还是天问五连:是什么?有什么特点?怎么用?如何实现?有什么要注意的地方?
走!
1. Collection
2.1 什么是Collection
Java是一门面向对象的语言,那么有的时候我们需要对不止一个对象进行处理,这种情况就需要”集合“,也就是Collection来存放对象。
2.2 怎么用?
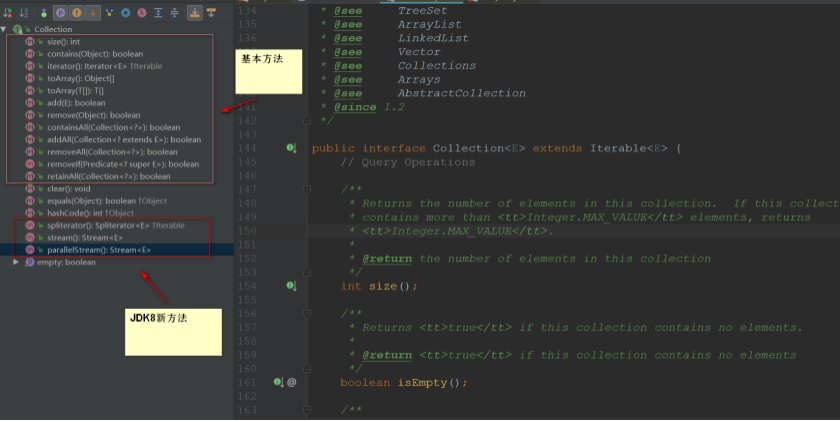
可以看出很多方法,比如 size(),contains(),iterator() ,add(),remove() 等等,都是Collection提供的。
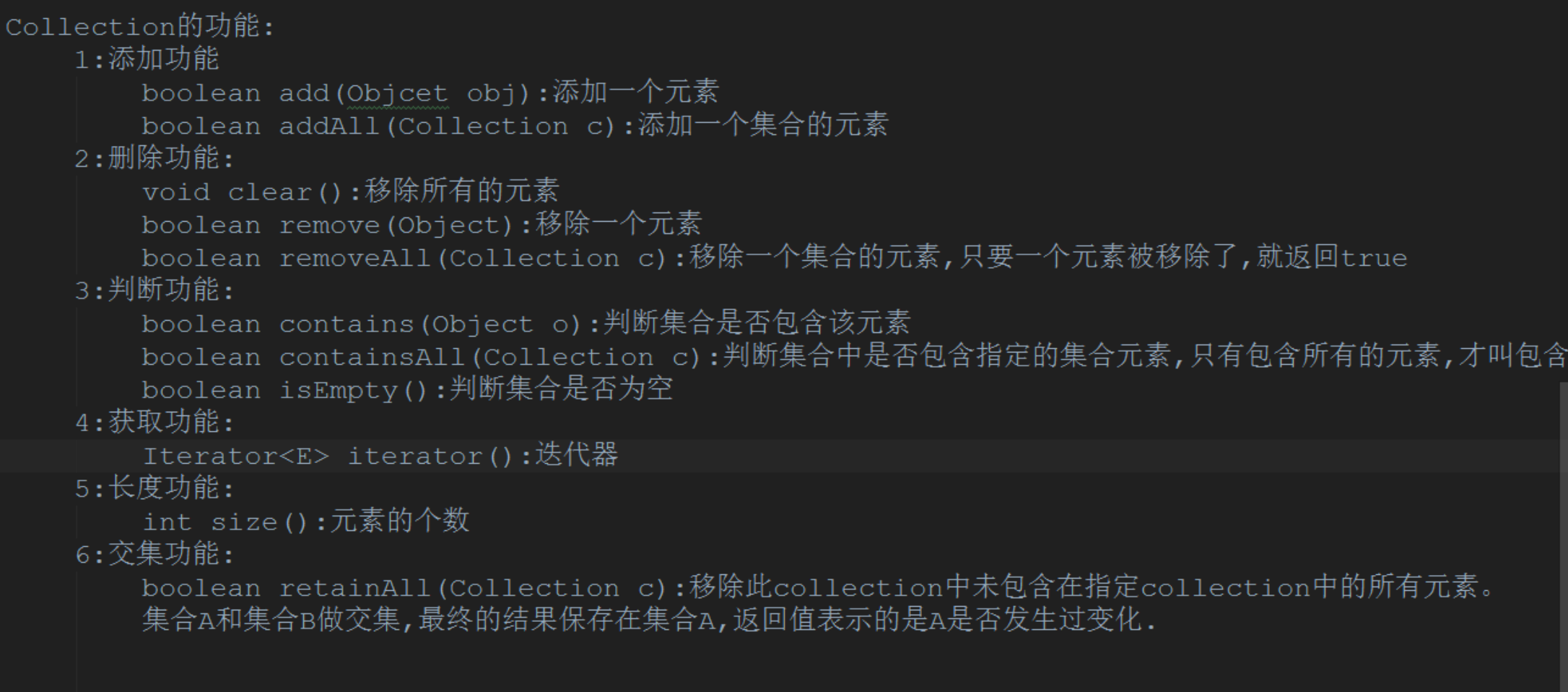
2.2.1 retainAll()
最后这个retainAll()平时用的很少,下面是代码示例:
package UseToStudyJavaClass.CollectionStudy;
import java.util.ArrayList;
public class RetainAllTest {
public static void main(String[] args) {
ArrayList<Integer> arr1 = new ArrayList<>();
arr1.add(1);
arr1.add(2);
arr1.add(3);
ArrayList<Integer> arr2 = new ArrayList<>();
arr2.add(1);
arr2.add(4);
arr2.add(5);
boolean status =arr1.retainAll(arr2);
System.out.println("Status is "+status);
for(int i:arr1){
System.out.println(i);
}
}
}
结果是:
Status is true
1
2.2.2 迭代器(iterator)
public interface Collection<E> extends Iterable<E> {
基础功能有:
- size()
Collection本身就继承了Iterable这个接口。
public interface Iterable<T> {
/**
* Returns an iterator over elements of type {@code T}.
*
* @return an Iterator.
*/
Iterator<T> iterator();
而Iterable这个接口之中有一个Iterator,其本身还是一个接口:
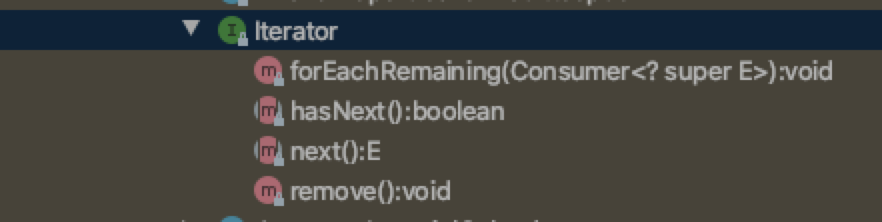
其中第一个方法:
/**
* Performs the given action for each remaining element until all elements
* have been processed or the action throws an exception. Actions are
* performed in the order of iteration, if that order is specified.
* Exceptions thrown by the action are relayed to the caller.
*
* @implSpec
* <p>The default implementation behaves as if:
* <pre>{@code
* while (hasNext())
* action.accept(next());
* }</pre>
*
* @param action The action to be performed for each element
* @throws NullPointerException if the specified action is null
* @since 1.8
*/
default void forEachRemaining(Consumer<? super E> action) {
Objects.requireNonNull(action);
while (hasNext())
action.accept(next());
}
意思就是把每个元素都过一遍这个叫做action 的 Consumer,,直到过完或者抛出异常。
下面的三个方法我们都无比熟悉了。 按照博主的意思,其是在ArrayList之中的内部类被实现的:看到这个Itr()了没。
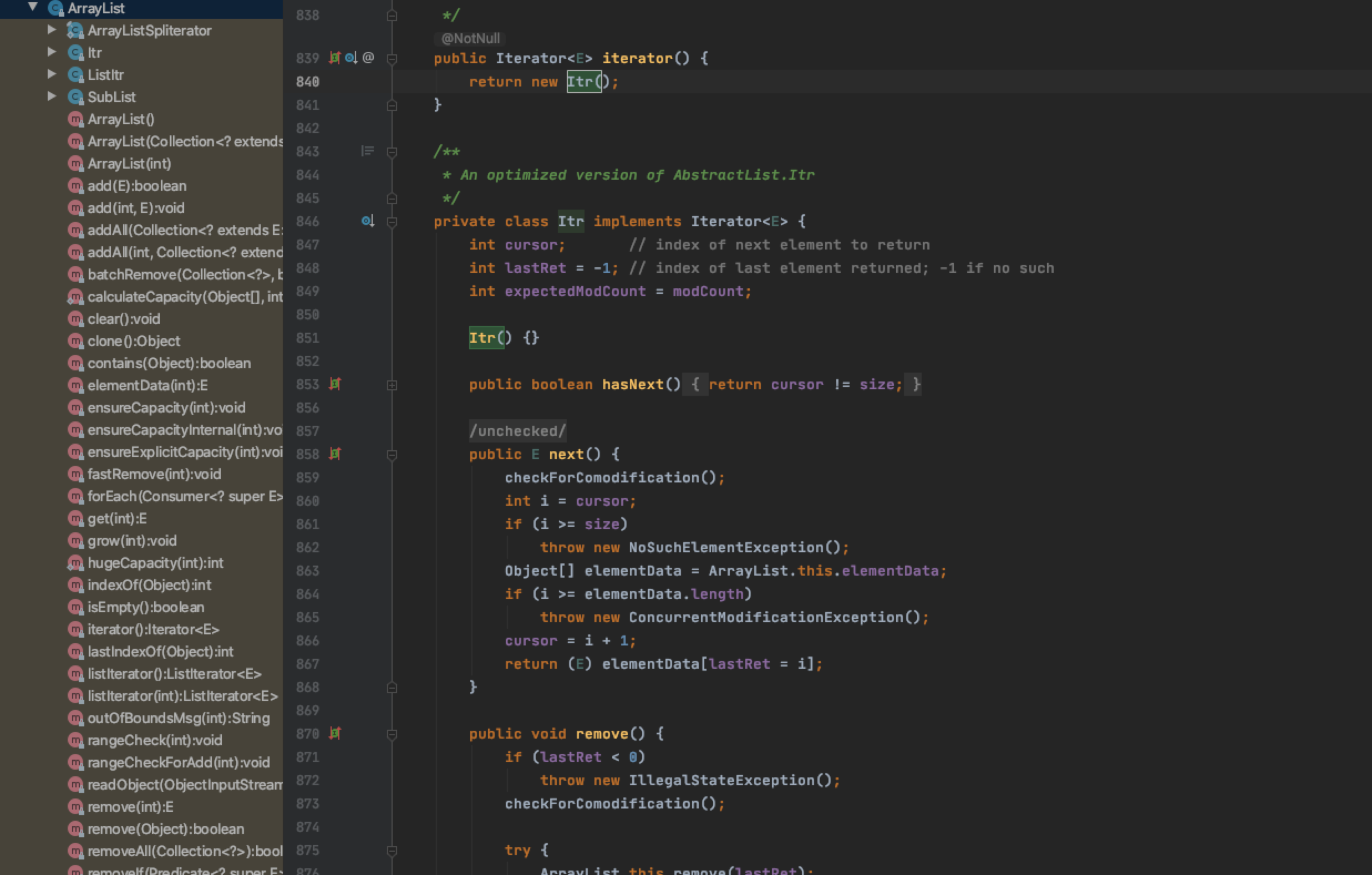
那么这个迭代器怎么用呢?
