经各位大佬推荐,想要把 Java 弄明白一点,就看一下《阿里巴巴 Java 开发手册》,那就开始呗。
看了看发现 《码出高效》 这本书更适合,那就改成看这本书了……
第一章 计算机基础
以下的基础问题:
- 位移运算可以快速的实现乘除运算,那位移的时候要注意什么?
- 浮点数的存储与计算为什么总会产生微小的误差?
- 乱码产生的根源是什么?
- 代码执行的时候,CPU 是如何配合内存完成工作的?
- 网络链接资源耗尽的本质是什么?
1.1 走进 0 和 1 的世界
1.1.1 左移/右移 对于数据的修改
左移和右移有两种: « ; » 和 »>。
« 和 » 代表的是带符号位进行移动。除了右移负数, 高位补 1 之外,其他情况下均在空位上面补0。
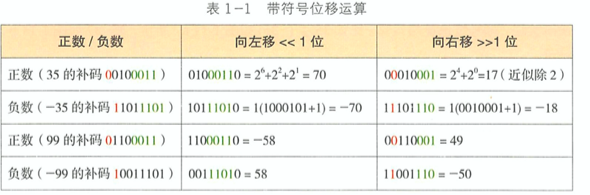
但是左移相对而言就没有上述这种十分确定的关系,原因是:由于符号向左运动,其实不知道是要在移动之后的结果的符号位。 最左位可能是 0 ,可能是 1,那么 带符号左移 之后的结果可能和原来不符,出现正数左移是负数,负数左移是正数的情况。
对于 »> 的这种无符号向右移动,当向右移动的时候,不管正数还是负数,高位全都补 0 。正数不断向右移动的最小值是 0 , 负数不断向右移动的最小值是 1。 其原因为:实际过程之中,位移运算是先 mod 其位数,然后再进行移动。用 32 位为例, 因为移动的位数是一个 mod 32 的结果,所以 35 »1 和 35 » 33 是一样的结果。那么如果一个数 无符号向右移动 63 位的时候,除了最右边是 1 之外,左边全是 0,达到最小值 1,如果 »> 64, 那么就是原数值本身。
1.1.2 浮点数
下面的示例代码显示了浮点数运算之中的误差。
float a = 1f;
float b = 0.9f;
//The result is 0.100000024
float f = a - b;
是因为浮点数按理来讲,只可以表示 2^n 的数,n 可以为正数或者负数等等。但是 0.9 无法用有限的二进制位进行精确表示,所以 1-0.9 并不精确的等于 0.1 。
浮点数如何进行加减运算
-
在浮点数进行加减运算的时候,首先要将小数点对齐,然后同位数进行加减运算。 在 浮点数 之中,规定了阶码和尾数 都是0 的数就是0 。如果其中一个数是0, 则直接得到结果。
- 在对阶的过程中,有一部分二进制位会被移除,由于上面的定义,我们可知,左移和右移的影响不同,右移只是一部分小数位会被移除,但是左移的话高位会被移除。所以 IEEE754 规定的是,选择阶码小的数进行右移操作。
- 然后便是直接求和和结果规格化。结果规格化之中,如果运算的结果不满足规格化的形式,那么会通过尾数的左移或者右移来达到规格化形式。
- 由于在第二步之中,我们讲了有“右移操作”,但是最终被移除去的位数不可以丢弃,其在规格化之中再做舍入处理。
浮点数要求注意的点
- 在昨天的博文之中也提到过,像货币等等要求绝对精确的情况下,推荐使用整型来表示其最小单位的值。
- 在要求精确表示小数点后n位的情况下,比如圆周率的小数点后 n 位数字,可以使用数组来保存小数部分的数据。
- 由于之前的例子,可以看到在比较浮点数的时候,往往存在误差,因此禁止使用比较某些浮点数是否相等来控制业务流程。
- 数据库之中,保存小数的时候,推荐使用 decimal 类型,禁止使用 float 类型和 double 类型。禁止使用这两种类型的原因也是因为其存在精度损失的问题。
1.1.3 字符集和乱码
当前编码环境之中推荐的换行方式是 LF, 也就是\r\n
汉字的实现编码标准有很多,几个比较典型的有:GB2312,GBK 还有 UTF。
我对 UTF-8 的定界很感兴趣,下面是一点小研究:
首先,UTF 的开始就是说要兼容 ASCII 码,当然 UTF-8 也是一样
但是 UTF 之中是使用不同的长度的字符串来代表不同的字符,其虽说不是完全按照不同语言的字母在全世界的出现频率来看,但是也遵循了大致的趋势。
UTF-8的设计有以下的多字符组序列的特质:
- 单字节字符的最高有效比特永远为0。
- 多字节序列中的首个字符组的几个最高有效比特决定了序列的长度。最高有效位为
