参考资料:Java3y的文章。
以后,对于基础知识点的梳理,我都会通过五问:是什么?有什么特性?怎么用?怎么实现?有什么坑(使用的时候要注意什么)?
1. 为什么要使用多线程?
首先,目前的CPU一般都是多核的,如果在多核CPU上同一时刻只跑一个线程,那未免太浪费了。另外,对于IO密集型操作,CPU等待IO的时间比较长,这段时间其实也是浪费掉了的。那么多线程就可以有效的利用多核或者IO的等待时间。
2. 多线程有哪些地方需要注意?
多线程的花活玩法比如线程池,在数据库连接的过程之中我们就使用了线程池+ThreadLocal。线程池之中始终有活跃的连接线程,ThreadLocal之中保存线程,那么就可以保证对于当前线程而言,每一次拿到的连接都是同一个。
线程池之中始终保持多个活跃的连接线程,意义是在多线程访问的时候可以提供不止一条连接,同时防止频繁的建立和断开连接的操作。省去了每次的三次握手四次挥手等等。
使用线程池的时候,往往我们的调用方都不需要考虑请求是否立马处理成功。假设线程池在处理任务的时候因为某些原因失败了,我们可以走报警机制(用邮件/短信等渠道去提醒请求方即可)。
不知道大家学过消息队列了没有,我们常常说消息队列是异步的,很多时候调用方的请求我们丢到消息队列里边,就告诉调用方我们这条请求处理成功了。实际上,这个请求可能还交由下游的多个系统去处理,下游的系统可能也是异步的…..
在使用线程池的时候,很多时候我们也是把他当做异步来使,只要我们的系统之间交互不是强一致性的,又希望提高系统的吞吐量,我们就可以考虑使用线程池。
上面这段引用之中就说明了,想要提高吞吐量,又不在意强一致性,不需要同步的情况下,就可以使用线程池。
3. ThreadLocal
3.1 什么是ThreadLocal?
我们都知道JVM之中,线程共享进程的很多东西,实际上自己独立的部分除去JVM栈,本地方法栈和程序计数器之外啥都没有,可怜的一批。那么如果在某些情况,比如上文说到的这种数据库连接的情况下想维持自己的一个connection,那么就得使用ThreadLocal。ThreadLocal是属于每个线程的一个副本,其不受其他线程所影响。
ThreadLocal提供了线程的局部变量,每个线程都可以通过
set()和get()来对这个局部变量进行操作,但不会和其他线程的局部变量进行冲突,实现了线程的数据隔离~。
3.2 ThreadLocal的一些好处?
比如上文之中讲的其在线程内部保存一些变量,对每个线程而言数据库的连接是唯一且稳定的之外,还有避免参数传递的作用:其只是每个Thread内部具有的值,那么传递参数的时候就不需要再去选择Thread,而是直接在当前的Thread之中拿取就好了。
3.3 ThreadLocal的实现原理
Talk is cheap, show me the code:
首先看ThreadLocal 的 set 方法:
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
看到这边有个ThreadLocalMap,点进去看下:
static class ThreadLocalMap {
/**
* The entries in this hash map extend WeakReference, using
* its main ref field as the key (which is always a
* ThreadLocal object). Note that null keys (i.e. entry.get()
* == null) mean that the key is no longer referenced, so the
* entry can be expunged from table. Such entries are referred to
* as "stale entries" in the code that follows.
*/
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
//下面是维护相关的部分,和主题关系不大,省略~
可以看到ThreadLocal是Thread的一个内部类,其中存放的是Entry,一个以ThreadLocal为key,以Object为value的一个对。这个thread有啥关系?再看!
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}
上面这个getMap方法之中,返回的是Thread的threadLocals。那这又是啥?
/* ThreadLocal values pertaining to this thread. This map is maintained
* by the ThreadLocal class. */
ThreadLocal.ThreadLocalMap threadLocals = null;
原来返回的部分就是ThreadLocal之中的 ThreadLocalMap。
那么再看上面的 set 方法就很清晰了。
在Thread类之中,有一个
/* ThreadLocal values pertaining to this thread. This map is maintained
* by the ThreadLocal class. */
ThreadLocal.ThreadLocalMap threadLocals = null;
注意,是在Thread里面哈。
那么每一个Thread都有一个ThreadMap,首先通过 getMap(t) 来拿到当前Thread t的一个ThreadMap,如果其不是null,那么说明已经创建好了,就用当前的ThreadLocal当做key,以要存放的Object当做Value来存放在这个map里面。不然就初始化这个ThreadLocalMap并且将值放入其中。
ThreadLocal本身并不存储值,它只是作为一个key来让线程从ThreadLocalMap获取value。
那么这样就可以做到线程之间的隔离,因为ThreadLocalMap就是对于每个线程独有的,怎么可能会让别的线程看到其中的值呢?
3.4 ThreadLocal的内存泄露
ThreadLocal的内存泄露原因是,ThreadLocal的生命周期和Thread一样长,如果没有手动去remove() 对应的key,那么其就会一直存在,久而久之就会内存泄露。
4. 多线程
4.1 为什么要有线程?
我们都知道,在计算机领域,一个程序就是一个进程,可以独立执行。那么为什么还要线程呢?是因为进程的切换之中过于重量级,那么引入线程作为调度的最小单位,就可以减少调度切换的时间,使OS具有更好的并发性。
4.2 线程的基本属性和类型
线程的基本属性有:
- 独立调度和分配的基本单位
- 可并发执行
- 共享进程的资源
类型:
- 用户级线程:用户自行管理,OS只对进程负责
- 系统级线程:由OS内核管理,OS内核给程序提供相应的系统调用和API,让用户可以创建,执行和撤销线程。注意,此处没有“管理”。
4.3 多线程的意义
多线程实际是为了提高程序的使用率,比如在IO密集型的程序之中提高吞吐量。即使线程的切换比进程的切换要省很多资源,但是也还是需要一定的资源,并且CPU同时也只能执行一个线程。
引入线程主要是为了提高系统的执行效率,减少处理机的空转时间和调度切换的时间,以及便于系统管理。使OS具有更好的并发性
此处处理机的空转时间指的就是阻塞的时间,而调度的时间就是切换进程所需要的时间。
4.4 多线程的实现方式
有两种:
- 继承 Thread,重写 run() 方法
- 实现 Runnable 接口,重写 run() 方法,然后将自己写的Runnable接口传递到Thread之中。
第一种:
package UseToStudyJavaClass.ThreadStudy;
public class MyThread extends Thread{
@Override
public void run(){
for(int i=0;i<10;i++){
System.out.println(i);
}
}
}
package UseToStudyJavaClass.ThreadStudy;
public class MyThreadDemo {
public static void main(String[] args) {
MyThread mt1 = new MyThread();
MyThread mt2 = new MyThread();
mt1.start();
mt2.start();
}
}
结果会交替打印,但是最终都是输出从0到9的结果。
第二种:
package UseToStudyJavaClass.ThreadStudy;
public class MyRunnable implements Runnable {
@Override
public void run(){
for(int i=21;i<400;i++){
System.out.println(i);
}
}
}
package UseToStudyJavaClass.ThreadStudy;
public class MyThreadDemo {
public static void main(String[] args) {
MyRunnable mr1 = new MyRunnable();
Thread t1 = new Thread(mr1);
Thread t2 = new Thread(mr1);
t1.start();
t2.start();
}
}
可见其为新建Thread,并且将Runnable的接口传进去。
打印的结果也是一样,交替进行,但是最终都会打出来一样的结果。
4.5 多线程的实现需要注意的细节
4.5.1 run() 和 start() 的方法区别
-
run() 是直接跑一遍线程内部的代码,跑完就结束了,和普通代码没什么不同
-
start() 是启动线程,然后由 JVM 来执行其 run() 方法。
4.5.2 JVM的启动是单线程还是多线程的?
JVM 的启动是多线程的。至少不仅有main线程,还有一个GC线程,不然谁来执行扫描呢?
4.5.3 一般用哪种方式实现多线程?
一般我们会使用实现 Runnable 接口的方法,原因有两点:
- Java 之中是不允许多重继承的,使用实现接口的方法可以避免这个限制。
- 应该实现运行机制和运行任务解耦,说白了,线程的执行和线程的执行任务本身应该尽量去分离。
5. Thread 源码剖析
5.1 起名和改名
Thread的名字不可以为空,不然会报NPE。如果在创建的时候没有给名字,那么会自动以“Thread-xxxxxx”的格式来起名,其中xxxx是递增的,源码如下:
/**
* Allocates a new {@code Thread} object. This constructor has the same
* effect as {@linkplain #Thread(ThreadGroup,Runnable,String) Thread}
* {@code (null, null, gname)}, where {@code gname} is a newly generated
* name. Automatically generated names are of the form
* {@code "Thread-"+}<i>n</i>, where <i>n</i> is an integer.
*/
public Thread() {
init(null, null, "Thread-" + nextThreadNum(), 0);
}
其中的 nextThreadNum() 为:
/* For autonumbering anonymous threads. */
private static int threadInitNumber;
private static synchronized int nextThreadNum() {
return threadInitNumber++;
}
那么可以看到其本身就是递增的。这个threadInitNumber也是从0开始,这样就可以避免重名的现象。注意到那个synchronized没?保证多线程条件下也是可用的。
那么如果想给线程起个名呢?