package UseToStudyJavaClass.CollectionStudy;
import java.util.ArrayList;
import java.util.Iterator;
public class IterableTest {
public static void main(String[] args) {
ArrayList<Integer> arr1 = new ArrayList<>();
arr1.add(1);
arr1.add(2);
arr1.add(3);
Iterator i = arr1.iterator();
while(i.hasNext()){
System.out.println(i.next());
}
}
}
由于每个继承了Collection的对象都有iterator(),其返回的就是一个 Iterator,那么就可以按照iterator的三个方法来对ArrayList做操作。
2. 有什么要注意
数组和集合的区别:
- 数组的长度固定,集合的长度可变
- 数组可以存储基本类型和引用类型(int[] 或者 Integer[])都可以,但是集合只能存储引用类型,如果存储的是基本类型,会进行自动装箱操作——从int变成Integer
迭代器为什么不设计成一个类,而是一个接口?
如果设计成一个类,有两种:抽象类和实体类。
如果设计成抽象类,按照java的不可多重继承原则,其就没法去继承其他的类。那么就会出现使用上面的短板。如果写成实体类,即其可以直接实体化成一个对象,那么对于不同种类的Collection,其遍历方法必然不同,也就没法产生这样一个随处可用的实体方法。所以其只能是一个接口。
2.3 List简介
Collection之中主要分两种:Set和List。一个无序不重复,一个有序可重复。
2.3.1 是什么?有什么特点?
是一个有序可重复的implement Collection接口的接口
2.3.2 怎么用?
2.3.3 如何实现?
其中对Collection 的 Iterator进行了自己的实现。
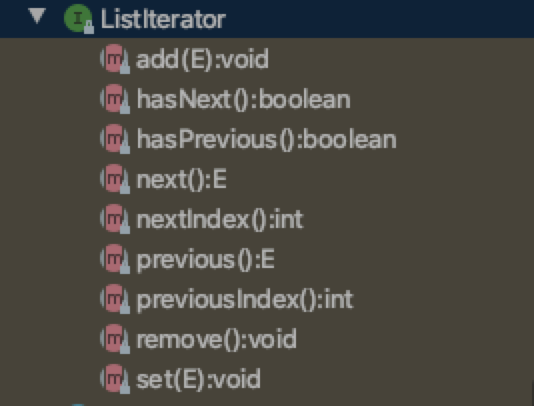
可见主要是多了往前遍历,添加元素和修改元素的操作。
2.3.3.1 常用子类
- ArrayList: 底层数据结构是数组,线程不安全
- LinkedList: 底层数据结构是链表,线程不安全
- Vector: 底层数据结构是数组。线程安全。
2.4 Set简介
2.4.1 是什么?
是一个不可重复的Collection实现
2.4.2 常用子类
- HashSet: 底层是HashTable
- TreeSet: 底层红黑树,元素有大小的排序
- LinkedHashSet: 底层是HashTable+ LinkedList
2. List集合精讲
主要讲这三个子类的特别用法和实现:
- ArrayList: 底层数据结构是数组,线程不安全
- LinkedList: 底层数据结构是链表,线程不安全
- Vector: 底层数据结构是数组。线程安全。
2.1 List是什么?有什么特点?(略,之前讲过)
2.2 ArrayList
2.2.1 ArrayList 如何实现?
底层就是一个数组,第一次添加元素到ArrayList 之中的时候,数组将扩容DEFAULT_CAPACITY(默认是10)。
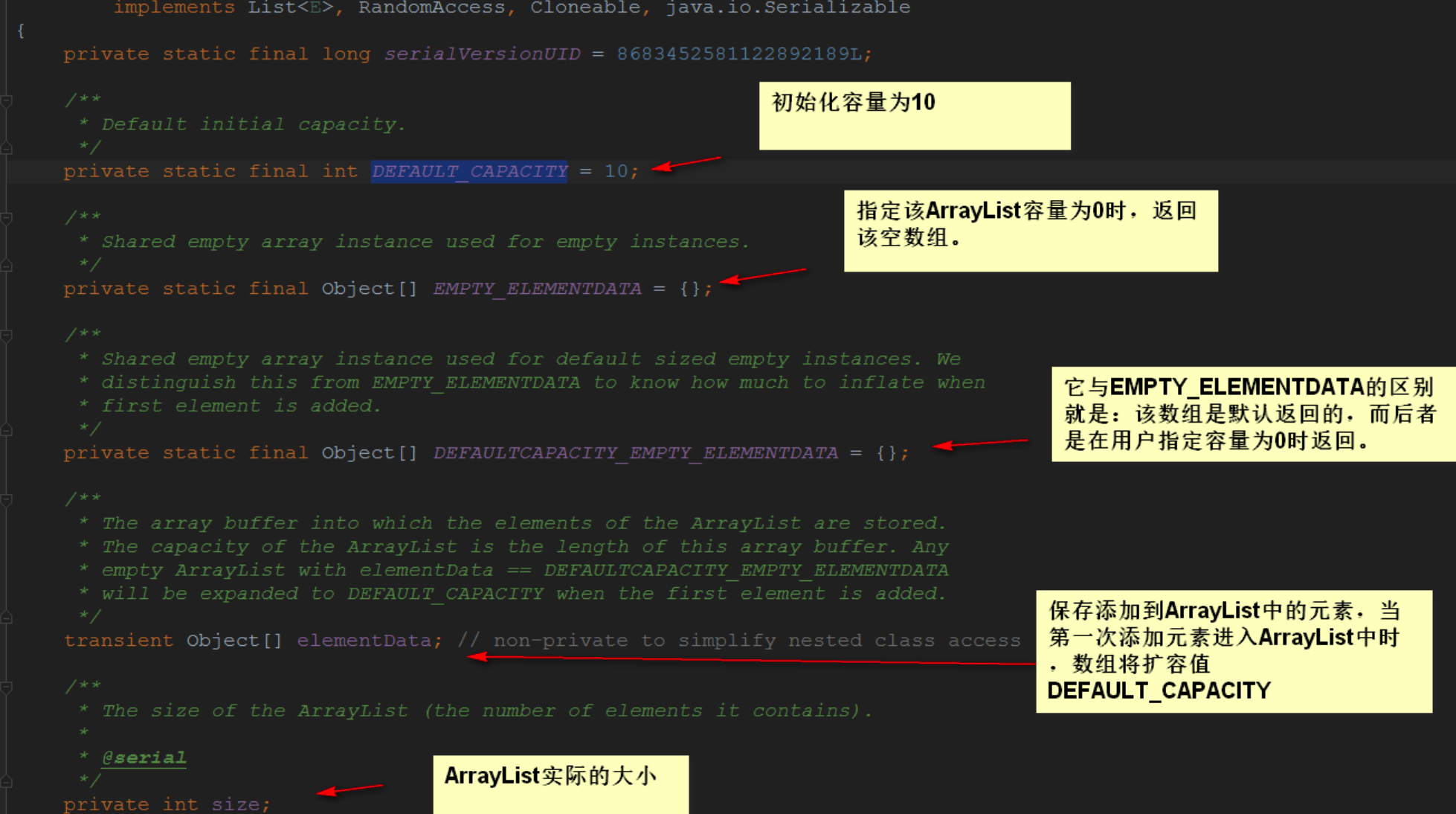
/**
* Constructs an empty list with the specified initial capacity.
*
* @param initialCapacity the initial capacity of the list
* @throws IllegalArgumentException if the specified initial capacity
* is negative
*/
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
2.2.1.2 add(E e) 如何实现?
- 检查是否需要扩容:
- 足够:直接添加
- 不足够:扩容,在原来容量的1.5倍和minCapacity(默认长度和要扩容的长度之中的最大值)之中取最大值。
- 插入元素
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!! elementData[size++] = e;
return true;
}
2.2.1.3 add(int index, E element)如何实现?
- 检查角标是否越界
- 空间检查是否需要扩容
- 插入元素:使用arrayCopy(),其是一个native方法
2.2.1.4 get(int i) 如何实现?