110的是2字节序列,而1110的是三字节序列,如此类推。 - 多字节序列中其余的字节中的首两个最高有效比特为
10。
UTF-8的这些特质,保证了一个字符的字节序列不会包含在另一个字符的字节序列中。这确保了以字节为基础的部分字符串比对(sub-string match)方法可以适用于在文字中搜索字或词。有些比较旧的可变长度8位编码(如Shift JIS)没有这个特质,故字符串比对的算法变得相当复杂。虽然这增加了UTF-8编码的字符串的信息冗余,但是利多于弊。另外,数据压缩并非Unicode的目的,所以不可混为一谈。即使在发送过程中有部分字节因错误或干扰而完全丢失,还是有可能在下一个字符的起点重新同步,令受损范围受到限制。
为了与以前的ASCII码兼容(ASCII为一个字节),因此UTF-8选择了使用可变长度字节来存储Unicode:
| 码点的位数 | 码点起值 | 码点终值 | 字节序列 | Byte 1 | Byte 2 | Byte 3 | Byte 4 | Byte 5 | Byte 6 |
|---|---|---|---|---|---|---|---|---|---|
| 7 | U+0000 | U+007F | 1 | 0xxxxxxx |
|||||
| 11 | U+0080 | U+07FF | 2 | 110xxxxx |
10xxxxxx |
||||
| 16 | U+0800 | U+FFFF | 3 | 1110xxxx |
10xxxxxx |
10xxxxxx |
|||
| 21 | U+10000 | U+1FFFFF | 4 | 11110xxx |
10xxxxxx |
10xxxxxx |
10xxxxxx |
||
| 26 | U+200000 | U+3FFFFFF | 5 | 111110xx |
10xxxxxx |
10xxxxxx |
10xxxxxx |
10xxxxxx |
|
| 31 | U+4000000 | U+7FFFFFFF | 6 | 1111110x |
10xxxxxx |
10xxxxxx |
10xxxxxx |
10xxxxxx |
10xxxxxx |
- 在ASCII码的范围,用一个字节表示,超出ASCII码的范围就用字节表示,这就形成了我们上面看到的UTF-8的表示方法,这様的好处是当UNICODE文件中只有ASCII码时,存储的文件都为一个字节,所以就是普通的ASCII文件无异,读取的时候也是如此,所以能与以前的ASCII文件兼容。
- 大于ASCII码的,就会由上面的第一字节的前几位表示该unicode字符的长度,比如110xxxxx前三位的二进制表示告诉我们这是个2BYTE的UNICODE字符;1110xxxx是个三位的UNICODE字符,依此类推;xxx的位置由字符编码数的二进制表示的位填入。越靠右的x具有越少的特殊意义。只用最短的那个足够表达一个字符编码数的多字节串。注意在多字节串中,第一个字节的开头”1”的数目就是整个串中字节的数目。
在淘宝的架构之中就出现过这样的问题,一开始都是GBK编码,但是国际站使用的是UTF-8,所以在相互查看源码的时候,中文注释基本都不可读。为了减少麻烦,所有情况最好字符集设置一致。
1.1.4 CPU和内存
CPU 的内部结构,总的来讲,就是由控制器和运算器组成的。第三部分,寄存器,主要是让二者的协同更加高效。CPU的内部结构如图所示:
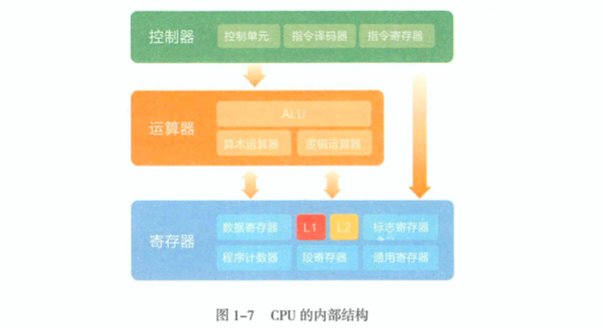
- 控制器
- 控制单元:是CPU的大脑,由 时序控制 和 指令控制 组成。
- 指令译码器: 在 控制单元 的参与下完成指令读取,分析并且交给 运算器 执行
- 指令寄存器: 存储指令集,流行的指令集包括 X86,SSE,MMX 等等
控制器有点像一个编程语言的编译器,输入 0 和 1 的源码流, 通过译码和控制单元对存储设备的数据进行读取,运算完成之后再保存回寄存器,甚至是内存。
- 运算器
运算器的核心是 算术逻辑运算单元 ,即 ALU。可以执行算术运算,或者逻辑运算等等各种命令,运算单元会从寄存器之中提取或者存储数据。所有的指令,最后都会变成0 和 1 的组合流形式在部件内部完成运算,并且保存到寄存器,最后送到 CPU。
- 寄存器
最著名的寄存器是 CPU 的高速缓存 L1和 L2.
