1. Java
1.1 面向对象一定比面向过程性能差吗?
1.2 Java 的多态性
多态之中是父子相关的性质。其标识是父类引用对象可以指向子类引用对象:
父类类型 变量名字 = new 子类类型();
那么对于方法和变量,到底以谁为准呢?
- 多态成员变量:编译运行看左边
Fu f=new Zi();
System.out.println(f.num);//f是Fu中的值,只能取到父中的值
- 多态成员方法:编译看左边,运行看右边
Fu f1=new Zi(); System.out.println(f1.show());//f1的门面类型是Fu,但实际类型是Zi,所以调用的是重写后的方法。
多态的案例:
public class demo1 {
public static void main(String[] args) {
A a=new A();
a.show();
B b=new B();
b.show();
}
}
class A{
public void show(){
show2();
}
public void show2(){
System.out.println("A");
}
}
class B extends A{
public void show2(){
System.out.println("B");
}
}
class C extends B{
public void show(){
super.show();
}
public void show2(){
System.out.println("C");
}
}
其结果为 A B。
1.3 接口和抽象类有何区别?
- 接口通过 implement ,抽象类用 extend
- 可以implement多个接口,但是只能extend 一个抽象类
- 抽象类之中可以有constructor,但是接口之中不可以
1.4 Lambda 表达式和功能接口
先上一段代码:
Integer[] intArray = new Integer[]{3,1,2,5,3,3,6,5,4,7,4};
List<Integer> intList =Arrays.asList(intArray);
intList.sort((Integer i1,Integer i2)->i2-i1);
for(Integer i: intList){
System.out.println(i);
}
这段代码之中使用了Lambda表达式:
(Integer i1,Integer i2)->i2-i1 来作为一个 Comparator。而且由于我本身想要逆序排序,所以将i2和i1的范围调换了。
Comparator的比较原理是:如果后面表达式的返回值为负,认为Object 1 比 Object 2 小。为0则相等,为正则认为Object 1 比 Object 2 大。我此处返回 i2-i1,就意味着当 i2 比 i1 大的时候,返回值为正,那么Comparator认为 i1 比 i2 大,所以会进行实际上的倒序排序。
参考资料: https://segmentfault.com/a/1190000009186509
Java 中的 Lambda 表达式通常使用语法是 (argument) -> (body),比如:
(arg1, arg2...) -> { body }