- 检查角标
- 返回具体元素
2.2.1.5 E set(int index, E element) 如何实现?
- 检查角标是否越界
- 替代元素
- 返回旧值
2.2.1.6 E remove(int index) 如何实现?
- 检查角标是否越界
- 计算后面部分需要向左移动的个数
- 将最后一个元素设置为null,从而让GC回收
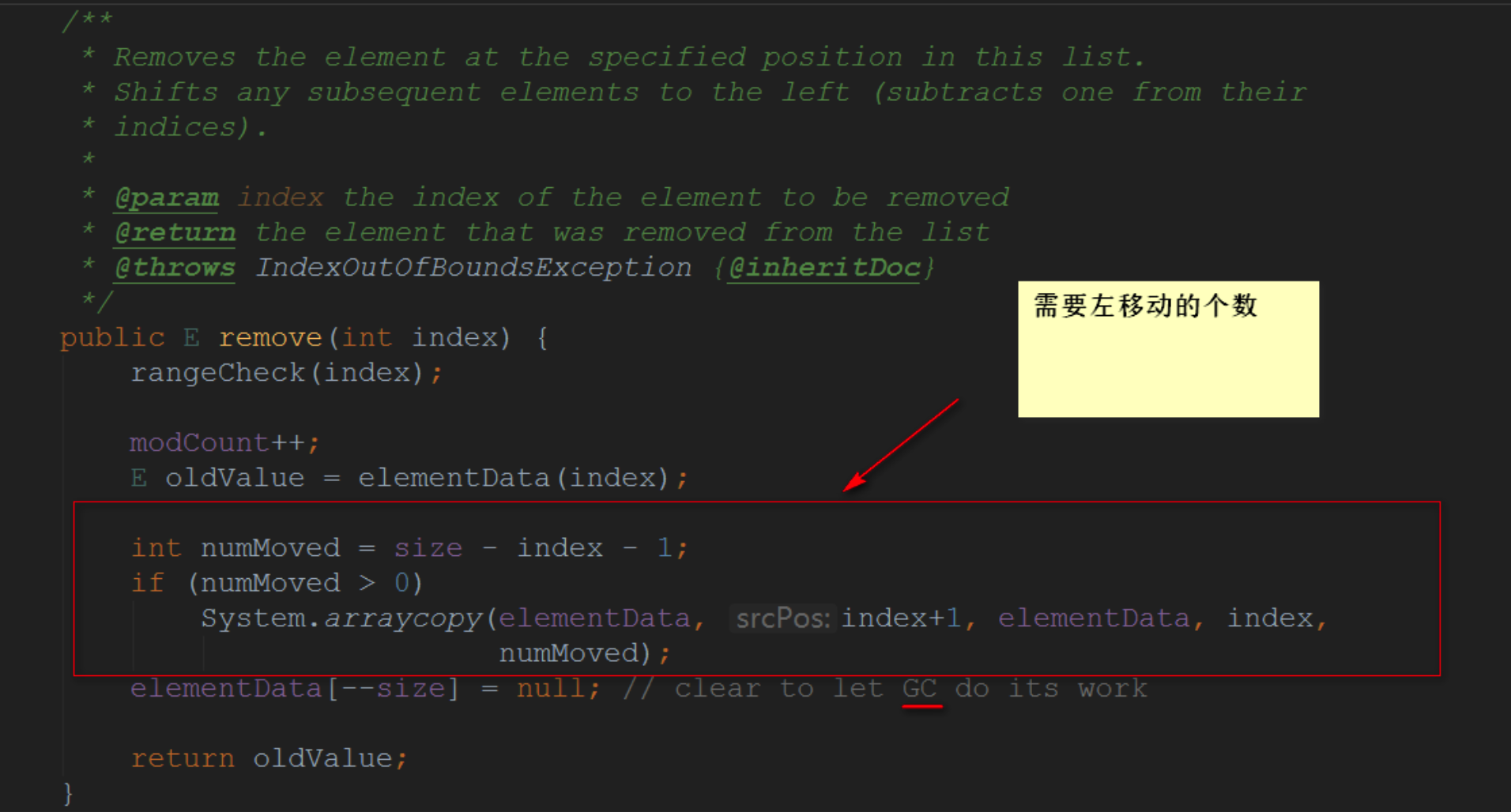
2.2.2 ArrayList有什么坑?
其在删除数据的时候不会减少容量。想要减少需要自己调用trimToSize():
/**
* Trims the capacity of this <tt>ArrayList</tt> instance to be the
* list's current size. An application can use this operation to minimize
* the storage of an <tt>ArrayList</tt> instance.
*/
public void trimToSize() {
modCount++;
if (size < elementData.length) {
elementData = (size == 0)
? EMPTY_ELEMENTDATA
: Arrays.copyOf(elementData, size);
}
}
ArrayList 可以存放null值。
package UseToStudyJavaClass.CollectionStudy;
import java.util.ArrayList;
import java.util.Iterator;
public class ListTest {
public static void main(String[] args) {
ArrayList<Integer> arr = new ArrayList<>();