CPU 之中不同的语言效率不同,C 和 C++ 可以直接操作内存地址,对其进行分配和释放。如果发现地址错误,就直接抛出异常。但是像 Java 这种,直接使用 JVM,那么就会把资源直接交给 JVM 让其分配,代价是到货的速度慢了。
1.1.5 TCP/IP
先从网络协议开始。网络协议之中,OSI 七层模型已经不再被使用,但是下面几层还是现在在使用。
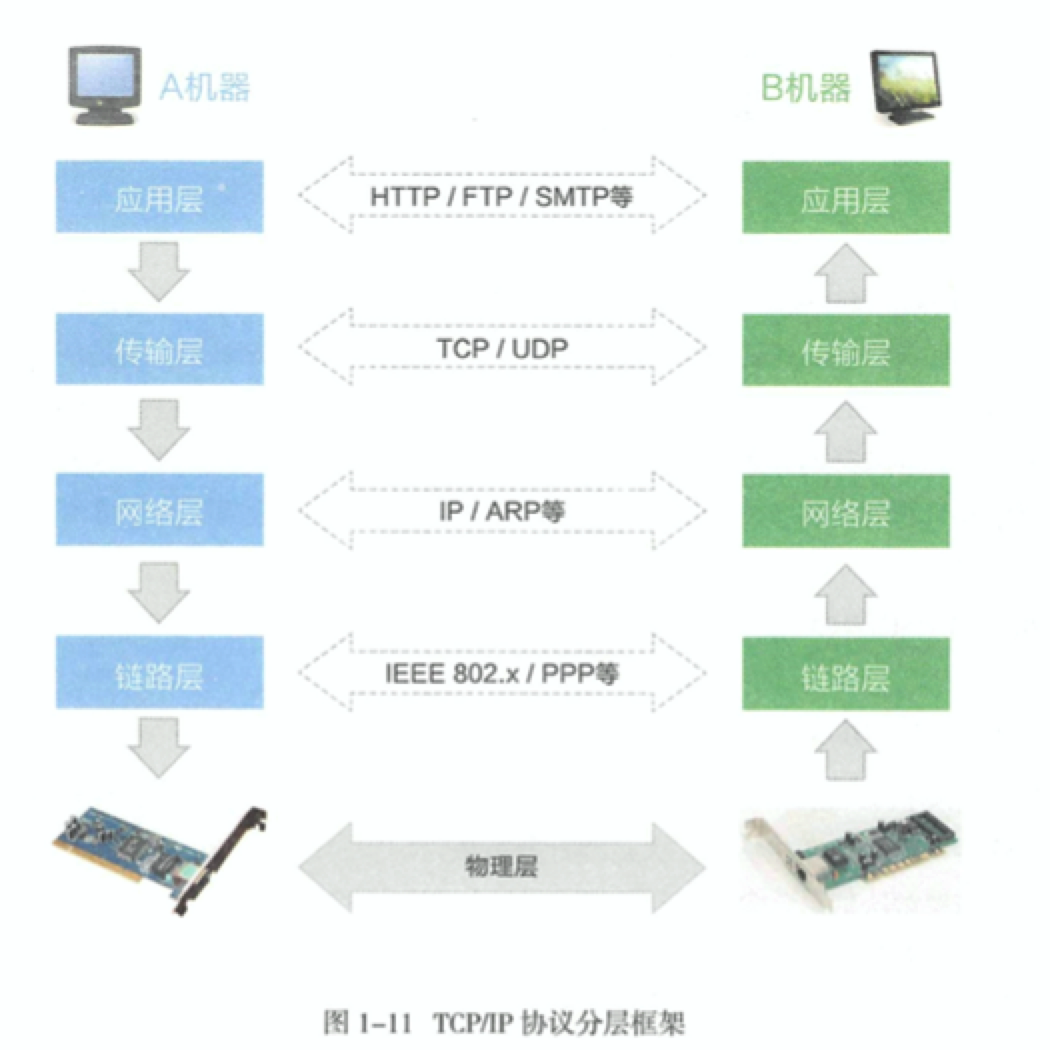
其中可以看到每一层对应的典型协议。
- 链路层: 将 0 1 流分组之后定义数据帧,写入地址并且传输数据。用MAC 地址
- 网络层:定义网络地址,区分网段。
- 传输层:数据包在通过网络层发送到目标计算机之后,应用程序在传输层定义逻辑端口,确认身份之后将数据包发到应用程序。最典型的是 UDP 和 TCP。
总的来说,在发送数据的时候,就是遵循”端口—–>IP地址——-> MAC 地址“这样的一个顺序进行数据的封装和发送。解包的时候反过来就可以。
1.5.2 IP协议
IP协议可以用来方便的管理MAC地址,通过分层的方式进行网段的划分。
ICMP,(Internet Control Message Protocol) ,是用来检查网络是否通畅,主机是否可达等等的网络运行状态的协议。经常使用的 ping, tracert 等等就是 ICMP 的工具。
1.5.3 TCP建立连接
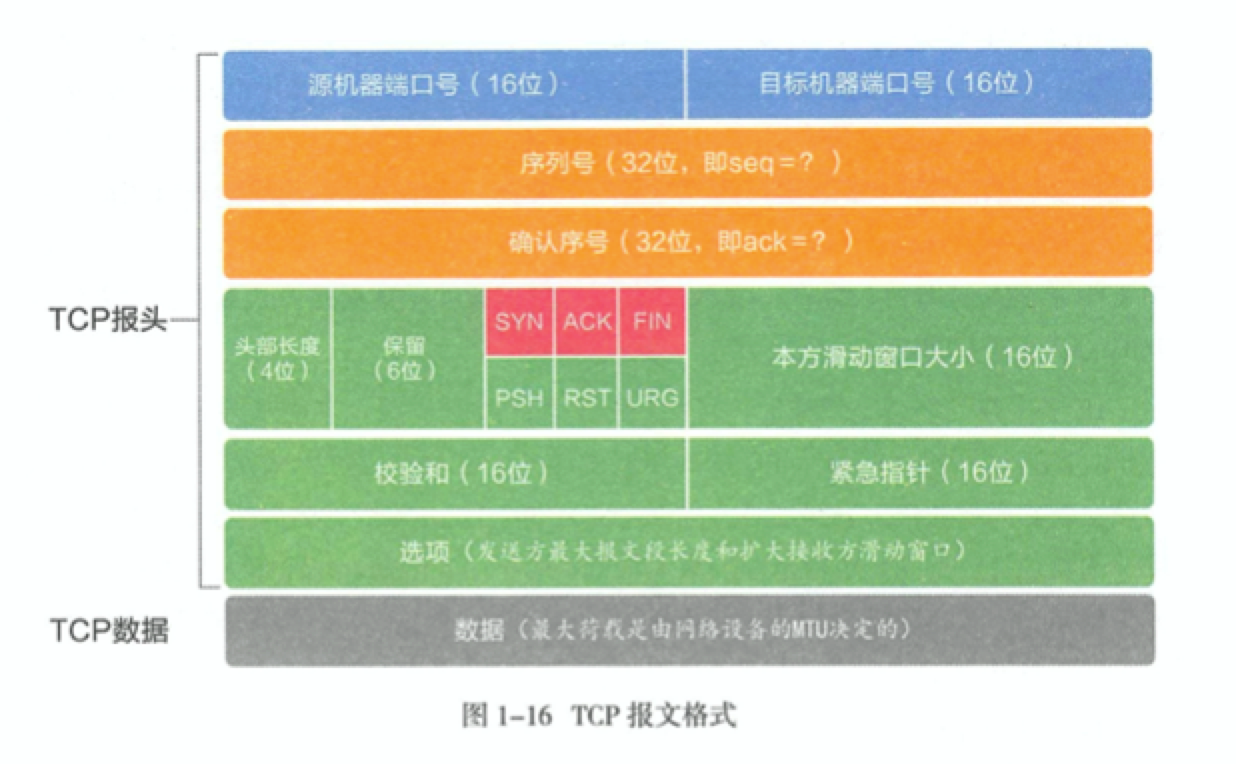
TCP 是面向连接的,所以有服务端和客户端之分。 服务端必须要事先在相应的端口上面进行监听,准备好接收客户端发起的建立连接的请求。
当客户端发起第一个请求建立连接的 TCP 包的时候,目标机器的端口,就是服务端监听的端口号。
下面是一些已经定义的广为人知的端口号:
- HTTP 的 80 端口
- SSH 服务的 22 端口
- HTTPS 的 443 端口