(type1 arg1, type2 arg2...) -> { body }
这里面的一些示例,比如
(int a, int b) -> { return a + b; }
() -> System.out.println("Hello World");
(String s) -> { System.out.println(s); }
() -> 42
() -> { return 3.1415 };
那么什么是功能接口呢?功能接口,指的是只有一个抽象方法的接口。
我们经常在多线程之中看到的:
Runnable runnable = () -> { };
这就是一个功能接口,因为在Runnable之中只有一个方法的声明 void run()。
如果不显性指定功能接口,那么编译器会自动进行类型转换,比如:
new Thread(
() -> System.out.println("hello world")
).start();
此处编译器推断,Thread有一个构造函数为:
public Thread(Runnable r){}
来去将这个lambda表达式直接转换成 Runnable 接口。
Java8之中还新加入了一个注解,是@FunctionalInterface。打上这个注解的接口都可以作为功能接口,内部也只能有一个抽象方法。
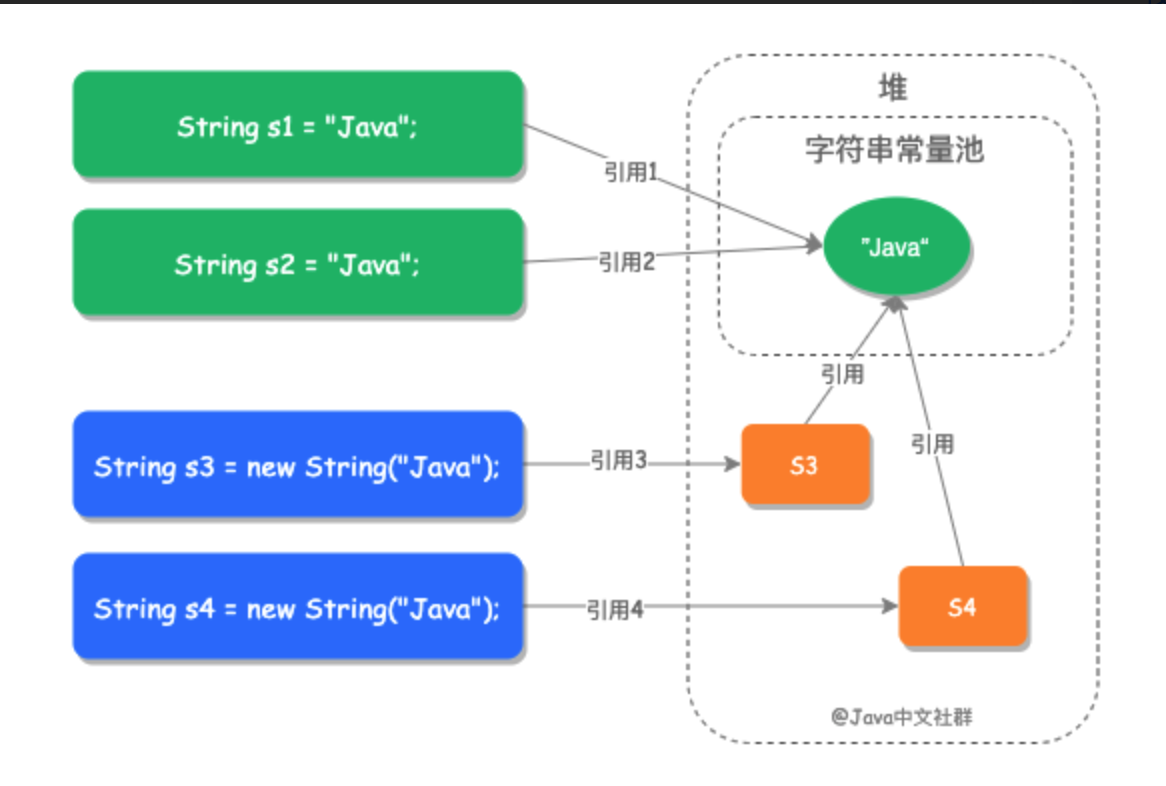
1.5 new一个String到底创建几个对象?
答案是1个或者两个。这个和Java之中的字符串常量池分不开干系。
参考:https://juejin.im/post/5e9903dfe51d454714427e56
public class StringExample {
public static void main(String[] args) {
String s1 = new String("javaer-wang");
String s2 = "wang-javaer";
String s3 = "wang-javaer";
}
}
对于s1,是创建了两个对象。对于s2,是创建了两个对象。
先从1.7和1.8的区别说起:
在jdk1.8之中,最大的区别是将JDK1.7之中的永久代取消,并且加入了元空间,将字符串常量池从方法区挪到了Java的堆上面。
其取消永久代的主要原因是永久代的内存经常不够用,会报出OutOfMemoryError的异常。而元空间对应的是本地内存空间。元空间会根据GC的结果进行调整,如果说GC之后多出很多空间,那么会适当调小,如果GC之后空间还是很紧张,就会进行调大。参数分别是 -XX:MetaspaceSize和-XX:MaxMetaspaceSize。默认情况后者是没有限制的。
方法区之中存储了每个类的信息——因为类不是jvm创建的,放在堆里面不合适。
那么对于上面的代码,其”javaer-wang”和”wang-javaer”都会在编译阶段就被放在运行时常量池之中,但是对于第一句String s1 = new String("javaer-wang"); 程序还要再在堆之中开辟出一个指针指向常量池之中的地址,然后让s1指向这个指针。
2. MySQL
2.1 什么是聚簇索引?什么是非聚簇索引?二者之间的区别在于哪?