arr.add(1);
arr.add(2);
arr.add(null);
arr.add(3);
Iterator i = arr.iterator();
while(i.hasNext()){
System.out.println(i.next());
}
}
}
输出为:
1
2
null
3
2.2.3 Vector和ArrayList的区别
Vector底层也是数组,但是其线程安全。使用的方法就是全部Synchronized 一遍方法。
2.3 LinkedList 怎么用?
LinkedList是一个双向链表。
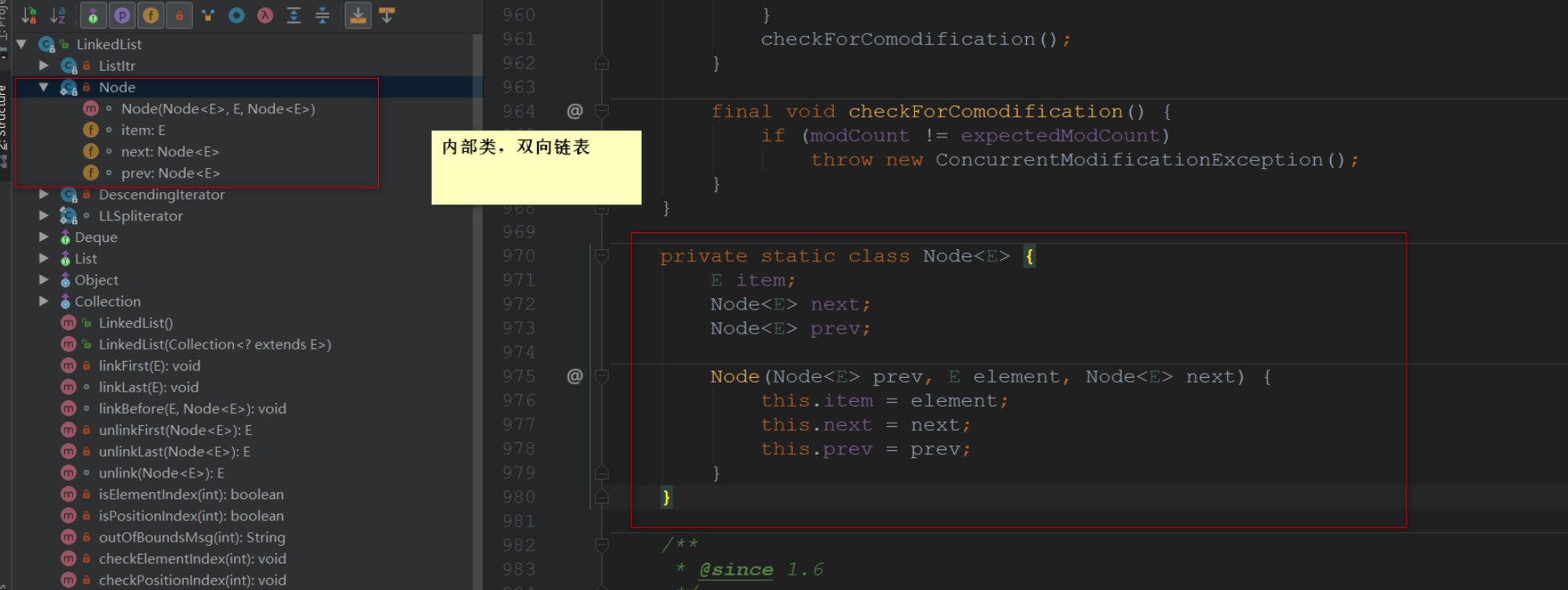
其还实现了Deque接口,deque全称是双端队列(double-ended queue),其具有队列和栈的性质,元素可以从两端弹出。
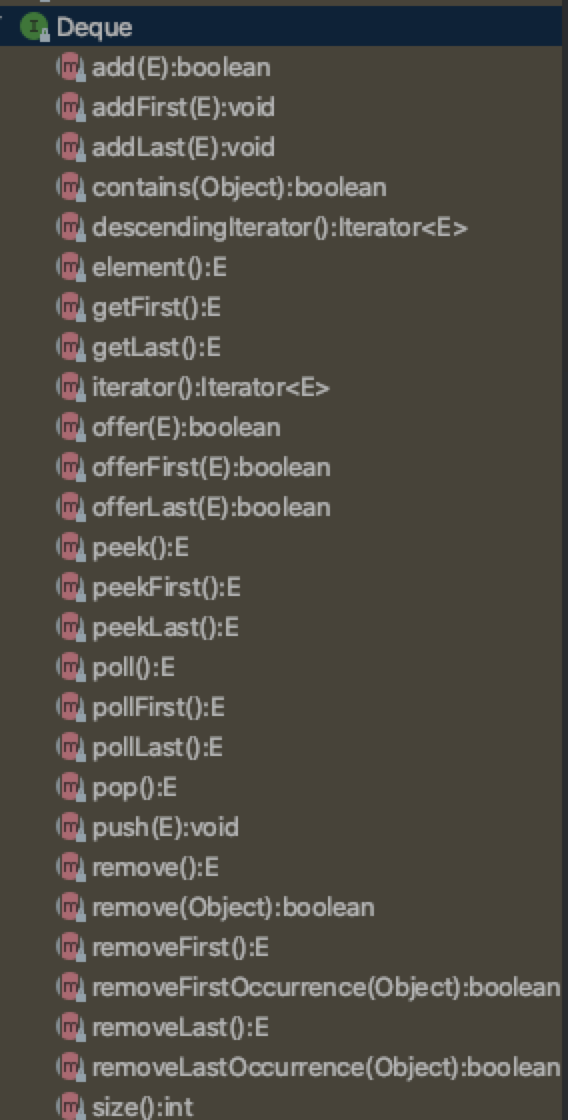
双端的操作都在这个接口里面,从First和Last做操作全在其中。
2.3.1 构造方法
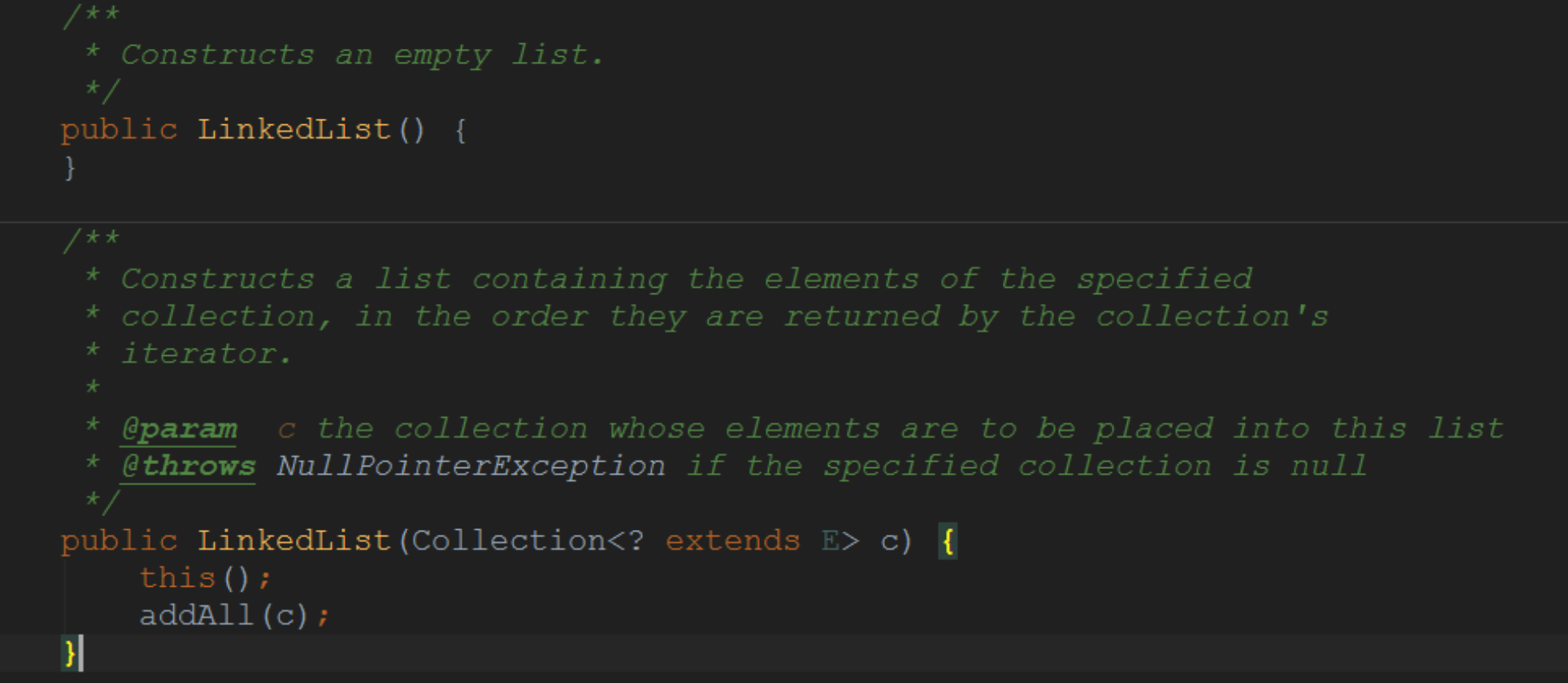
要么无参构造,要么将另一个Collection的东西加入LinkedList。
2.3.2 remove(Object o)
删除时候看 equals() 是否成立,成立的话就unlink这个节点。
unlink 原理:
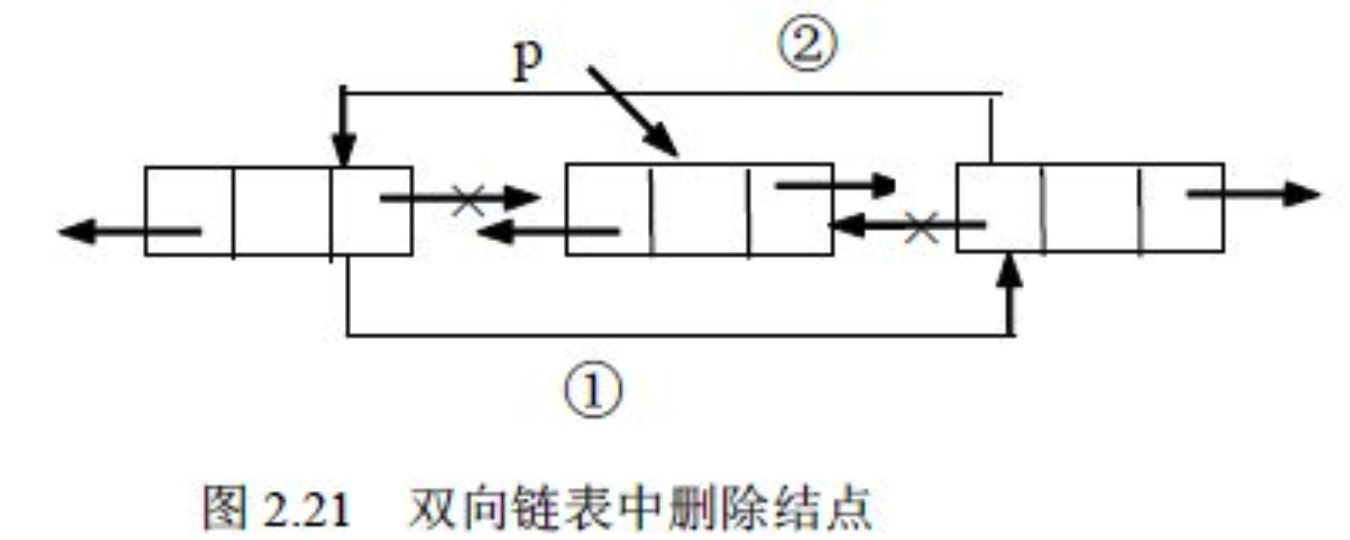
2.3.3 get(int index)方法
其也是遍历,但是看下标。下标小于长度一半,就从头遍历。不然就从尾遍历。
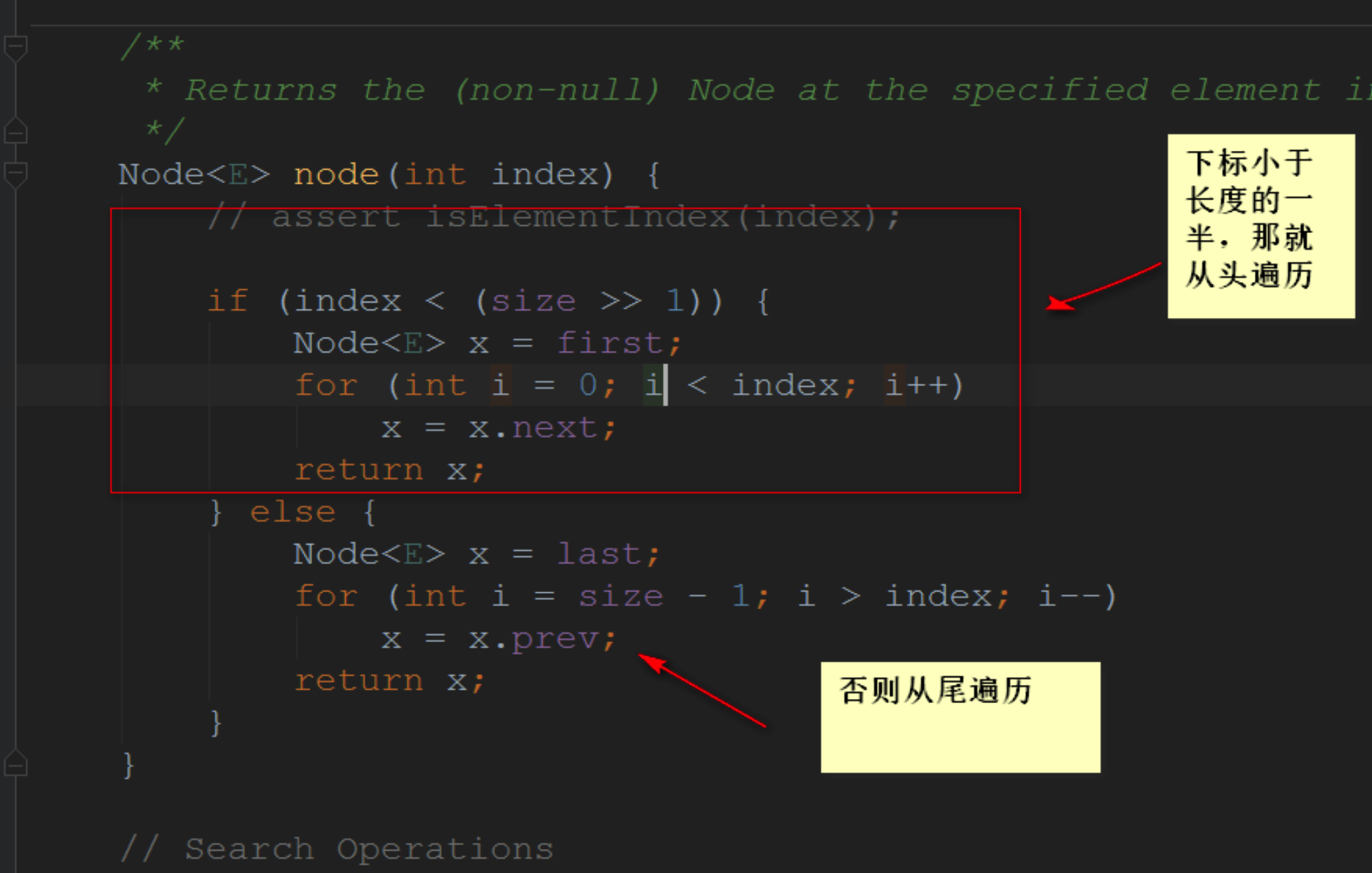
2.3.4 E set(int index, E element)
也是先看index决定从头还是尾遍历,找到对应的Node之后就替换值,并且将旧值返回。
3. Map详解
3.1 什么是 Map?Map的特点?