MyRunnable mr1 = new MyRunnable();
Thread t1 = new Thread(mr1,"名字1");
Thread t2 = new Thread(mr1,"名字2");
t1.setName("我改名了");
这样就可以了。要么在新建Thread 的时候直接给名字,要么使用setName()方法进行改名。
/**
* Changes the name of this thread to be equal to the argument
* <code>name</code>.
* <p>
* First the <code>checkAccess</code> method of this thread is called
* with no arguments. This may result in throwing a
* <code>SecurityException</code>.
*
* @param name the new name for this thread.
* @exception SecurityException if the current thread cannot modify this
* thread.
* @see #getName
* @see #checkAccess()
*/
public final synchronized void setName(String name) {
checkAccess();
if (name == null) {
throw new NullPointerException("name cannot be null");
}
this.name = name;
if (threadStatus != 0) {
setNativeName(name);
}
}
再点进去,发现其首先要checkAccess(),即目前正在运行的线程是否有修改这个线程名字的权限。还有个threadStatus,这个东西在Thread源码之中的所有部分都没有被修改过,但是还经常会判断其是否为0,源码如下:
/* Java thread status for tools,
* initialized to indicate thread 'not yet started'
*/
private volatile int threadStatus = 0;
可见0代表其“还没修改”。那在哪被修改了呢?
参考:https://redspider.gitbook.io/concurrent/di-yi-pian-ji-chu-pian/4
// sun.misc.VM 源码:
public static State toThreadState(int var0) {
if ((var0 & 4) != 0) {
return State.RUNNABLE;
} else if ((var0 & 1024) != 0) {
return State.BLOCKED;
} else if ((var0 & 16) != 0) {
return State.WAITING;
} else if ((var0 & 32) != 0) {
return State.TIMED_WAITING;
} else if ((var0 & 2) != 0) {
return State.TERMINATED;
} else {
return (var0 & 1) == 0 ? State.NEW : State.RUNNABLE;
}
}
5.1.1 关于start()的两个引申问题
- 反复调用同一个线程的start()方法是否可行?
- 假如一个线程执行完毕(此时处于TERMINATED状态),再次调用这个线程的start()方法是否可行?
先上start() 的源码:
public synchronized void start() {
if (threadStatus != 0)
throw new IllegalThreadStateException();
group.add(this);
boolean started = false;
try {
start0();
started = true;
} finally {
try {
if (!started) {
group.threadStartFailed(this);
}
} catch (Throwable ignore) {
}
}
}
这两个问题和上面的threadStatus息息相关,其答案如下:
- 不可行。因为在调用完一次start() 之后其内部的threadStatus 就改变不为0了,那么这种情况下其判断不为0就会直接抛出异常。
- 不可行。threadStatus为2代表当前线程状态为TERMINATED。那么判断其不为0,还是会直接抛出异常。
我们现在再回到上面那个改名的部分:
如果threadStatus为0,意味着其还没有初始化,那么直接set this.name=name就完事了。但是如果不为0,那么意味着已经不在初始化状态了,就要进入下面的setNativeName(name) 方法之中。这个native方法就是JVM内部的方法,java源码之中已经不包括了。
这里有个很有趣的现象:可能会有指令重排序,比如我这段代码输出的结果可能不同:
package UseToStudyJavaClass.ThreadStudy;
public class MyThreadDemo {
public static void main(String[] args) {
System.out.println(Thread.currentThread().getName());
MyThread mt1 = new MyThread();
MyThread mt2 = new MyThread();
mt1.start();
mt2.start();
MyRunnable mr1 = new MyRunnable();
Thread t1 = new Thread(mr1,"名字1");
Thread t2 = new Thread(mr1,"名字2");
t1.start();
t2.start();
t1.setName("我改名了1");
System.out.println(t1.getName());
}
}
其可能为:
main
MyThread Thread-1
MyThread Thread-0
我改名了1
MyRunnable 名字2
MyRunnable 我改名了1
也可能为:
main
MyThread Thread-0
MyThread Thread-1
MyRunnable 名字1
我改名了1
MyRunnable 名字2
5.2 守护线程
守护线程也就是服务线程,当主线程和其他所有线程都结束的时候守护线程会自动结束。比如GC线程就是一种守护线程。
守护线程的使用方法是thread.setDaemon(true)。
使用守护线程要注意的地方:
- 守护线程必须在本线程启动之前就设置好
- 守护线程永远不要访问共享资源(比如数据库或者文件),因为可能一半就挂了。
- 守护线程之中产生的新线程也是守护线程
public final void setDaemon(boolean on) {
checkAccess();
if (isAlive()) {
throw new IllegalThreadStateException();
}
daemon = on;
}
如果在线程启动之后再设置,那么其会抛出IllegalThreadStateException()。比如下面这段就会:
MyRunnable mr1 = new MyRunnable();
Thread t1 = new Thread(mr1,"名字1");
Thread t2 = new Thread(mr1,"名字2");
t1.start();
t2.start();
t2.setDaemon(true);
5.3 线程优先级
线程优先级只是代表其获得CPU时间片的几率更高,而不是高优先级的线程一定会在低优先级的线程之前完成任务。
/**
* The minimum priority that a thread can have.
*/
public final static int MIN_PRIORITY = 1;
/**
* The default priority that is assigned to a thread.
*/
public final static int NORM_PRIORITY = 5;
/**
* The maximum priority that a thread can have.
*/
public final static int MAX_PRIORITY = 10;
java之中默认的优先级是5,最小1,最大10。可以使用setPriority()实现。
public final void setPriority(int newPriority) {
ThreadGroup g;
checkAccess();
if (newPriority > MAX_PRIORITY || newPriority < MIN_PRIORITY) {
throw new IllegalArgumentException();
}
if((g = getThreadGroup()) != null) {
if (newPriority > g.getMaxPriority()) {
newPriority = g.getMaxPriority();
}
setPriority0(priority = newPriority);
}
}
首先检查是否超过最小最大范围,之后如果这个线程是属于线程组的,那么优先级不得高于此线程组。最后,直接一个native方法搞定。
这个线程组又是啥呢?线程是它的创建者的线程组的成员。其作用是为了确定权限,Gosling的说法:“线程组中的线程可以修改组内的其他线程,包括那些位于分层结构最深处的。一个线程不能修改位于自己所在组或者下属组之外的任何线程”。
5.4 线程的生命周期
5.4.1 sleep() 方法
sleep方法会进入计时等待状态,时间到了,进入的就是就绪状态。
5.4.2 yield() 方法
yield() 方法会让别的线程先执行,但是不保证真正让出。比如可能让出之后CPU又选择当前线程来执行任务。yield() 方法调用后进入等待状态,结束之后进入就绪状态。
5.4.3 join() 方法
调用其他线程 t1 的join() 方法,会让当前线程等待t1线程执行结束之后再开始执行。其原理就是:让当前的线程不断的去wait(0),在wait() 之中意味着永久等待,然后在t1线程结束之后使用notifyAll() 的方法去唤醒。
/**
* Waits at most {@code millis} milliseconds for this thread to
* die. A timeout of {@code 0} means to wait forever.
*
* <p> This implementation uses a loop of {@code this.wait} calls
* conditioned on {@code this.isAlive}. As a thread terminates the
* {@code this.notifyAll} method is invoked. It is recommended that
* applications not use {@code wait}, {@code notify}, or
* {@code notifyAll} on {@code Thread} instances.
*
* @param millis
* the time to wait in milliseconds
*
* @throws IllegalArgumentException
* if the value of {@code millis} is negative
*
* @throws InterruptedException
* if any thread has interrupted the current thread. The
* <i>interrupted status</i> of the current thread is
* cleared when this exception is thrown.
*/
public final synchronized void join(long millis)
throws InterruptedException {
long base = System.currentTimeMillis();
long now = 0;
if (millis < 0) {
throw new IllegalArgumentException("timeout value is negative");
}
if (millis == 0) {
while (isAlive()) {
wait(0);
}
} else {
while (isAlive()) {
long delay = millis - now;
if (delay <= 0) {
break;
}
wait(delay);
now = System.currentTimeMillis() - base;
}
}
}
5.4.4 interupt() 方法
5.4.4.1 为什么stop() 方法被设置成过时了?
stop() 是暴力终止,那么如果线程A终止掉线程B:
- 被终止掉的线程会立刻释放锁,可能会让对象处于不一致的状态。
- 线程A并不知道线程B在干嘛,万一B还在运行计算阶段就被终止,会造成问题
过于危险,所以被过时了。
interrupt() 有什么不同呢?
Interrupt() 只是请求终止一个线程B,相当于发出结束信号,然后由B自己去抓取信号来决定要做什么,甚至可以忽略。
5.4.4.2 interrupt() 如何实现?如何使用?