在InnoDB 之中使用的是聚簇索引, 在MyISAM 之中使用的是非聚簇索引。二者之间的区别主要在于B+树的子节点上面是否有完整的整条数据。见下图:
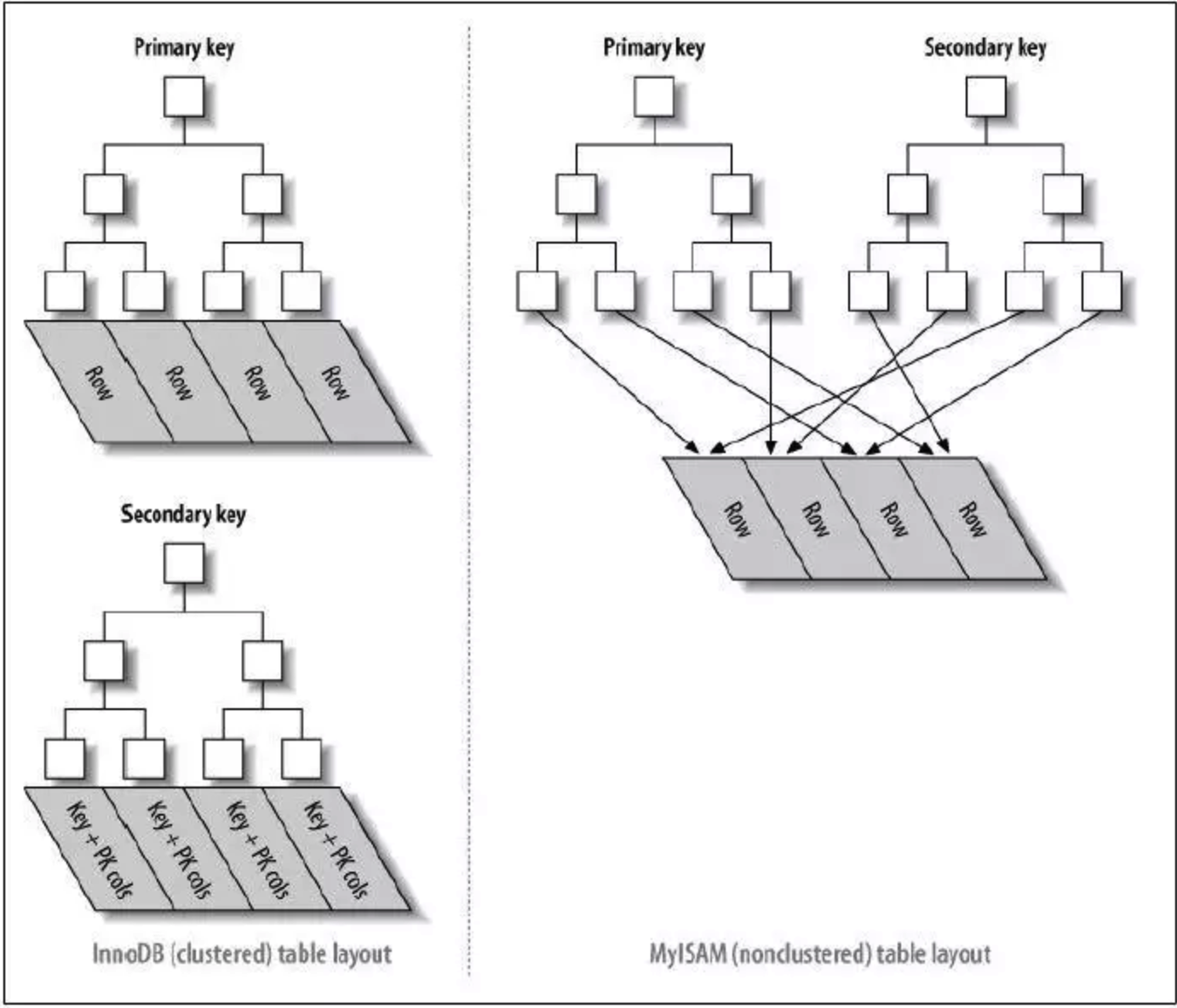
左边的是聚簇索引, 右边的是非聚簇索引。对于非聚簇索引而言,一级索引和二级索引区别不大,都是在最下面的节点之中存储其索引的地址,然后去数据部分查找。但是聚簇索引而言,一级索引的叶子节点上面是有完整的整条数据的,二级索引之中是部分数据和一级索引的key,在二级索引之中查找,需要先拿到对应的key,然后去一级索引之中拿到其中的值。
聚簇索引和非聚簇索引之间的区别在哪?
聚簇索引的优点:
- 可以更方便的查找一个范围的值。
- 在查找时候会更快,省去了一次由key去磁盘找到对应数据的IO
- 如果使用覆盖索引,那么不用再去查大表,更快。
聚簇索引的缺点:
千万不能改主键!!!!
-
为啥主键非得自增?不然的话每次插入都得对于所有数据进行重排,其代价是不可接受的。
- 二级索引需要查找两次,其在二级索引之中加入的是一级索引的key的原因是避免重排导致的维护工作,但是查找时候需要查找两次。
- 插入新值的速度慢很多。因为要确认其ID是否唯一,但是判断方式在不同的索引下面有很大差距。由于InnoDB之中的叶子节点上面有很多数据,因此遍历的过程也会慢很多。
2.2 都有哪些索引类型呢?