之前讲过Java之中的数据结构主要分Map和Collection。Map就是映射对。
3.2 Map怎么用?

3.3 什么是红黑树?为什么要有红黑树?
一开始我们是有BST的。但是BST在最坏的情况下会退化成一个链表。那么就出现了平衡树的概念——红黑树就是一种平衡树(左右子树的高度相差不超过1)。
那么为了保证平衡,多了一种”2-3树“:
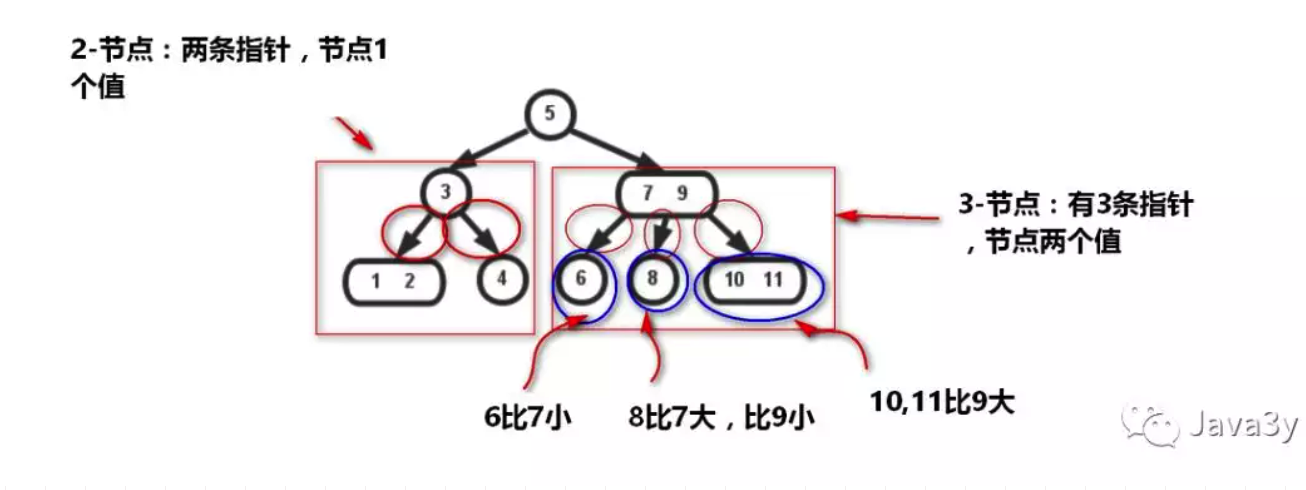
2-3树在插入的时候要涉及到很多节点的合并和分解,不太行。有啥办法能避免这一步呢?
红黑树闪亮登场!
红黑树用旋转和变色来替代节点的合并分解操作,比2-3树的维护要方便一些。
4. HashMap
4.1 是什么?
是一个用hash进行散列的key-value的map。
4.2 怎么实现?
基本属性:
- 初始容量16
- 最大容量:2的31次方
- 默认Load_factor = 0.75
- TREEIFY_THRESHOLD = 8, 一个桶之中的节点数目超过这个那么就变树
- UNTREEIFY_THRESHOLD = 6,一个桶之中节点数目小于这个就变成链表
- MIN_TREEIFY_CAPACITY = 64,小于这个数量的桶的话不会变成树。
其内部的实现就是数组+链表+红黑树。
HashMap:
- 无序,允许key为null
- 底层是数组+链表实现
- 初始容量和load_factor对其影响都是蛮大的,当然也可以将load_factor设置成2,那么永远不会扩容了。
4.2.1 构造方法
可传入Capacity和loadFactor来进行构造。其中capacity会有一个方法tableSizeFor()来生成,其返回值是一个大于输入参数且最近的2的整数次幂。
4.2.2 put() 方法
最重要的部分是得到hashCode。
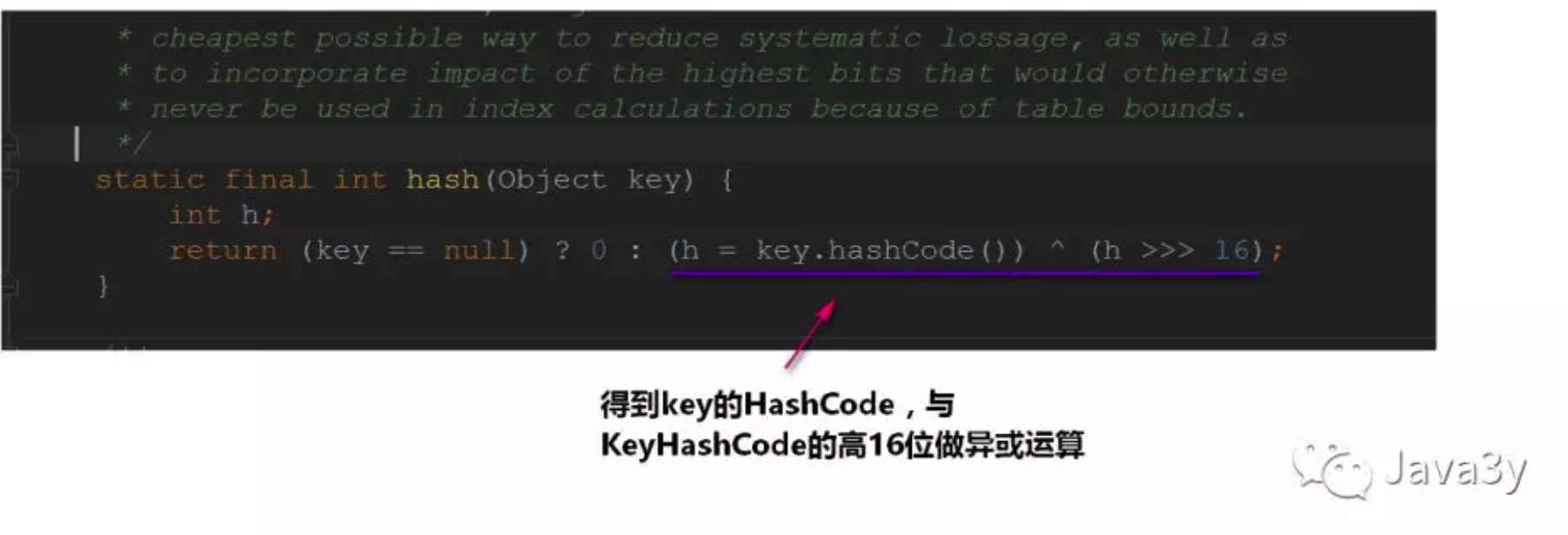
为什么对于key的hashcode还要再将其和hashCode的高16位做异或运算?
hashmap的初始容量为16,那么我们想要将数据放在的位置是就是0~15,也就是 (n-1) 是其极限值。那么按照下图:
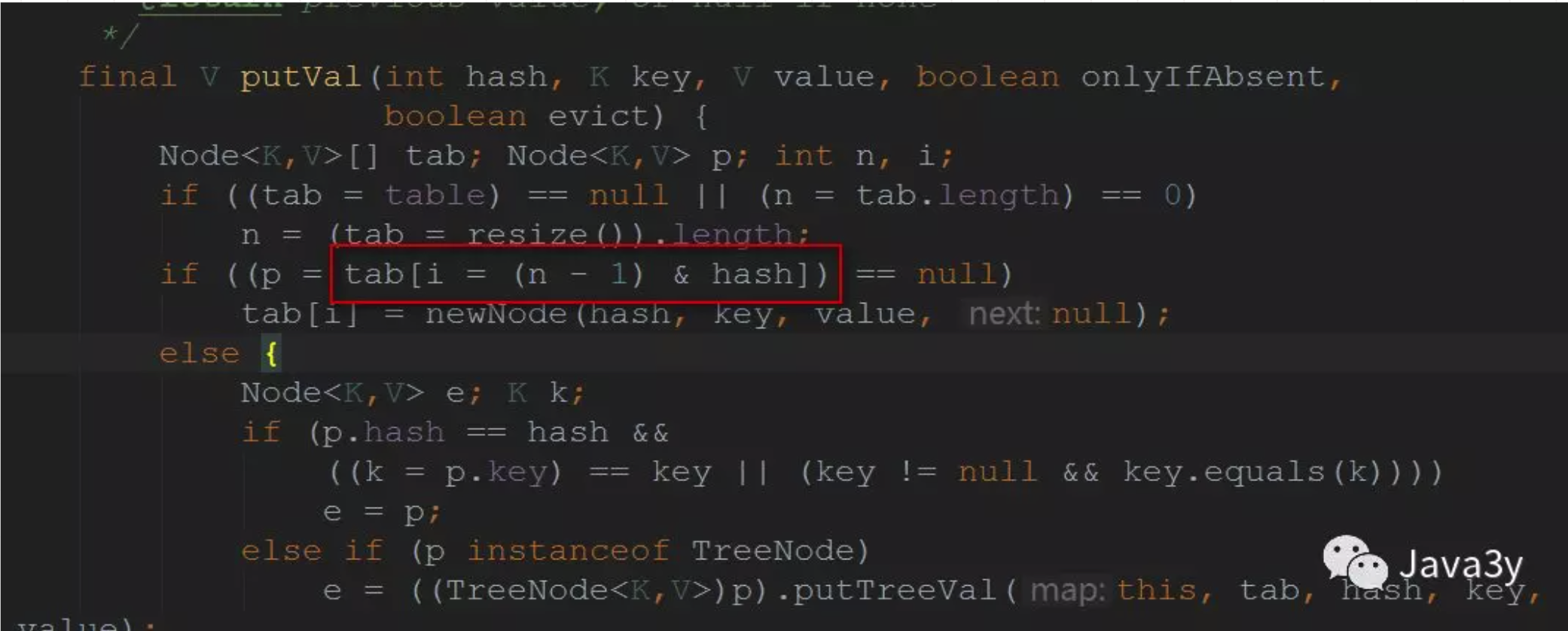
可以看到就是(n-1) & hash这个位运算再起作用。那么当n比较小,比如16这个初始容量的时候,其只有低位会参与其中。那么如何让高位的hash值也起作用呢?就是上面这一句“再将其和hashCode的高16位做异或运算”。这就增加了随机性。
put(E e)的最主要的地方是如何解决碰撞,hashmap之中使用的是拉链法,即在hash冲突的地方搞一个链表,冲突的话就从头到尾比较hashcode,再冲突就直接比较equals()。
4.2.3 扩展:何时重写hashCode?何时重写equals?