- interrupt() 要么线程自己中断自己,要么会checkAccess(),不然
SecurityException - 如果线程被阻塞,比如sleep(), wait(),join(),或者是被I/O 阻塞,那么直接抛出异常,因为既然阻塞掉了线程就没法对interrupt()做反应了。中断一个不活动的线程无意义。
public void interrupt() {
if (this != Thread.currentThread())
checkAccess();
synchronized (blockerLock) {
Interruptible b = blocker;
if (b != null) {
interrupt0(); // Just to set the interrupt flag
b.interrupt(this);
return;
}
}
interrupt0();
}
代码逻辑:先看有无权限,再看是否阻塞,最后设置一个interrupt()标志位结束。
5.4.4.3 interrupt() 的检查方法?
别人都只有一个,他有俩:
- 静态方法interrupted()–>会清除中断标志位
- 实例方法isInterrupted()–>不会清除中断标志位
public static boolean interrupted() {
return currentThread().isInterrupted(true);
}
public boolean isInterrupted() {
return isInterrupted(false);
}
其中都用到的:
/**
* Tests if some Thread has been interrupted. The interrupted state
* is reset or not based on the value of ClearInterrupted that is
* passed.
*/
private native boolean isInterrupted(boolean ClearInterrupted);
可见就是同一个函数选择是否清除interrupted 标志位而已。
搞个中断sleep()状态从而抛出异常的代码:
package UseToStudyJavaClass.ThreadStudy;
public class TestRunnableDemo {
public static void main(String[] args) {
TestRunnableDemo testRunnableDemo = new TestRunnableDemo();
Thread t = new Thread(testRunnableDemo.runnable);
System.out.println("This is main");
t.start();
try {
System.out.println("Thread is " + Thread.currentThread().getName());
Thread.sleep(3000);
} catch (InterruptedException e) {
System.out.println("In main");
e.printStackTrace();
}
t.interrupt();
}
Runnable runnable = () -> {
int i = 0;
try {
while (i < 1000) {
System.out.println("In t " + Thread.currentThread().getName() + " " + i);
Thread.sleep(500);
i++;
}
} catch (InterruptedException e) {
System.out.println(Thread.currentThread().getName() + " " + Thread.currentThread().isAlive() + " " + Thread.currentThread().isInterrupted());
e.printStackTrace();
}
};
}
输出:
This is main
Thread is main
In t Thread-0 0
In t Thread-0 1
In t Thread-0 2
In t Thread-0 3
In t Thread-0 4
In t Thread-0 5
Thread-0 true false
java.lang.InterruptedException: sleep interrupted
at java.lang.Thread.sleep(Native Method)
at UseToStudyJavaClass.ThreadStudy.TestRunnableDemo.lambda$new$0(TestRunnableDemo.java:28)
at java.lang.Thread.run(Thread.java:748)
代码逻辑:
主线程开启之后睡3秒,那么Thread t就会开启。t的逻辑是睡半秒输出一句。由于输出部分耗时极小,可以看做大部分时间都在sleep()。3秒之后主线程醒了执行t.interrupt(),直接Interrupt()了sleep的t,导致抛抛出异常。注意,最后输出的Thread t的状态是isAlive. 但是没interrupt。
6. 多线程的必要知识点
6.1 对象的发布和逸出
对象的发布和逸出都是让对象在当前作用域之外的范围使用,只是”发布“是正面的,是主动暴露的,但是逸出是负面的, 是不想被暴露但是被暴露的。
常见的逸出方式:
- 静态域逸出:
- public 修饰的 get() 方法
- 参数传递逸出
- this逸出
下面分点来讲:
- 静态域逸出:原因就是静态域相当于发布了对象,那么未初始化的时候就已经可以使用对应对象了。
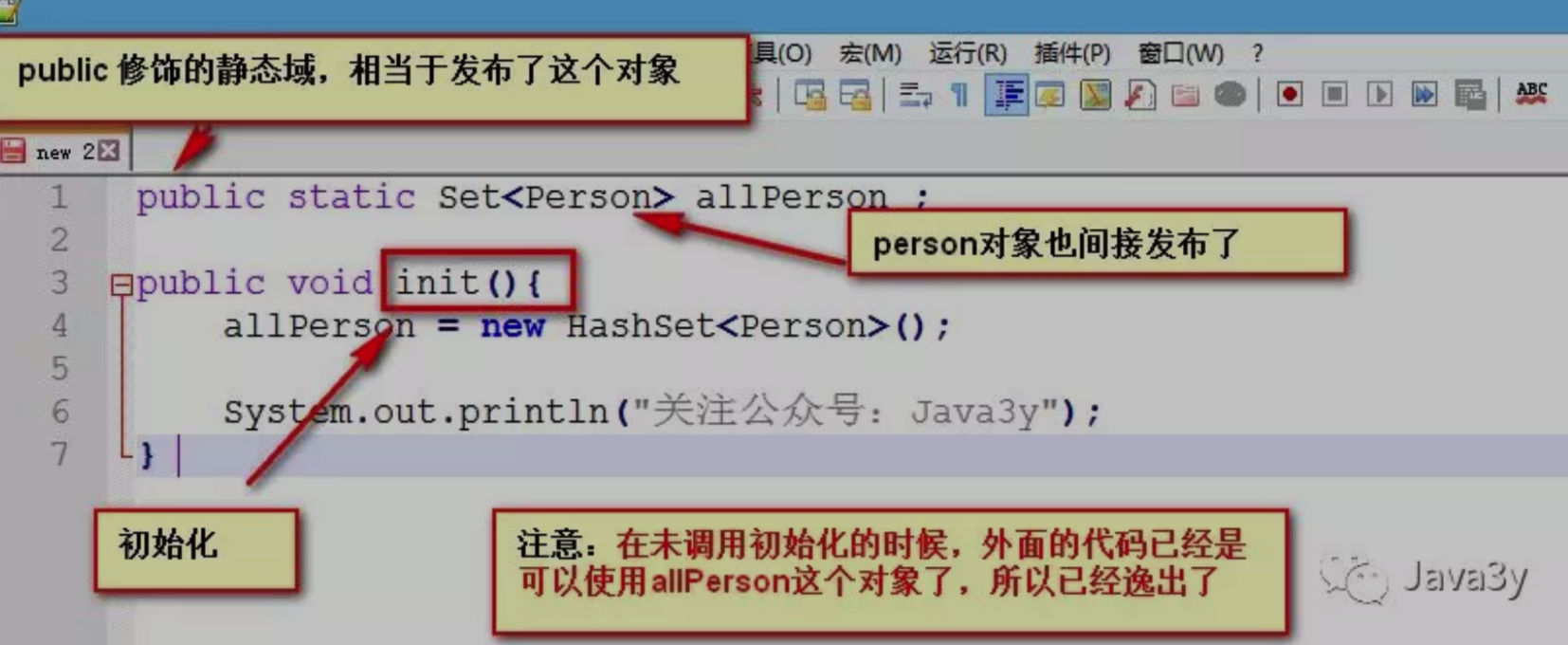
-
public 修饰的 get() 方法–> 导致private修饰的变量不安全
-
参数传递逸出:都把参数传进去了,当然逸出了。
-
this逸出:多线程的情况下, 可能相应的变量还没初始化完成,另一个线程就已经调用了这个对象,比如:

6.1.1 对象如何安全发布
也就是说:如何避免”我还没初始化变量你就用“发生。有两种大方法:
- 一开始就初始化所有要发布的变量
- 让变量没发布的情况可见,或者线程顺序访问此变量。
这两个大方法下面有四个小方法:
- 在静态域之中直接初始化:
public static person = new Person();- 静态初始化是JVM在类的初始化阶段就执行了,JVM内部有同步机制,那么我们可以安全发布对象
- 对应的引用保存在volitile 或者 AtomicReference 之中,保证对象的可见性或者原子性。
- 加锁。加锁是避免所有线程冲突的最后一招。
6.2 如何保证线程安全?
线程不安全主要在共享的变量上面,那么有两个大的解决方法:要么干脆别共享,要么加锁或者原子性保证同一时刻只有一个线程在访问此变量。
- 无状态:没共享变量
- 使用final使对象不可变:也是第一种思路,干脆就按照初始值来,别共享。
- 加锁
- 使用JDK提供的原子性,比如AtomicLong来实现++ 操作,或者CAS的类比如ConcurrentHashMap
6.3 线程封闭
Servlet是如何实现多线程的呢?
Servlet本身没有任何状态共享,而且其所有的数据都是在方法内serve(HttpServletRequest request, HttpServletResponse response) 之中操作的,那么其数据会全都在栈上,而且不会对外发布对象,当然线程和线程之间不会冲突。
6.4 不变性
不可变对象一定是线程安全的。注意,不可变对象不是final修饰的对象,因为final修饰仅仅是其地址不可变,比如指向一个ArrayList,但是ArrayList之中的内容是可变的。那么这种就不满足不变性。
前面在梳理的时候说了,String算是一个不可变的class,因为其内部的char数组是private final的,整个类也是final的,那么就没法通过继承来修改内部的变量,并且所有的方法都没有对这个数组进行修改操作。可以说String这个类是一个艺术品。
/** The value is used for character storage. */
private final char value[];
那么不变性的三条件:
- 对象创建之后状态不可修改
- 对象的所有域都是final修饰的
- 对象会正确创建,没之前讲的那种this溢出情况出现(对象还没建好就另一个线程拿来用)。
7. 锁
来了,鼎鼎大名的它来了!!!