- 从数据结构角度:hash索引,B+树索引,全文索引。
- 从物理存储角度:聚簇索引,非聚簇索引
- 从逻辑角度:普通索引,组合索引
2.3 InnoDB引擎之中主键不连续的可能有哪些?
参考:https://draveness.me/whys-the-design-mysql-auto-increment/
- 在MySQL 5.7 之前,内存之中存储的
AUTO_INCREMENT计数器,实例如果重启的话就会根据表中数据进行重新设置,那么有可能出现这样的情况。在8.0之后使用了 redo log来解决这个问题,保证了日志的单调性。 - MySQL 之中插入数据获取
AUTO_INCREMENT的时候不会使用事务锁,而是互斥锁,那么并发插入事务再回滚就可能造成部分字段冲突,导致插入失败。想要保证主键的连续,就得串行的执行插入语句。
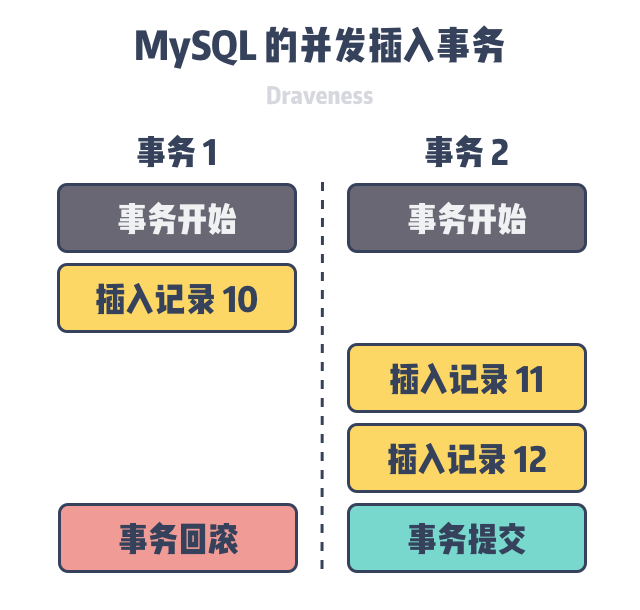
不过如果在最后事务 1 由于插入的记录发生了唯一键冲突导致了回滚,而事务 2 没有发生错误而正常提交,在这时我们会发现当前表中的主键出现了不连续的现象,后续新插入的数据也不再会使用
10作为记录的主键。
- 对批量插入的语句,MySQL有批量申请自增ID的策略, 第一次一个,第二次2个,依次倍增,每一次申请的都是上一次的2倍,那么有可能出现浪费的自增ID,导致出现不连续的情况。
2.4 什么情况下索引会失效?
索引失效,指的是在查找的过程之中无法使用索引,需要直接使用查询全表。
- 不可以使用前导模糊查询,比如
like %AB这种情况,因为没有一种索引支持这种形式,前缀索引的话需要一开始的字符清晰 - 组合索引之中直接跳过第一个索引或者不按照组合索引的顺序来
- 条件之中有 or,直接跳过索引的情况使用全表查询。
- 索引无法存储 null 值,所以如果 where 的条件对于 null 做了判断,那么直接导致其放弃索引而进行全表查询。(索引是有序的,如果将NULL进入索引,不确定其可以放在哪)
- in 和 not in, 比如
select id from t where num in(1,2,3)这种会直接不使用索引进行全表扫描。 - 在 where 的语句之中对字段进行函数操作,会导致引擎直接放弃使用索引而进行全表扫描。
大概就是这六点,总结下来就是只要不是确定的情况(使用or,判断 null值,in 和 not in,where 之中使用函数操作),或者和索引应该使用的情况不对(比如前缀索引不带前缀用like,或者是组合索引使用的顺序不对),都会导致不可以使用索引。