- 在两个对象做比较的时候必须重写
equals,因为其默认实现是比较地址是否相同,那么两个对象即使内容相同,地址也会不同,直接使用equals必然报错。 - 在对象用作hash类的key的时候需要重写。hashCode的默认实现之中是通过地址生成的,那么两个不同对象的值是不一样的,那么如果其中的内容相同,hashcode也不同,就对我们使用hashMap,hashSet等等操作产生了影响。所以要自己重写hashcode
* As much as is reasonably practical, the hashCode method defined by
* class {@code Object} does return distinct integers for distinct
* objects. (This is typically implemented by converting the internal
* address of the object into an integer, but this implementation
* technique is not required by the
* Java™ programming language.)
*
* @return a hash code value for this object.
* @see java.lang.Object#equals(java.lang.Object)
* @see java.lang.System#identityHashCode
*/
public native int hashCode();
4.2.4 resize() 方法
注意,在初始化的时候调用的也是这个方法。所以其可以初始化hashmap,或者是将其扩充2倍。方法头很有趣,在扩容之后元素不是在原位置就是在(原容量+原位置)的位置。其操作位扩容后的容量进行&操作来计算新的索引位置。
/**
* Initializes or doubles table size. If null, allocates in
* accord with initial capacity target held in field threshold.
* Otherwise, because we are using power-of-two expansion, the
* elements from each bin must either stay at same index, or move
* with a power of two offset in the new table.
*
* @return the table
*/
final Node<K,V>[] resize() {
4.2.5 JDK1.7 之中头插法导致的死循环问题
参考:https://juejin.im/post/5a66a08d5188253dc3321da0
主要是发生在多线程的rehash的过程之中的。由于头插法,如果之前的顺序是a->b->c,那么在扩容之后的相应节点是c->b->a。一旦中途某个线程暂时挂起,比如线程1是走到了a->b这里,对其而言e是a,e.next是b。但是线程2开始扩容,走到了c->b->a的末端,即e=b; e.next = a。那么此时a再去拿节点的时候就懵了,互相指了。
5. LinkedHashMap 详解
5.1 LinkedHashMap 是什么?有什么特点?
是一个元素的插入有序的HashMap。其底层是HashMap和双向链表。LoadFactor和capacity对 LinkedHashMap的影响是很大的。
特点:
- 其提供了access-ordered和 insertion-ordered两种排序方式
- 初始容量对于遍历是没有影响的
下面会具体解释
5.2 LinkedHashMap 是什么组成的?
LinkedHashMap 的底层重写了HashMap的Node,叫做Entry。
其在继承的基础之上对每个节点添加了前置指针和后置指针,那么就可以拿到其before和after。这是后面说的其内部维护的双向链表的基础。
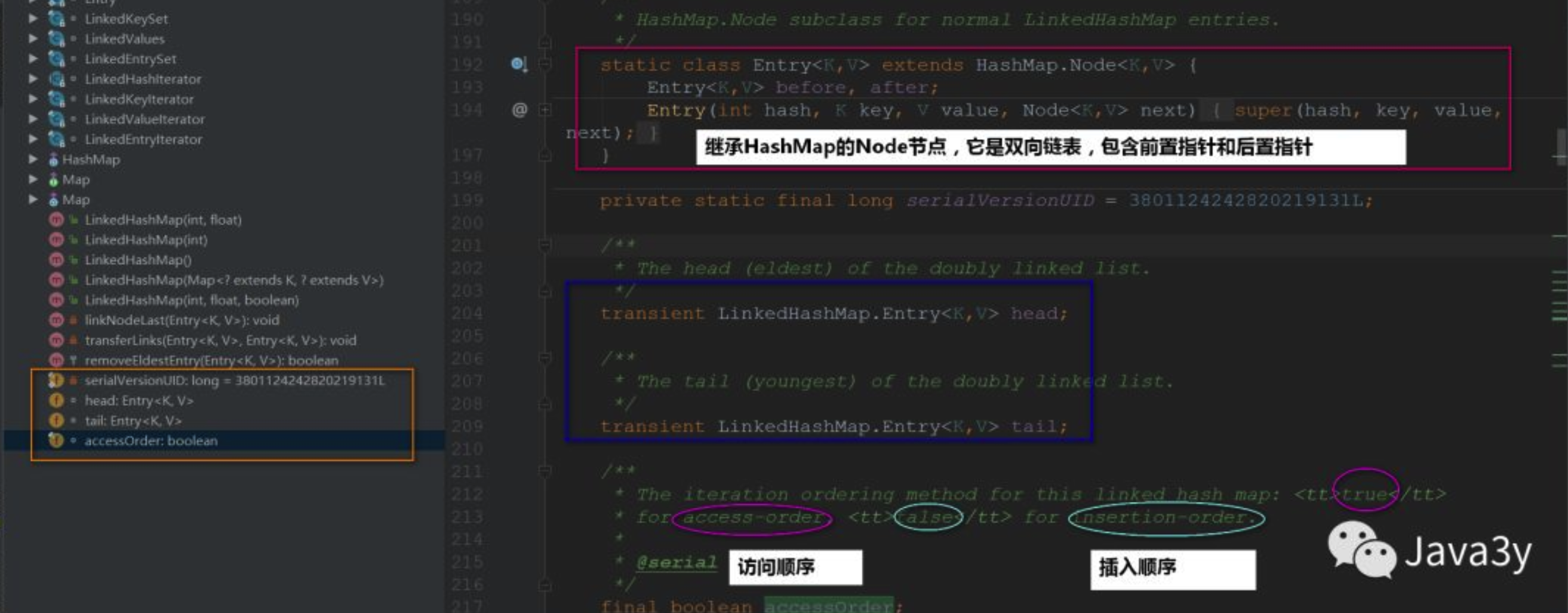
在构建新节点的时候,直接构建LinkedHashMap.Entry。
5.3 怎么用?
5.3.1 构造方法
一共有五个:

按照我们之前对于HashMap的理解,可以猜测:
- 默认构造:默认capacity和load_factor
- 自定义capacity
- 自定义capacity和load_factor
- ????这里有个boolean是干嘛?后面会讲。这个是控制其是否为 access-ordered,默认false
- 显然是将另一个Map的所有内容复制到这个LinkedHashMap之中。
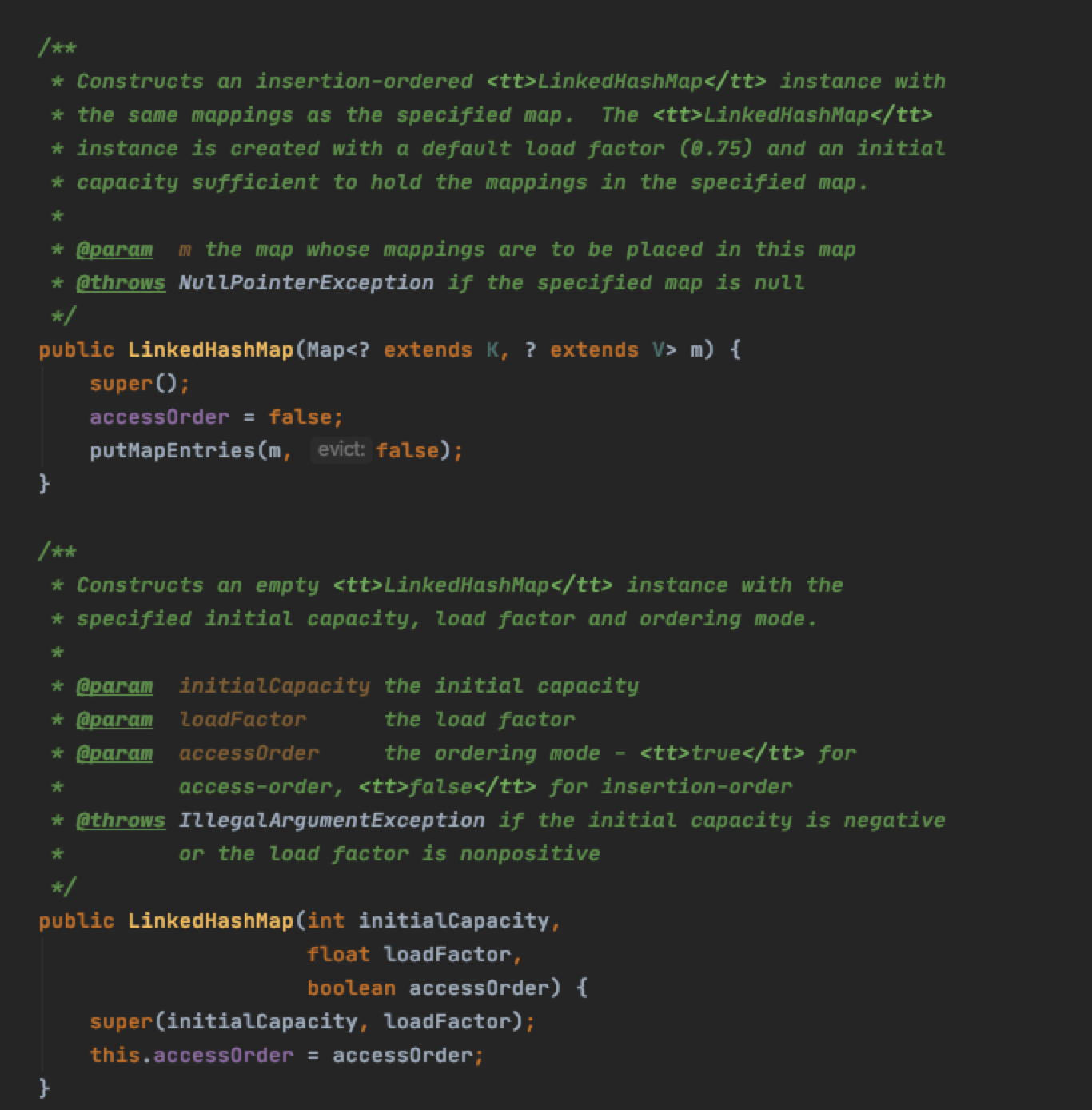