7.1 Synchronized 锁是什么?
- Synchronized 锁是一种互斥锁,也是一种内置锁。
什么是内置锁?Java之中的每一个对象都有一个内置锁(监视器),Synchronized就是利用对象的内置锁来将对象锁定的。
- Synchronized保证了线程的可见性和原子性。原子性,是其块之中的代码一定被一起执行完毕。可见性,意味着其内部修改完的变量外部的其他线程是可见的。
7.1.1 monitorenter, monitorexit和acc_synchronized
首先明确:前两点是面向对象的,后一点是面向方法的。这三个部分都和monitor扯上关系。
先说hopSpot之中的对象布局:Header,Instance data和padding。其中padding是对齐数据,instance data之中是存储的真正有效信息还有父类的属性信息。这俩都和Synchronized无关。那么看header部分。
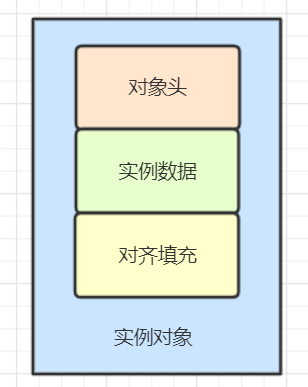
header里面主要就是两块:Mark word 和 Class pointer。
Class pointer显而易见,就是指向这个对象的类,JVM就是通过这个得到这个指针是哪个对象的实例。
mark word又是啥?标记字段?听起来是不是有点像标记状态?猜对了!
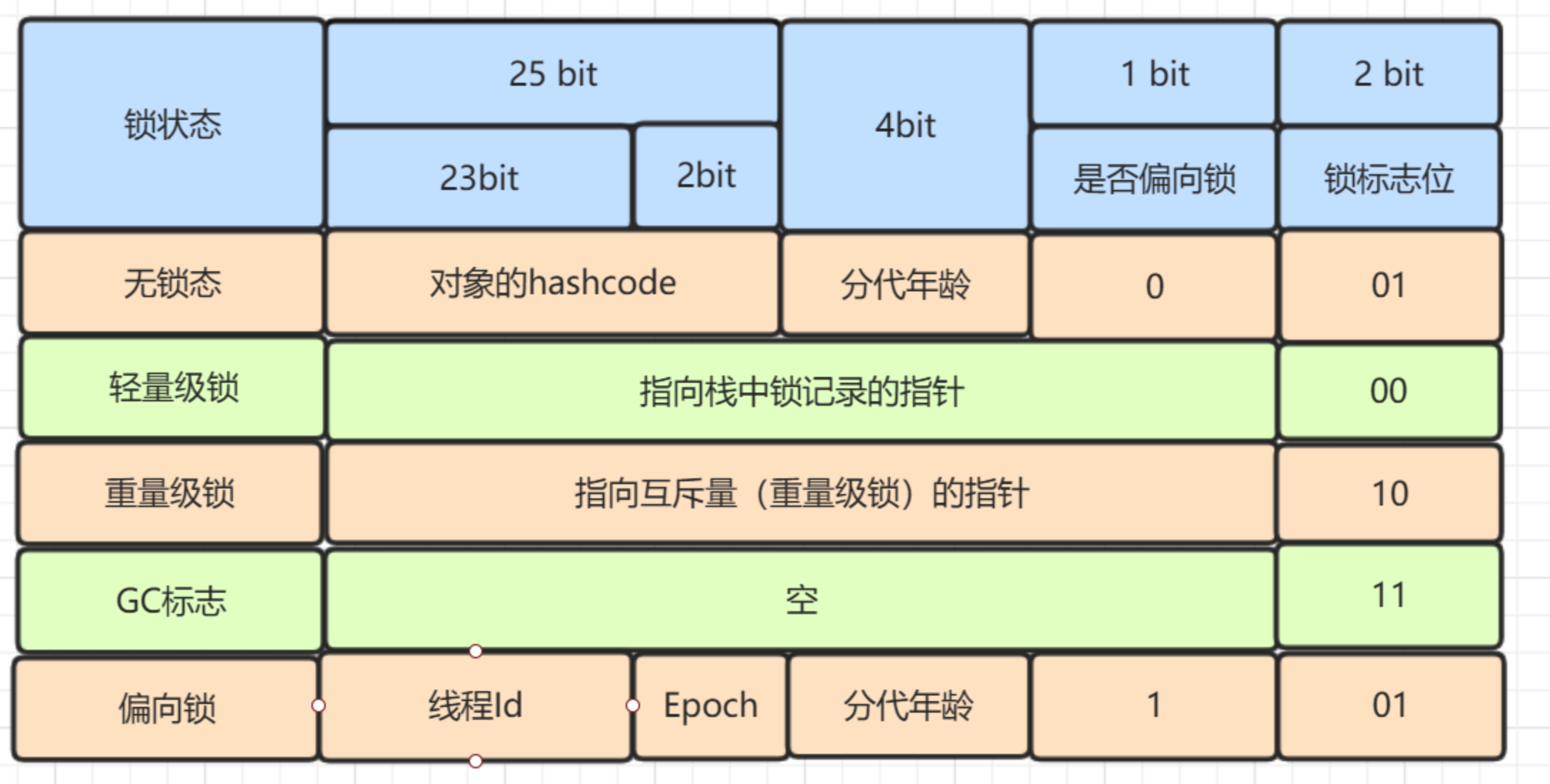
如果是重量级锁的状态,那么会直接保存重量级锁的指针,标志位变成10.所以,对象和monitor的关联方式,就是对象之中的对象头表明了自己是上锁,而且mark word里面指向了monitor。
ACC_SYNCHRONIZED 的实现,是通过标记符来隐式的实现,是调用该方法在常量池之中是否包含ACC_SYNCHRONIZED标记符。
7.1.2 monitor是什么?
刚才我们说了对象的头部的mark word 之中会有monitor的地址和锁的状态,那么monitor是啥?
先上结构:
ObjectMonitor() {
_header = NULL;
_count = 0; // 记录个数
_waiters = 0,
_recursions = 0; // 锁的重入次数
_object = NULL;
_owner = NULL; // 目前拥有锁的线程
_WaitSet = NULL; // 处于wait状态的线程,会被加入到_WaitSet
_WaitSetLock = 0 ;
_Responsible = NULL ;
_succ = NULL ;
_cxq = NULL ;
FreeNext = NULL ;
_EntryList = NULL ; // 处于等待锁block状态的线程,会被加入到该列表
_SpinFreq = 0 ;
_SpinClock = 0 ;
OwnerIsThread = 0 ;
}
别的都没啥用,看我写注释的五个:
- 目前和这个实例相关的线程
- 锁的重入次数
- 谁有锁?——在里面的线程
- 谁在wait()
- 谁在等待锁?注意,上面的wait()是wait状态,和这个不一样。
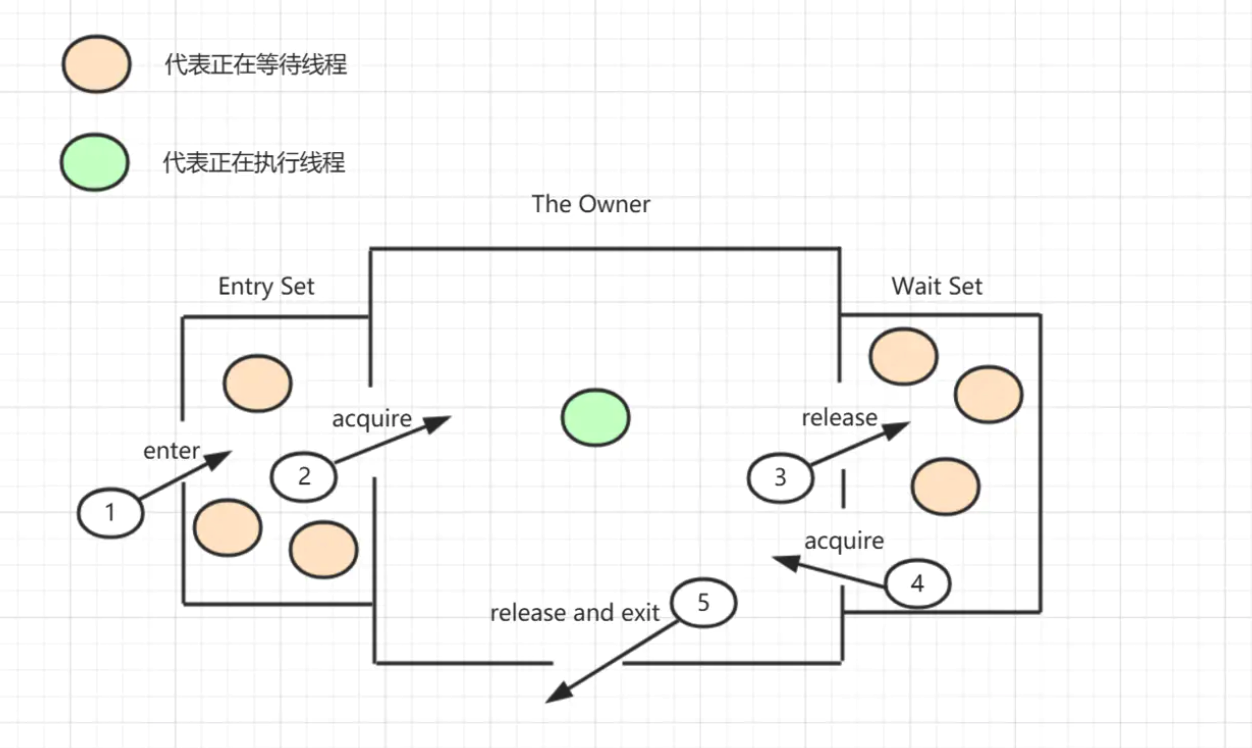
全过程:
-
首先想要获得monitor的线程,会进入_EntryList 队列。
- 某个线程拿到锁了,进入owner区域,count++
- 如果其调用了wait(),那么直接进入wait set, 释放锁——owner=null, count–,自己进入wait set之中阻塞等待。
- 如果其他线程调用notify()/notifyAll(),那么直接在wait set之中唤醒一个线程,其再次尝试拿取monitor锁。成功则重复第二步。
- 所有线程都执行完了,那么就直接线程退出临界区,将owner设置为null,并且释放监视锁。
回顾一下:
monitorentry: owner = 自己,count++
monitorexit: owner = null, count–,count为0则释放monitor
7.1.3 锁优化
7.1.3.1 自旋锁
解决:传统的阻塞锁之中,如果没有获得锁那么就阻塞,然后再次唤醒试图拿锁。但是线程的阻塞和唤醒需要在用户态和内核态切换,那么频繁的转换对CPU的负担是很重的。且一般而言锁只会持续一小段时间。
方案:那么就让线程无意义空循环一会,看看能不能拿到锁。如果几次都拿不到就自己直接挂起。
7.1.3.2 自适应自旋锁
每次自旋的次数不一定。根据上次的情况而变化。
7.1.3.3 阻塞锁
最传统。进入阻塞等待队列,等待别人notify() / notifyAll()
7.1.3.4 公平锁和非公平锁