可以通过 netstat 列出机器上已经建立的连接信息,红框是端口号:

1.5.5 连接池
在时间紧张的情况下,在客户端和服务端之间可以事先创建若干连接,并提前放在连接池之中。在需要的时候可以从连接池直接获取,并且在数据完成传输之后,可以直接将连接归还到连接池之中,从而减少频繁创建和释放连接的损耗。
下面是关于慢SQL的优化问题:
- 优化应用层逻辑: 数据结构优化,并发多线程改造等
- 创建数据库索引
-
排查连接资源未显式关闭的情况,特别注意在ThreadLocal或者流式计算之中使用数据库连接的情况。
- 合并段的请求:根据 CPU 的空间局部性原理,对于相近的数据,CPU会一起提取到内存之中。另外,合并请求也可以有效减少连接的次数。
- 合理拆分多个表 join 的 SQL, 超过三个表直接禁止Join。 如果表的结构不合理,或者是业务处理不当,那么三表join的数据量由于笛卡尔积操作会几何级数增加。所以不推荐这样的做法。另外,有 join 的情况,数据类型应该保持完全一致。多表关联查询的时候,应确保被关联的字段有索引。
- 使用临时表:某些情况下是个好的选择。将中间结果保存到临时表,重建索引,再通过临时表进行后续的数据操作。
1.6 信息安全
1.6.1 黑客和安全
互联网企业要建立一套完整的信息安全系统,要遵循CIA原则:保密性:(Confidentiality),完整性(Integrity), 可用性(Availablity).
- 保密性:对需要保护的数据进行保密操作,不论是存储过程还是传输过程。
- 完整性:访问的数据要是完整的,而不是缺失的或者被篡改的。 通常的做法是怼数据进行签名和校验。
- 可用性:可用性是一切的基础,例如Dos等就是通过大量攻击服务导致服务不可用。 可使用访问控制,限流等等进行解决。
1.6.2 SQL注入
SQL注入是将代码和数据未进行分离,所以将数据作为代码的一部分进行执行。
一般可以通过以下几个部分考虑:
- 过滤用户传入参数之中的特殊字符,从而降低 SQL 被注入的风险。
- 禁止通过字符串拼接的 SQL 语句,严格使用参数绑定传入的 SQL 参数
- 合理使用数据库访问框架提供的防注入机制。比如 MyBatis 提供的 #{} 绑定参数,从而防止 SQL 注入。 同时谨慎使用 ${} , ${} 相当于使用字符串拼接 SQL,拒绝拼接的 SQL, 使用参数化的语句。
1.6.3 XSS和CSRF
XSS,跨站脚本攻击,Cross-Site Scripting。
XSS,指黑客通过技术手段,向正常用户请求的HTML页面插入恶意脚本,从而可以执行任意脚本。XSS 主要分为反射型XSS, 存储型XSS和 DOM型XSS。
在防范XSS上,主要通过对用户输入数据做过滤或者转义。 比如 Java 开发人员可以用 Jsoup 框架对用户输入字符串做XSS过滤,或者使用框架的工具类,对用户输入的字符串做HTML转义。
1.6.4 CSRF
跨站请求伪造,(Cross-Site Request Forgery), 简称CSRF,也被称为 One-click Attack, 即在用户不知情的情况下冒充用户发起请求。
CSRF 有别于 XSS, 是黑客直接盗用用户的浏览器之中的登录信息,冒充用户去进行黑客的指定操作。
防范CSRF漏洞主要通过以下方式:
- CSRF token 验证: 利用浏览器的同源限制,在 HTTP 接口执行之前验证页面或者Cookie之中设置的 Token, 只有验证通过才能继续执行请求。
- 人机交互,比如调用银行转账接口的时候校验短信验证码
下面这个教程很好:https://www.ibm.com/developerworks/cn/web/1102_niugang_csrf/index.html
无非就是对于各种不同的方式做出区分,比如在前面加上只和用户相关的 token,那么黑客没法仿造这个用户的 token,说到底,使用一些方式在请求来之前对请求再次进行验证,就是一种解决的思路。