随便截两个,可以看出其默认就是false的,只有自定义的时候才是传参。
5.3.2 put方法
除了创建节点时候是调用LinkedHashMap的Entry,其他和HashMap一样。
5.3.3 get方法
这里就有点东西了:
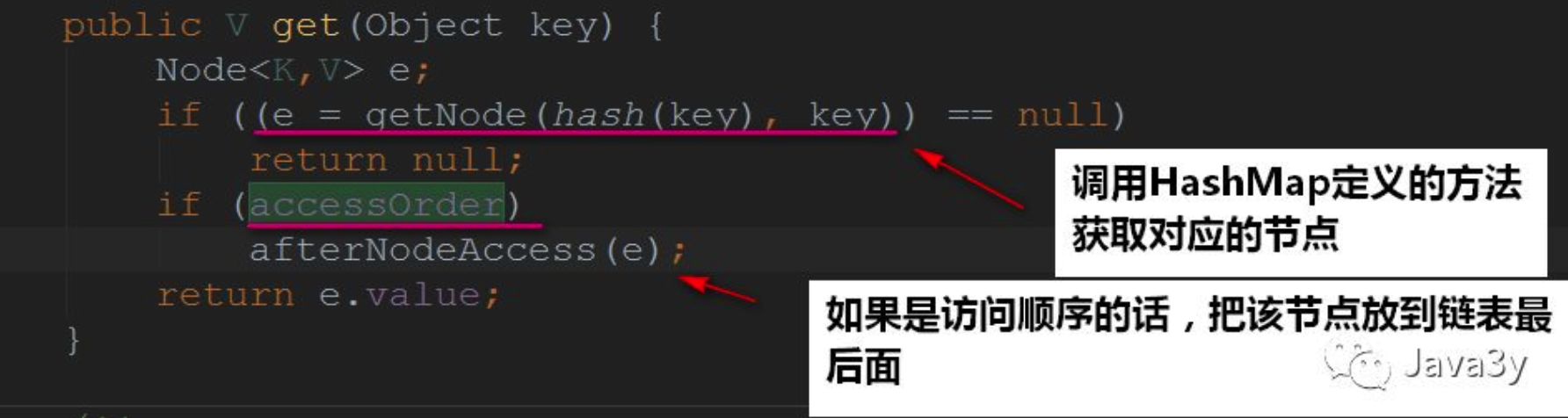
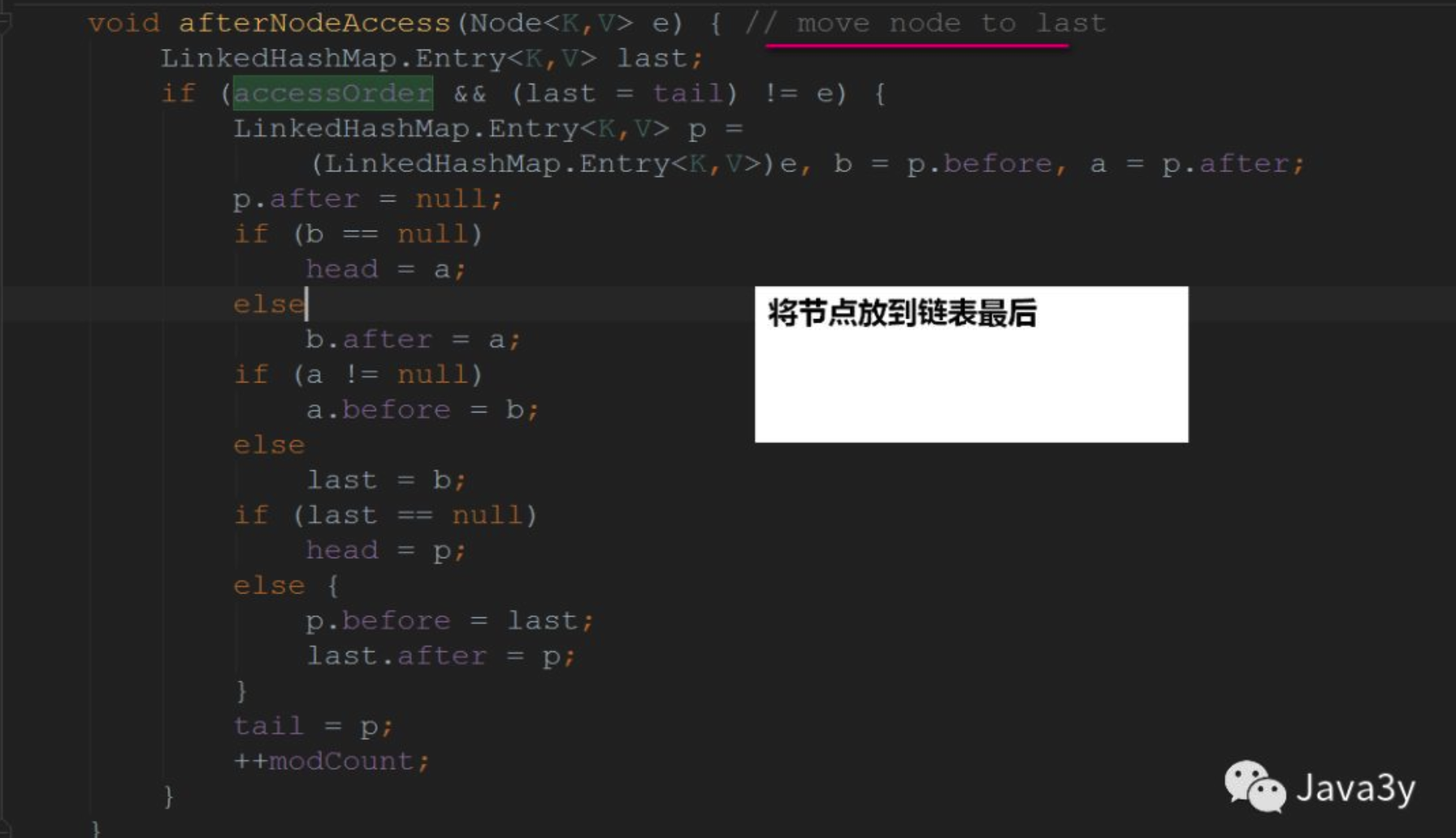
如果是访问顺序,那么就将节点放在最后。
来一波测试,访问顺序:
package UseToStudyJavaClass.CollectionStudy;
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.Set;
public class LinkedHashMapTest {
public static void main(String[] args) {
LinkedHashMap<Integer, String> linkedHashMap = new LinkedHashMap<>(16,0.75f,true);
String value = " times";
int i = 0;
linkedHashMap.put(10, 10 + value);
linkedHashMap.put(i++, i + value);
linkedHashMap.put(i++, i + value);
linkedHashMap.put(i++, i + value);
linkedHashMap.put(i++, i + value);
Set<Integer> set = linkedHashMap.keySet();
for (Integer integer : set) {
String mapValue = linkedHashMap.get(integer);
System.out.println(integer+" "+mapValue);
}
String s = linkedHashMap.get(2);
set = linkedHashMap.keySet();
for (Integer integer : set) {
String mapValue = linkedHashMap.get(integer);
System.out.println(integer+" "+mapValue);
}
}
}
其结果为:
10 10 times
Exception in thread "main" java.util.ConcurrentModificationException
at java.util.LinkedHashMap$LinkedHashIterator.nextNode(LinkedHashMap.java:719)
at java.util.LinkedHashMap$LinkedKeyIterator.next(LinkedHashMap.java:742)
at UseToStudyJavaClass.CollectionStudy.LinkedHashMapTest.main(LinkedHashMapTest.java:20)
Disconnected from the target VM, address: '127.0.0.1:57561', transport: 'socket'
直接报错:ConcurrentModificationException。
那么说明了在access_order下面,使用get()得到的是结构性的修改。
这个用来干什么呢?注释之中已经给我们写清楚了:
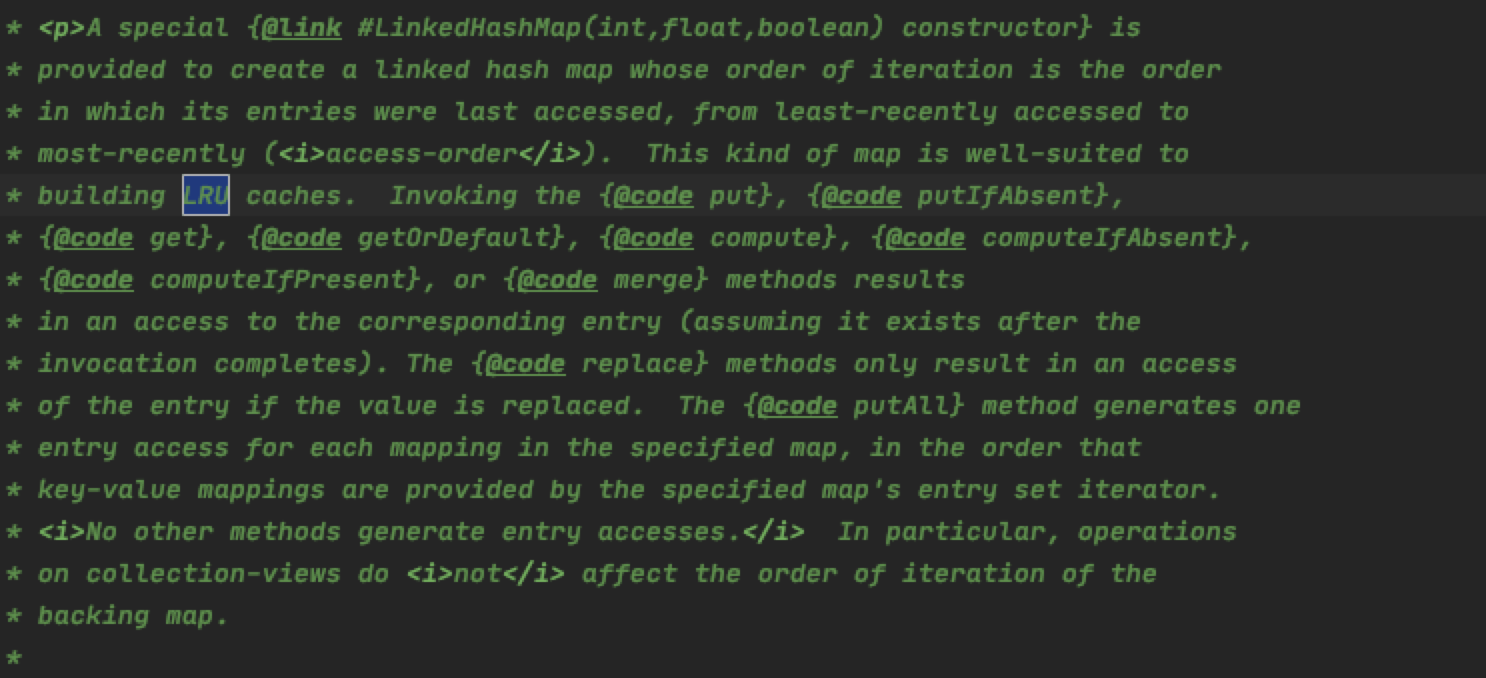
我们都看到过自己实现一个LRU的这个题目吧?这里就是LinkedHashMap可以用作LRU的根本。相应的还有两个方法:
-
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) { return false; }
这个方法默认是false,在实现LRU的时候我们要重写成return size()>capacity。
-
void afterNodeInsertion(boolean evict) { // possibly remove eldest LinkedHashMap.Entry<K,V> first; if (evict && (first = head) != null && removeEldestEntry(first)) { K key = first.key; removeNode(hash(key), key, null, false, true); } }
还有一个是这个,这个是删除最老节点的执行方法。只要上面的removeEldestEntry判断是true,其就会将最老的节点删除。
上一个自己的LRU代码:
class LRUCache extends LinkedHashMap<Integer, Integer>{