不能插队/能插队。
7.1.3.5 锁粗化
检测是否有一连串的方法想要锁。如果有,那么就一起加锁,免得加锁释放锁造成浪费。
7.1.3.6 锁消除
没必要加锁的部分JVM通过分析之后会将锁去掉,比如在一个方法内部的对象不可能被几个线程拿到,那么就会直接消除掉其上的锁。
7.1.4 锁升级
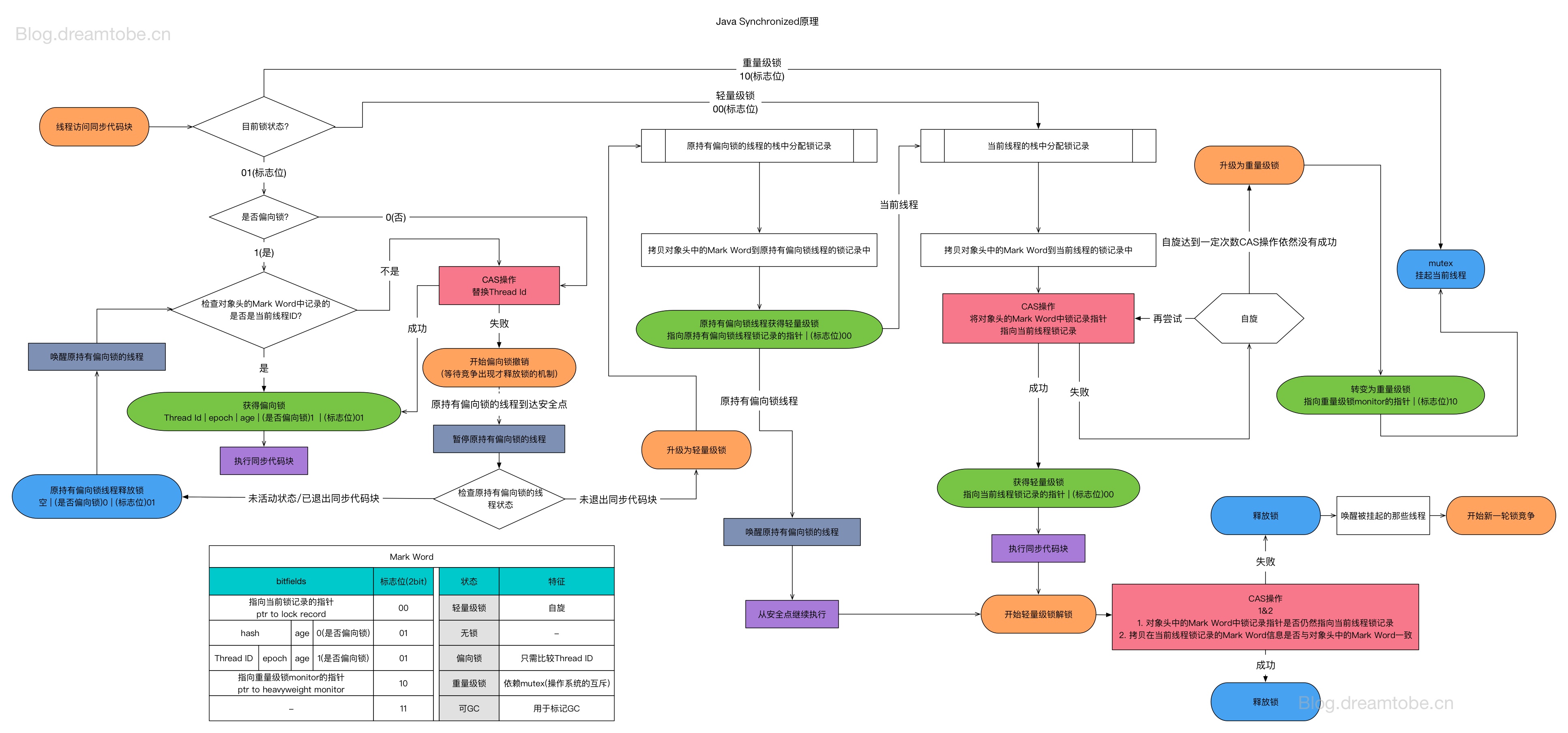
7.2 Synchronized 锁如何使用
- 修饰普通方法——用的是对象的内置锁
- 修饰代码块——用的是对象的内置锁
- 修饰静态方法——用的是类锁
其中类锁和对象锁的线程是不冲突的。
7.3 重入锁
参考:https://blog.csdn.net/aitangyong/article/details/22695399
public class Widget {
// 锁住了
public synchronized void doSomething() {
...
}
}
public class LoggingWidget extends Widget {
// 锁住了
public synchronized void doSomething() {
System.out.println(toString() + ": calling doSomething");
super.doSomething();
}
}
那么此处最后的一行,super.doSomething() 还需要去锁住父类吗?
实际上,创建子类的时候没有创建父类,super只是将父类之中的方法放入子类当中,那么其请求的锁还是LoggingWidgt的锁。那么本来就有锁了,再去请求自己的锁,这种就叫重入锁。
7.3 锁何时释放?
要么方法块执行完毕,要么线程出现异常的情况下会释放锁。不会因为异常就发生死锁现象。
7.4 Lock 显式锁
简单概括一下:
Lock是jdk提供的一个接口,在代码之中实现一个锁,然后线程需要去主动请求锁,这部分要程序员手动去写。由于是自己写的,所以更加灵活,可以实现:
- Lock方式来获得锁,支持中断,支持超时不获取,是非阻塞的。
- 提高了语义化,哪里加锁哪里释放锁都可以在代码之中写出来
- 支持Condition对象
- 允许多个读线程同时访问共享资源。
但是Lock的加锁和释放锁必须由程序员手动实现。
7.5 AQS
Lock锁的实现都是基于AQS的。
7.5.1 AQS是什么?有什么特性?
是什么?是位于juc包下面的一个AbstractQueuedSynchronizer类,java之中的锁都是以其为基础来实现的。
有什么特性?
- 定义了内部类 ConditionObject
- 有两种模式:共享模式和独占模式。其中ReentrantLock的读写锁中的读锁就是共享模式。
7.5.2 AQS之中有什么?
内部有一个先进先出的队列和一个volatile 的 int state表示状态。
先说state: 使用volatile修饰可见性,而且修改值的时候使用CAS算法实现。CAS的原子性是使用处理器的原子性实现的。所以可以保证这个state的修改是线程安全的(可见+原子)
再说这个先进先出的队列:
队列头的节点之中是当前持有锁的线程,节点之中标记有状态,其中SIGNAL状态表明的是其结束占用锁之后会去唤醒后面的线程。等待之中的线程就往后挨个排。
7.5.3 AQS是如何实现的?
最重要无非是加锁开锁两部分:
加锁:acquire(), 先尝试去获取资源,如果失败的话,线程插入等待队列。如果前置节点是头节点,而且其状态不是SIGNAL,那么会自旋尝试获取锁。如果不是头结点,或者是头结点但是状态为SIGNAL,那么就会中断当前线程,等待前置节点结束之后唤醒自己。
开锁:release(),先调用子类的tryRelease()方法释放锁,之后唤醒后继结点。如果后继结点作废了,那么就从tail() 开始往前查找到第一个不作废的并且唤醒。
8. 锁的子类
最主要的两个子类:ReentrantLock 和 ReentrantReadWriteLock
8.1 ReentrantLock
8.1.1 ReentrantLock是什么?
是一个可以和Synchronized同样的功能的锁,但是具有更好的扩展性。
8.1.2 ReentrantLock有什么特点?
- 比Synchronized更灵活
- 支持公平锁
8.1.3 ReentrantLock怎么用?
使用的标准用法是在try之前lock,在finally之中释放锁。
- 如何构造?其构造函数之中默认是非公平锁,也可以传参true在构造函数之中去构建公平锁。
/**
* Creates an instance of {@code ReentrantLock}.