2.5 MySQL的主从同步过程?如何加入一台新机器到从机之中?
一台新的从机加入到从机群之中的步骤:
- slave 的 IO 线程连接到 master 端,并且请求从指定的 binlog 日志文件的指定 pos 节点位置开始复制之后的内容
- master 节点开始复制,并且记录在此期间接收到的sql,在复制完成之后一起打包发给slave,其中还包括了最后的节点信息,下次要从哪个节点的位置开始等等
- slave 在拿到这些消息之后,直接进行sql语句的执行。
下次slave 再去发送从请求的部分开始发送binlog,那么可见其本身一直是 slave在拉取而非 master推
3. 数据结构
3.1 ConcurrentHashmap
https://www.cnblogs.com/zerotomax/p/8687425.html
3.2 Queue和Stack
Queue在Java之中只是一个接口,如图:

但是Stack却是一个类,比如:

两种实现方式的不同就确定了其使用方式的不同:
对于Queue而言,其要使用LinkedList来实现,其实Queue就是将LinkedList 之中的方法限定成只有queue之中有的:
- boolean add(T t): 其作用是加入一个元素,要么返回true,要么抛出Exception。其是直接继承的Collection之中的方法;和boolean offer()相比,offer() 是在其正确插入的情况下返回true,非正确插入的情况下返回false。
- T remove(): 一般都是辨析其和 poll() 的区别,其中主要区别就是当Queue为空的时候,poll() 返回的是null,但是remove直接抛出异常。
- T peek(): 返回头部的元素,其和remove() 的区别在于其不会删除头部的元素,peek,看一看之意。
但是对于Stack而言,其是一个类,所以可以直接实例化:
- T pop(): 和remove一样
- T push(): 和add一样,但是其返回值是刚刚加入的这个值。
- T peek(): 瞧一眼栈顶元素,和之前讲的是一样的。
3.2.1 如何使用stack实现queue? 如何使用queue实现stack?
如何使用stack实现queue?Leetcode 232
用两个栈,一个instack,一个outstack。每次都只对instack做操作,除了queue的add方法:
先将instack全都pop到outstack 之中,然后将值push进outstack 之中。最后将outstack 之中的值全都pop()进instack,那么最先加入的值就会在instack的最下方
class MyQueue {
Stack<Integer> instack;
Stack<Integer> outstack;
/** Initialize your data structure here. */
public MyQueue() {
instack = new Stack<Integer>();
outstack = new Stack<Integer>();
}
/** Push element x to the back of queue. */
public void push(int x) {
while(!instack.isEmpty()){
outstack.push(instack.pop());
}
outstack.push(x);
while(!outstack.isEmpty()){
instack.push(outstack.pop());
}
}
/** Removes the element from in front of queue and returns that element. */
public int pop() {
return instack.pop();
}
/** Get the front element. */
public int peek() {
return instack.peek();
}
/** Returns whether the queue is empty. */
public boolean empty() {
return instack.isEmpty() && outstack.isEmpty();
}
}
/**
* Your MyQueue object will be instantiated and called as such:
* MyQueue obj = new MyQueue();
* obj.push(x);
* int param_2 = obj.pop();
* int param_3 = obj.peek();
* boolean param_4 = obj.empty();
*/
如何使用queue实现stack?
每次先加入一个数,此时的数在queue的末尾,然后:
public void push(int x) {
queue.add(x);
int size = queue.size();
while(size>1){
queue.add(queue.remove());
size--;
}
}
这样循环操作就可以了。其他的都是单步操作。
4. Java基础类型
4.1 String是不可变的到底是什么意思?什么情况下用final修饰?String不可变的作用是什么?
先回答第二个问题:
- 如果一个class用final修饰,那么意味着其不可以被其他的类继承
- 如果一个变量用final修饰,那么意味着其指向的地址不可以改变。
第一点很清晰,第二点呢?
比如我一个 arraylist,会在栈之中保存一个地址,链接到堆之中的真正的List的内容区域部分。那么只是指向的地址不可变,像下面这样是不可以的:
final int[] value={1,2,3};
int[] another={4,5,6};
value=another; //编译器报错,final不可变
但是我直接骚操作:
final int[] value={1,2,3};
value[2]=100; //这时候数组里已经是{1,2,100}
那为什么说String是不可变的呢?String本质就是一个char数组,那么也就是可以去改变其中内容的啊?
