,超过之后自动超时等策略。
结合Cache中间件实现的分布式 Session,可以很好的模拟 Session 会话。
7.6.5 数据库集群(读写分离,分库分表)
大型网站需要存储的数据量极大,为了达到海量数据存储高性能高可用,一般采取冗余的方式进行系统设计。一般有两种方式,读写分离 和 分库分表。
读写分离:由于一般而言,读的比例远远高于写的比例,所以采用 主备方式。
本案例之中,在业务拆分的基础上,结合 分库分表 和 主备分离,如下图:
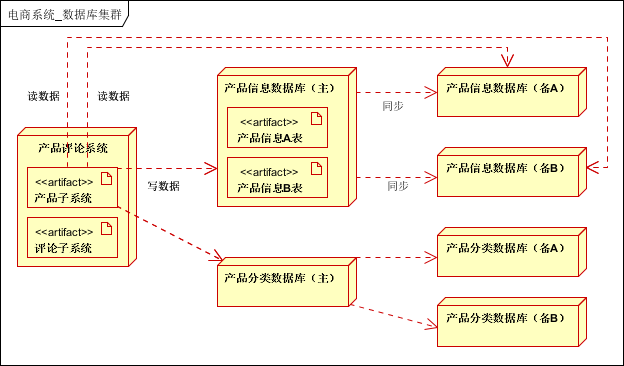
- 业务拆分之后:每个子系统需要单独的库
- 如果单独的库太大,可以根据业务特性,进行再次的细分。比如商品分类库,产品库等等。
- 分库之后,如果表中有数据量很大的,则进行分表,一般可以按照 ID, 时间 等等进行分表,更高级一点的做法是使用 一致性Hash。
- 在分库,分表的基础上,进行 读写分离。
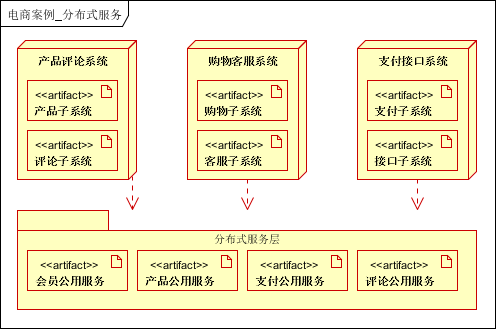
7.6.6 服务化
将公用的模块,进行抽取,作为公共服务使用。比如本案例之中的 会员子系统。
7.6.7 消息队列
消息队列可以解决 子系统/模块 之间的耦合,实现异步和高可用。本案例之中,主要用在购物,配送环节。
- 用户下单之后,写入消息队列,直接返回客户端,无需等待写入数据库之后再返回。
- 库存子系统:读取消息队列信息,完成库存减少的操作
- 配送子系统:读取消息队列信息,进行配送。
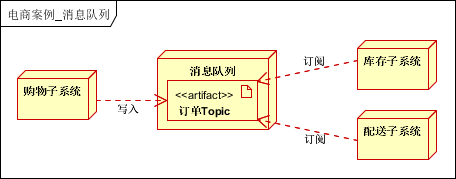
目前使用较多的 MQ 有 Active MQ、Rabbit MQ 等等,在之前的博文之中有介绍,就不赘述了。
8. 架构汇总
结合上面的所有,可以得到下面这个图:
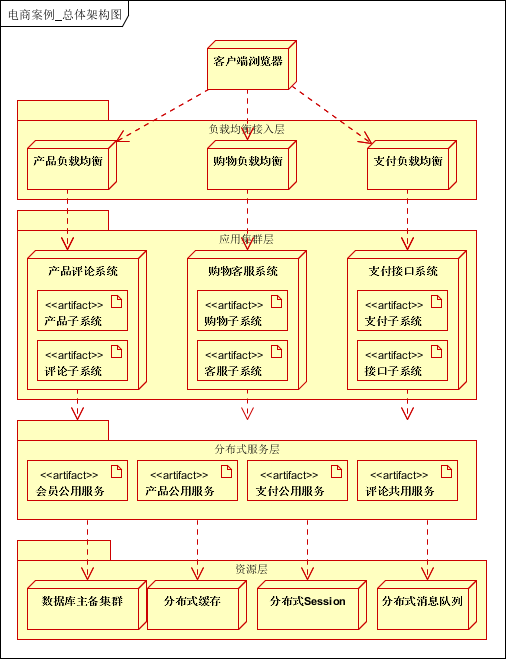
个人心得:
总而言之,我认为在一个大型分布系统之中,最重要的事情有两个:均衡和同步。均衡,是让所有服务能均衡的得到流量,避免单点的负载过重。同步,则是为了在不同的集群之间的消息可以一致,做到整个系统之中没有冲突。当然,存储方面的优化,比如 CDN, 分布式缓存等等,也都是优化用户体验的重要一环,但是并非分布式系统所独有,因此就不算在内。均衡,要求按照功能,按照层次拆分;而同步,要依靠比如消息队列,主从系统同步等等机制来实现。