* This is equivalent to using {@code ReentrantLock(false)}.
*/
public ReentrantLock() {
sync = new NonfairSync();
}
/**
* Creates an instance of {@code ReentrantLock} with the
* given fairness policy.
*
* @param fair {@code true} if this lock should use a fair ordering policy
*/
public ReentrantLock(boolean fair) {
sync = fair ? new FairSync() : new NonfairSync();
}
8.1.4 怎么实现?
非公平的lock方法:
先CAS state,失败之后直接调用AQS 的 acquire(1)。其中重写的 tryAcquire() 是空闲状态下获取锁,或者在重入锁的重入次数不overflow的时候直接进入锁。
公平的lock方法:
比非公平的方法多了一个状态条件的检查,很有趣,其名字是hasQueuedPredecessors,即“前面是否有节点等待”,那么我们要检查其是否为同步队列的第一个,就得把状态反过来,使用!hasQueuedPredecessors。所以公平的lock条件有两个:是否为第一个节点/CAS state是否成功。
unlock方法:
unlock 不分是否公平,因为公平的判断在lock部分已经判完了。
其实现方式就是release(1),release之中的tryRelease是子类之中写的,那么在这个Lock的子类ReentrantLock之中,其实现方式就为getState() - releases,如果这个值是0,那么判断解锁成功。然后将c的值set到state之中。
8.1.5 哪里有坑?
重入锁的部分有坑:每次加一个锁的时候,值是+1,哪怕是自己重入自己,也要加两次1,解锁的时候也得解两次。
8.2 ReentrantReadWriteLock
8.2.1 是什么?有什么特点?
是一个读写锁:
- 在读的时候,可以多个线程同时进入临界区——被锁定的区域
- 在写的时候,无论读线程还是写线程全都互斥。
特点:
- 读锁不支持条件对象(一起来吧),写锁支持条件对象
- 其公平锁的实现方式是让等待最久的线程获得锁
- 写锁可以降级成读锁,但是读锁不可以升级成写锁
- 读写锁也有公平和非公平模式
- 读锁支持多个读线程一起进入临界区,写锁是互斥的。
8.2.2 怎么用?
内部定义了两个方法:readLock()和 writeLock()。
读线程可以看到写线程更新之后的数据——内存同步。
8.2.3 怎么实现?
public class ReentrantReadWriteLock
implements ReadWriteLock, java.io.Serializable
首先是implement了ReadWriteLock,对比一下ReentrantLock:
public class ReentrantLock implements Lock, java.io.Serializable
ReentrantLock 只是 implement了Lock接口。
ReentrantLock的内部只是三个内部类:Sync,NonfairSync,FairSync。但是读写锁之中多了两个内部类,一个是WriteLock,一个是ReadLock。
状态表示:
不像ReentrantLock之中使用一个volatile的int来标识,因为一个int之中有四个byte嘛,那么32个bit从中间分开,高的16位代表读(共享),低的16位代表写(独占)。
写锁的获取:
调用方式还是acquire(1)。
其tryAcquire()的实现是:首先判断对象是否是无锁状态,而且锁的数量没饱和,并且必须是当前的线程才可以获取锁。
读锁的获取:
读锁的获取是acquiredShared(int arg),其内部的实现doAcquireShared(arg)方法,是首先判断是否另一个线程持有写锁,如果没有的话就设置读取锁的状态。
8.2.4 有什么坑?
要注意的主要一点就是读写锁之中的写锁获取需要无锁状态,读锁的共享前提是没有写锁在挂着,如果其他线程之中本来就有写锁,那么直接失败。
9. 线程池
9.1 是什么?有什么特点?
是线程的集合。如果没有线程池,那么对于多个请求,我们每个请求都要新开一个线程,那么这个代价是不可接受的。那么我搞一个线程的集合,其中没有任务的时候处于空闲,任务到来的时候分配一个空闲的线程,等任务结束之后不是销毁而是直接将其放回线程池之中,这样就实现了线程的重用。
9.2 怎么实现?
JDK提供了一种Excutor框架来使用线程池,其是一种将“任务提交”和“任务执行”分离开的机制(解耦)。
来个图:
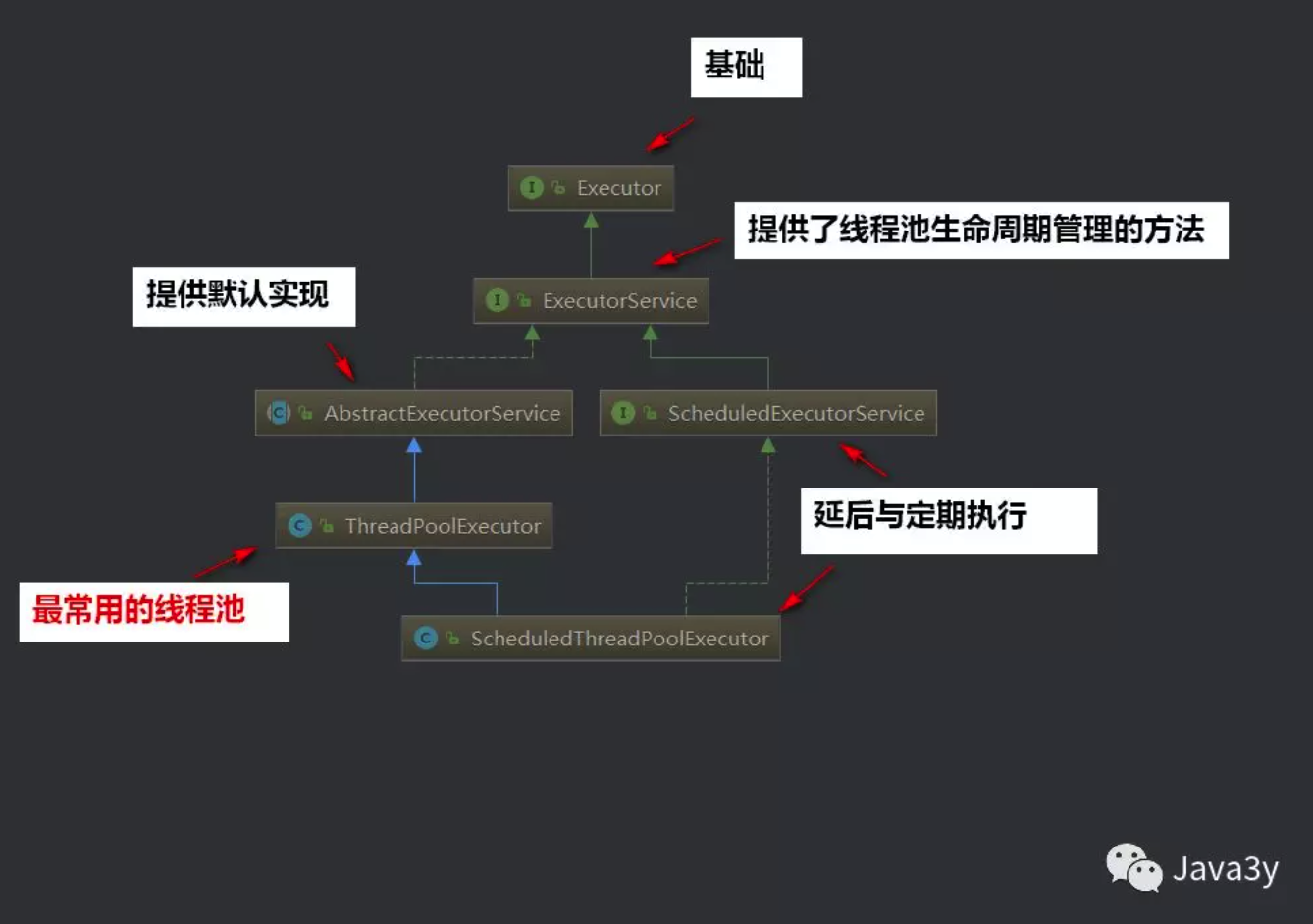
可以看到Executor和ExecutorService 都是接口。而我们的ThreadPoolExecutor使用的是AbstractExecutorService的ExecutorService的默认实现。
先看看这俩接口都是什么组成的?
public interface Executor {
/**
* Executes the given command at some time in the future. The command
* may execute in a new thread, in a pooled thread, or in the calling
* thread, at the discretion of the {@code Executor} implementation.