第一个问题答案来了:
private final char value[]这一句里,private的私有访问权限的作用都比final大。而且设计师还很小心地把整个String设成final禁止继承,避免被其他人继承后破坏。所以String是不可变的关键都在底层的实现,而不是一个final。
这答案就出来了,是因为在String内部的所有方法都没有动这个final,而且其还是private的,外部的类无法操作,这样才会实现”String是不可变的“这样一个结果。
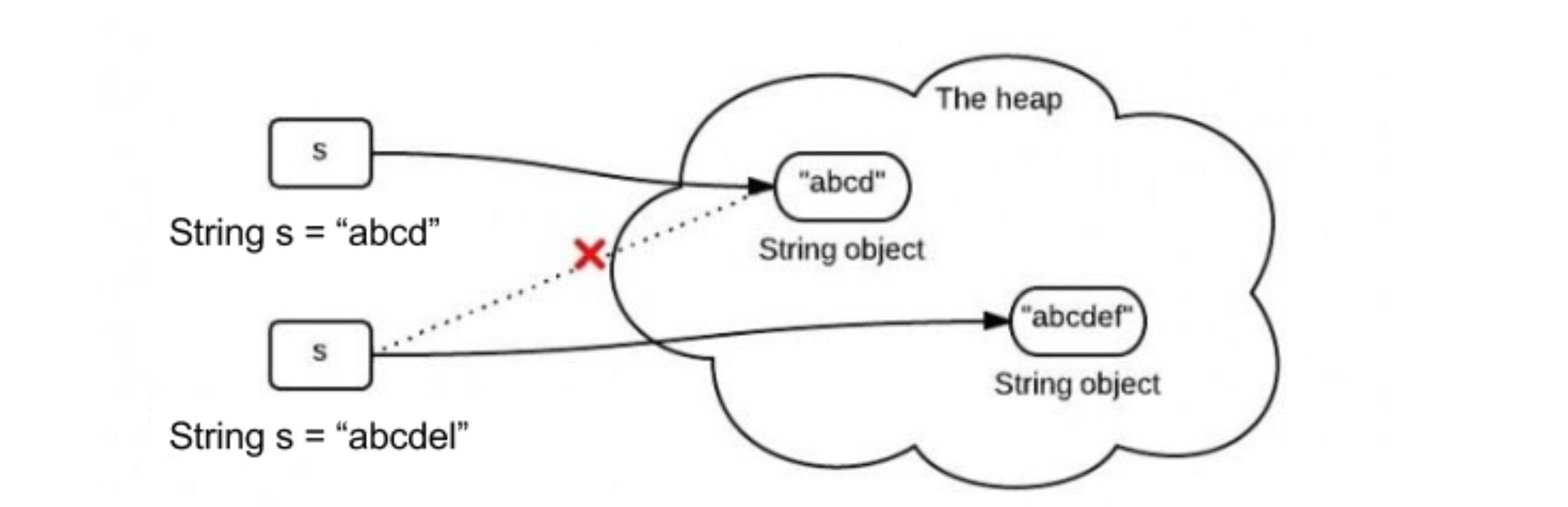
所以如上图所示,每次我们只要对字符串的值做一些修改,那么其就会生成一个新的字符串,并且修改当前的 s 指针所指向的位置。
现在回答第三个问题了:
- 对于字符串的判断有作用:假设String是可变的,那么如果程序员将这个字符串变量s传入函数,再将值进行修改,那么会造成全局的此字符串的改动,如果其和判断相关,那么就GG
- String常用做key,如果可以修改,像StringBuffer那样,那么:
HashSet<StringBuilder> hs = new HashSet<StringBuilder>();
StringBuilder sb1 = new StringBuilder("aaa");
StringBuilder sb2 = new StringBuilder("aaabbb");
hs.add(sb1);
hs.add(sb2); //这时候HashSet里是{"aaa","aaabbb"}
StringBuilder sb3=sb1;sb3.append("bbb"); //这时候HashSet里是{"aaabbb","aaabbb"}
System.out.println(hs);}}//Output:[aaabbb, aaabbb]
就会出现这样灾难性的后果,因为set只是在插入的时候做一下判断,这样就会导致其内部出现相同key的灾难情况。
5. 网络
5.1 DNS是通过什么传输的?为什么?
DNS一开始的设计是通过UDP进行传输,然后在其报文太大被切分的情况,或者是UDP没能收到完整报文的情况之下, 使用TCP来进行重传。或者是在区域之间的DNS传输的时候使用TCP。因为在一开始设计的时候,没有考虑到网络攻击的情况,且那时候的DNS报文都比较小,如果使用TCP传输,三次握手四次挥手和之中沟通过程的请求头的开销是不可忽视的。
但是后来,随着IPv6的引进和DNS信息的越来越大,标准也改成了使用TCP和UDP,TCP不再是UDP的备选方案。在复杂的网络环境面前,TCP的可靠性显得更为重要,且传输的内容越大,三次握手四次挥手的占比就越小。后来为了安全,还出现了DNS over TLS, DNS over HTTP等。
5.2 TIME_WAIT 状态过多该怎么办?
可以使用 netstat -tan 来获取所有活跃的连接,真的不得不去处理 TIME_WAIT 状态的话,可以:
- 用
net.ipv4.tcp_tw_reuse选项,通过 TCP 的时间戳选项允许内核重用处于TIME_WAIT状态的 TCP 连接; - 修改
net.ipv4.ip_local_port_range选项中的可用端口范围,增加可同时存在的 TCP 连接数上限;