*
* @param command the runnable task
* @throws RejectedExecutionException if this task cannot be
* accepted for execution
* @throws NullPointerException if command is null
*/
void execute(Runnable command);
}
是的,你没看错,整个接口就一个方法——这也意味着其可以直接lambda表达式来做。
那ExecutorService 呢?
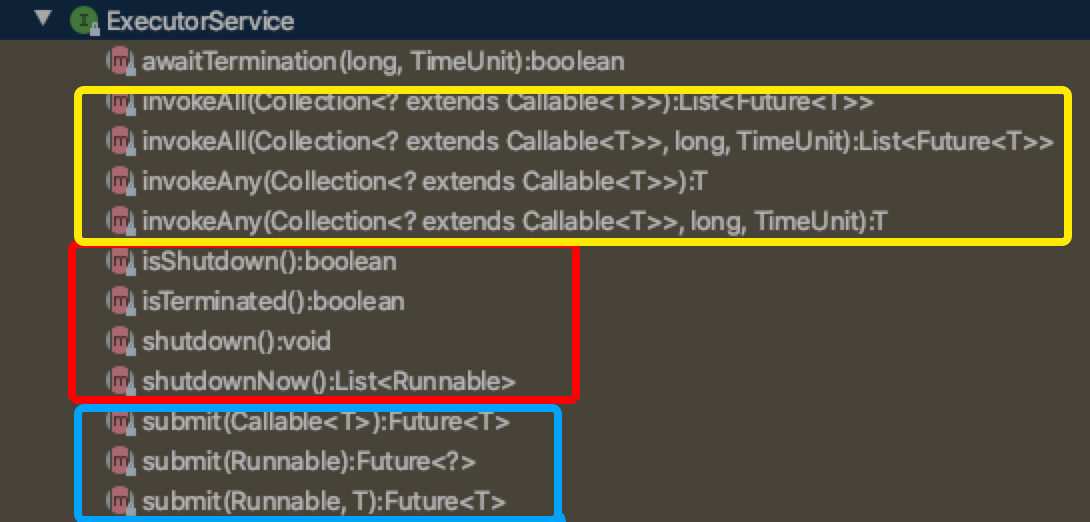
可以将其提供的方法分为三种:
- 管理生命周期:红框,比如shutdown
- 提交任务:submit
- 执行任务:invoke
注意,到这里还不是实现,下面的AbstractExecutorService才是实现:
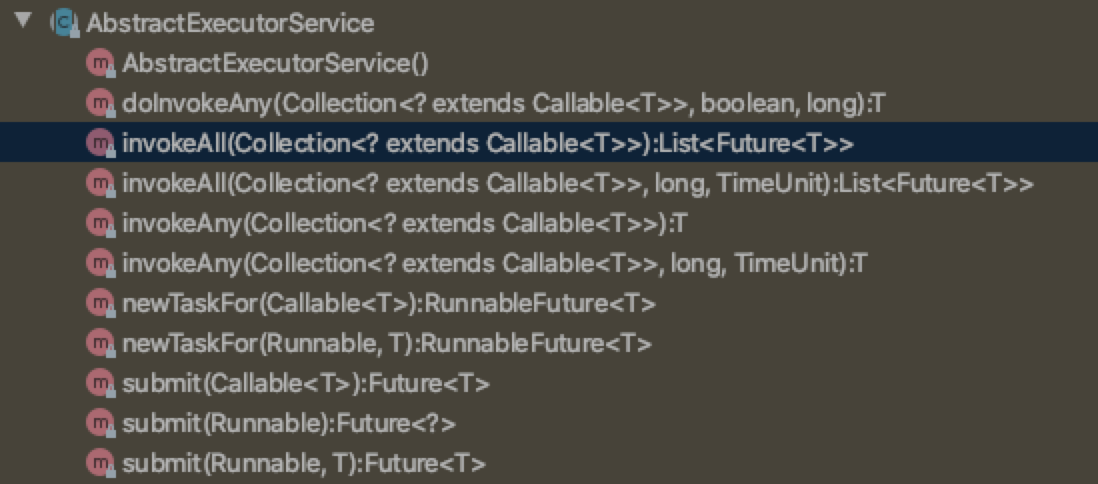
多了个newTaskFor,这是干嘛的呢?

原来就是submit的具体实现,实际上几就是返回一个RunnableFuture。
ScheduledExecutorService之中提供了延迟和定期执行的一些方法,但是其还只是一个接口。比如:

9.3 Callable 和 Future
首先是Runnable和Callable:
Callable就是有返回值的Runnable。
那么Future又是啥呢?
<T> Future<T> submit(Callable<T> task);
在Submit之中传入一个Callable的task,其返回值就是一个Future,内部包裹的内容和Callable的包裹内容一样。
Callable之中的call()方法返回的类型就是future之中的T的类型。其实Future是代表任务的生命周期,但是在其中可以拿到Callable的返回值,所以一般而言都将其作为Callable的返回值使用。
9.4 ThreadPoolExecutor详解
9.4.1 怎么实现?
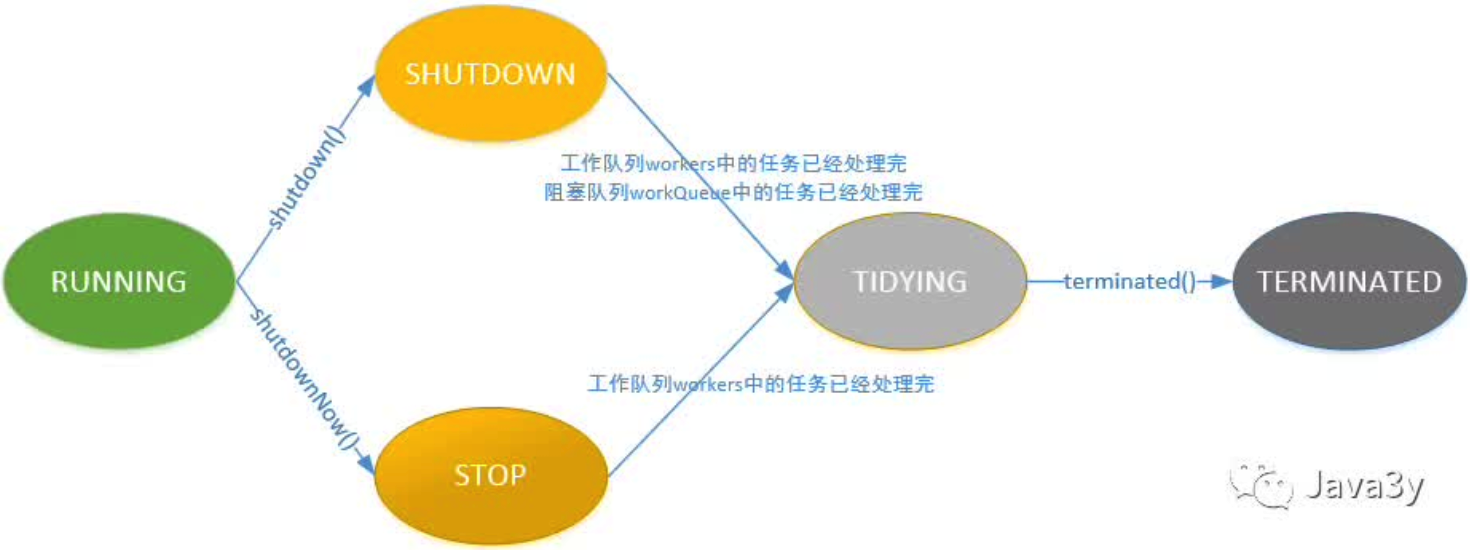
- 状态标识:使用ctl,一个AtomicInteger,可以用来记录“线程池之中的任务数量”和“线程池的状态”两个信息。一个Integer是32位的,用高3位标识状态,低29位标识线程池之中的任务数量。
具有的状态:
- RUNNING: 线程池可以接收新任务,也可以对新添加的任务进行处理
- SHUTDOWN: 线程池不接受新任务,但是可以对已经添加的任务进行处理
- STOP:线程池不接受新任务,并且会中断正处理的任务
- TIDYING:所有任务已经终止时,ctl记录的“任务数量“变为0。当线程池变为TIDYING状态的时候,会执行钩子函数
terminated(),这个函数在ThreadPoolExecutor之中是空的,如果用户想在线程池编程TIDYING的时候进行处理,可以重载terminated() - TERMINATED:线程池彻底终止的状态
默认实现的池?
三个比较常见的实现池:
-
newFixedThreadPool:
- newCachedThreadPool
- singleThreadExecutor
直接看构造函数:
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
可见其是固定线程数量,且无界队列
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
可见其开始线程数目位0,不设线程的上限,等待时间是60秒,超时之后直接关闭maxPool的部分,也就是每个线程只能运行60秒
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
只有一个线程的线程池,无界队列。
9.4.2 如何使用?
直接看构造方法:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
核心七个参数:
- 核心线程数量
- 最大线程数量
- 允许线程空闲时间
- 时间单位
- 阻塞队列
- 线程工厂
- 任务拒绝策略
其中重点两个:
- 排队策略要点:
- 同步移交:管你多少个任务,来多少我开多少线程
- 无界队列:只要核心线程都在工作,其他的全在队列之中等待。因此也不会创建多余核心线程的数量。此处的无界限指的是队列无界限,比如LinkedBlockingQueue,那么任务可以无限增长
- 有界队列:队列是有界限的,队列不可以无限增长。可以避免资源耗尽,但是一定程度上面降低了吞吐量
- 拒绝任务策略:当排队队列满了的时候:
- 直接抛出异常
- 直接丢弃
- 当前线程直接执行(调用者的线程)
- 丢掉最老的任务
execute()方法:
先看线程池之中的核心线程数量是否到了corePoolSize,如果没到,哪怕其中的线程是空的,也要新建一个线程来处理任务。
之后会去找线程池的状态是否是running,不是的话直接拒绝任务。是的话尝试能否在queue之中添加任务,并且以maxPoolSize作为上限来创建任务为null的工作线程。还不行的话直接拒绝任务。
shutdown()方法:
提供了两个:shutdown()和 shutdownNow().
shutdown(): 线程池状态变成SHUTDOWN,等任务执行完才中断线程。如果已经SHUTDOWN了的话不会有任何其他效果。
shutdownNow():线程池的状态直接变成STOP,不等待任务执行完(停止所有的活动执行任务,暂停等待任务的处理),返回等待的任务列表。
9.4. 有什么坑?
在线程池之中,最好每个线程的任务是彼此独立的,也就是不需要协同。如果需要协同的话,最好使用的是无界线程池,不然有界的线程池或者队列可能导致线程”饥饿“死锁问题。
线程池的开始阶段是不创建线程的,只有当任务来临的时候才去创建线程。
10. 多线程的三个同步工具类
下面介绍三个同步工具类。同步,就是为了解决线程之间的通讯问题。
10.1 CountDownLatch(闭锁)
10.1.1 是什么?
是一个同步的辅助类,允许一个或者多个线程等待,直到等待的线程都完成自己的工作。
10.1.2 怎么用?如何实现?
常用的API就两个:await() 和 countDown()。
count 初始化 CountDownLatch,然后需要等待的线程就会调用await方法。await方法会阻塞直到 count = 0。其他被等待的线程完成操作之后,调用countDown() 方法使count-1。这个是不是看起来很像AQS的state?哈哈哈,实际就是!
public class CountDownLatch {
/**
* Synchronization control For CountDownLatch.
* Uses AQS state to represent count.
*/
private static final class Sync extends AbstractQueuedSynchronizer {
......
所以就是谁做完了就把这个值-1,直到最后减到0了,就释放所有等待的线程。
10.2 CyclicBarrier(栅栏)
10.2.1 是什么?怎么用?
是一个公共屏障点。在需要所有线程全部到达的代码点出加上一个栅栏,那么所有线程到达栅栏之后才会继续执行
10.2.2 有什么坑?
其可以被重用,而之前的countDownLatch就不可以重用了(其state都修改完了还怎么重用嘛)。
10.3 Semaphore(信号量)
10.3.1 是什么?
是一个控制同时访问某个资源的线程个数的”许可证“
10.3.2 怎么用?
其中两个主要方法:
acquire()和release()。
acquire()的时候,会消费一个许可证。如果没有了许可证,会阻塞。release()的时候,会释放一个许可证。
11. Atomic相关
11.1 是什么?什么特点?怎么用?
先来CAS定义:
比较并交换(compare and swap, CAS),是原子操作的一种,可用于在多线程编程中实现不被打断的数据交换操作,从而避免多线程同时改写某一数据时由于执行顺序不确定性以及中断的不可预知性产生的数据不一致问题。 该操作通过将内存中的值与指定数据进行比较,当数值一样时将内存中的数据替换为新的值。
最值钱的就俩字:原子!!!
那么CAS之中,在失败的情况下,有两种处理方式:自旋重试和啥都不做。如何选择这两种情况呢?
- 自旋重试:在累加或者累计计算的时候,比如累加,累减等等。
- 啥都不做:在一步到位的时候,比如都想把这个值从0修改成5,那么一个线程发现已经被修改的时候,就会将自己的操作直接丢弃,啥都不做
11.2 如何实现?
从底层理解为啥是原子性的:Atomic的包使用的都是Unsafe实现的包装类。其中最常见的CAS方法有:
// 第一和第二个参数代表对象的实例以及地址,第三个参数代表期望值,第四个参数代表更新值
public final native boolean compareAndSwapObject(Object var1, long var2, Object var4, Object var5);
public final native boolean compareAndSwapInt(Object var1, long var2, int var4, int var5);
public final native boolean compareAndSwapLong(Object var1, long var2, long var4, long var6);
看到明晃晃的native没?直接C代码,调用汇编,最后只生成一条CPU指令cmpxchg完成操作。一条指令还如何打断?哈哈
11.3 ABA问题和如何解决
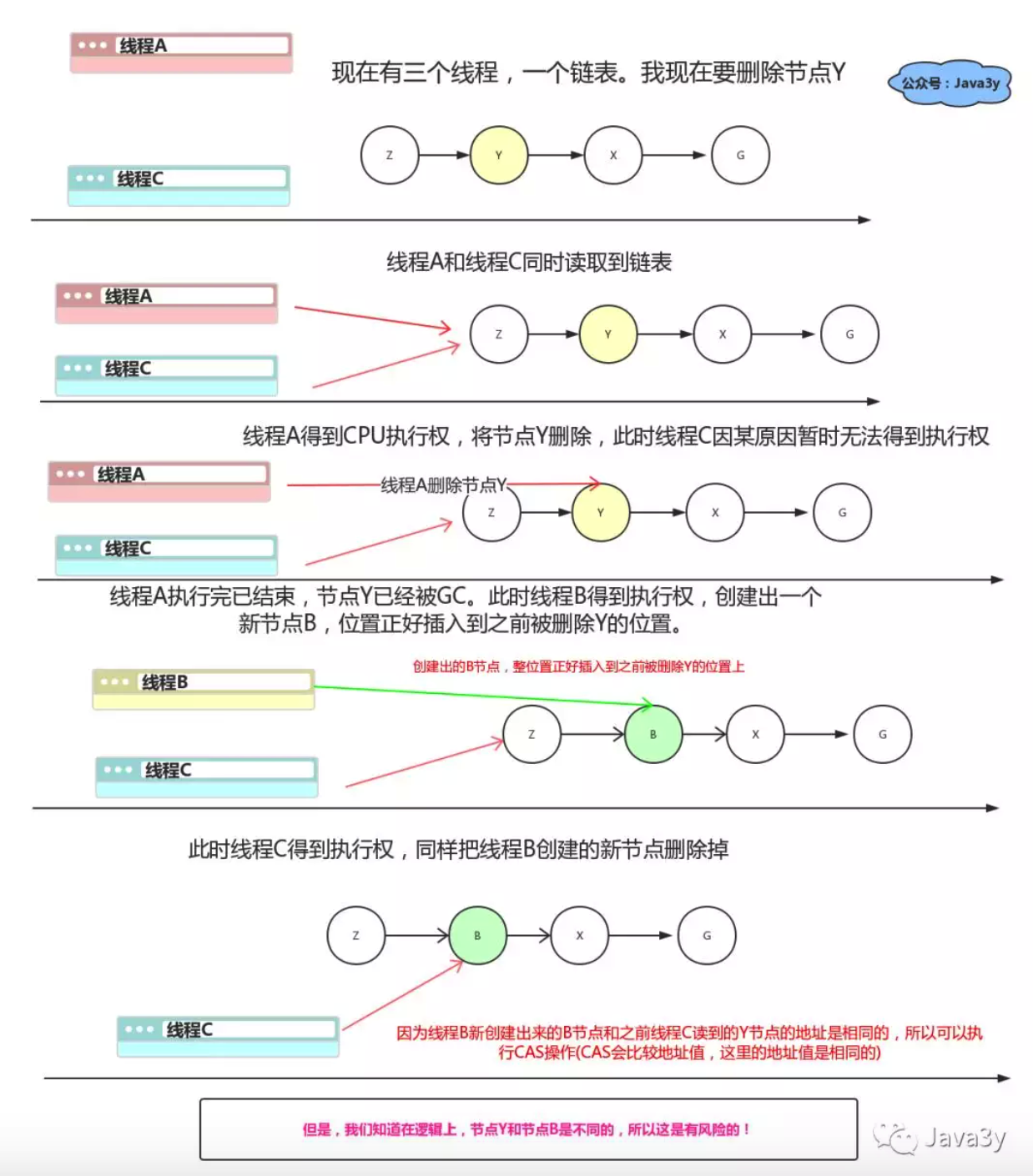
那么如何解决呢?可以使用JDK提供的AtomicStampedReference和AtomicMarkableReference类。
AtomicStampedReference:本质就是给对象提供了一个原子增加的stamp用作标记状态。其维护了一个Pair对象,其中有我们自己的对象引用和一个stamp值,每次CAS之中比较的是两个Pair对象。