private int capacity;
public LRUCache(int capacity) {
super(capacity, 0.75F, true);
this.capacity = capacity;
}
public int get(int key) {
return super.getOrDefault(key, -1);
}
public void put(int key, int value) {
super.put(key, value);
}
@Override
protected boolean removeEldestEntry(Map.Entry<Integer, Integer> eldest) {
return size() > capacity;
}
}
5.3.4 remove()
其没重写HashMap的remove() 方法,而是重写了afterNodeRemoval(Node<K,V> e)这个方法,相当于删除的时候
我们先看这三个在hashMap之中的方法:
// Callbacks to allow LinkedHashMap post-actions
void afterNodeAccess(Node<K,V> p) { }
void afterNodeInsertion(boolean evict) { }
void afterNodeRemoval(Node<K,V> p) { }
hashMap之中给LinkedHashMap预留的方法在这。
再看LinkedHashMap的实现:
void afterNodeRemoval(Node<K,V> e) { // unlink
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.before = p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a == null)
tail = b;
else
a.before = b;
}
可以看出其直接将HashMap之中的Node<K,V>强制转换成了LinkedHashMap之中的 Entry<K,V>,然后对其做操作。
5.3.5 遍历的方法
其遍历的方法Set<Map.Entry<K,V>> entrySet()是重写了的,其中主要的就是将返回的值变成了Entry<>,且其会从内部维护的双链表的头部开始循环输出。
我们一开始讲了两个特点,这个就和第二个特点“初始容量对于遍历是没有影响的”相关。因为遍历的时候玩的是内部维护的这个双向链表,自然不是走的去遍历每个bundle的方式,也就和初始容量无关了。
6. TreeMap
6.1 是什么?有什么特点?
是一个底层为红黑树的有序的Map。
6.2 怎么用?如何实现?
6.2.1 构造方法
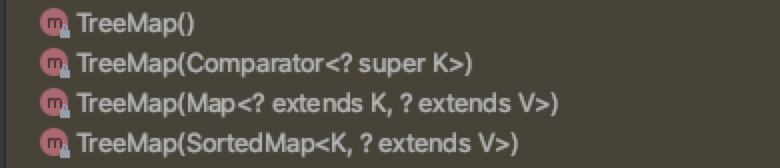
四个,基本上区别就是有没有Comparator传进来。下面两个就是将其他的Map之中的值放进来。
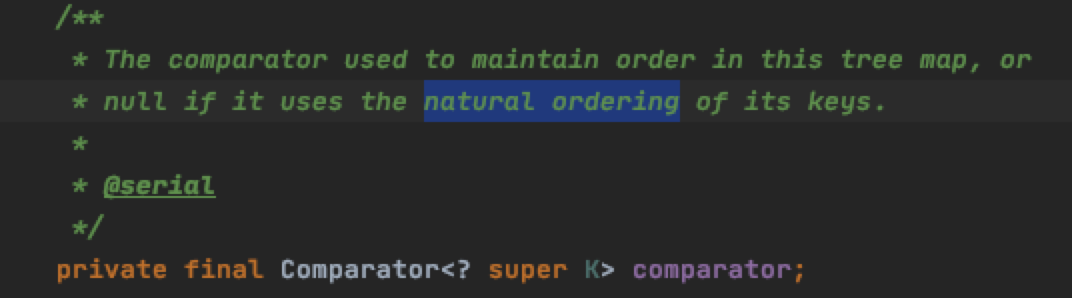
如果comparator是null,那么意味着其是自然排序。自然排序:1,2,3,4,5……
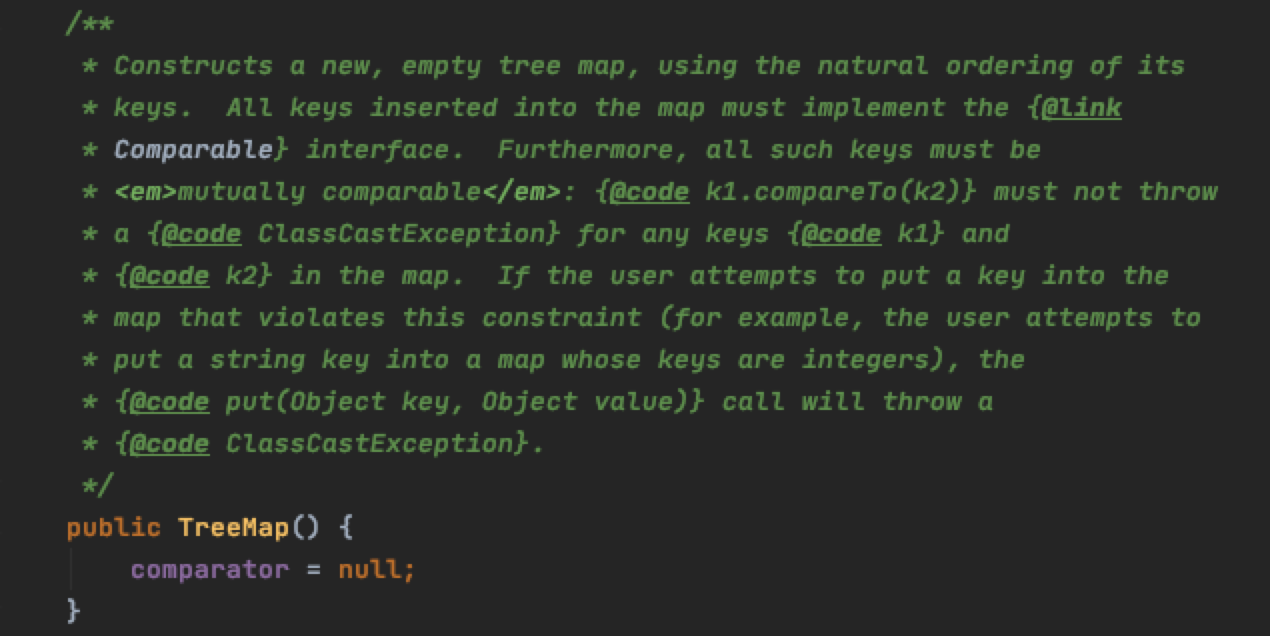
默认的构造方法,comparator传入null,是自然排序。
6.2.2 put()
- key不可以为null。如果是null直接抛出异常。
- 红黑树为null的话新建红黑树
- comparator比较,找到合适的位置并且将其放入红黑树之中。如果没有comparator,自动使用key作为参数来比较,key必须实现Comparable接口。
注意这边的Comparator可以使用lambda表达式直接写。
6.2.3 get()
使用compareTo()方法来进行比较,从红黑树之中找到对应的值并返回,都没有的话直接返回null。
6.3 有什么坑?
TreeMap 之中的所有的key 都不可以为null,因为要使用comparator进行比较。
其底层是红黑树,那么时间复杂度可以保证为O(log(n))。
7. ConcurrentHashMap详解
7.1 是什么?有什么特点?
其底层和HashMap相同,散列表+红黑树。其特点为在多线程的时候可以保证安全。
7.2 怎么用?如何实现?
其实现方式是部分加锁(每次写的时候只对于一个bundle加锁),还有CAS关键字(对于sizeCtl等值的操作)。
其还使用了volatile,用于可见性。其原理是禁止重排序和使用读写内存屏障。前者保证了其前面的顺序和后面的顺序不变,后者保证了其只要在主存之中有改动,那么直接将其他CPU之中的缓存废掉;或者是只要修改了就将值写回主存。
7.2.1 构造方法
- 其构造方法有几种
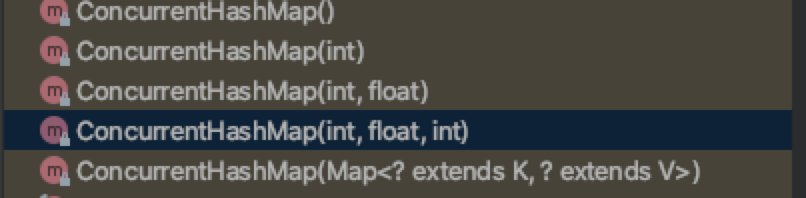
找一个参数最全的:
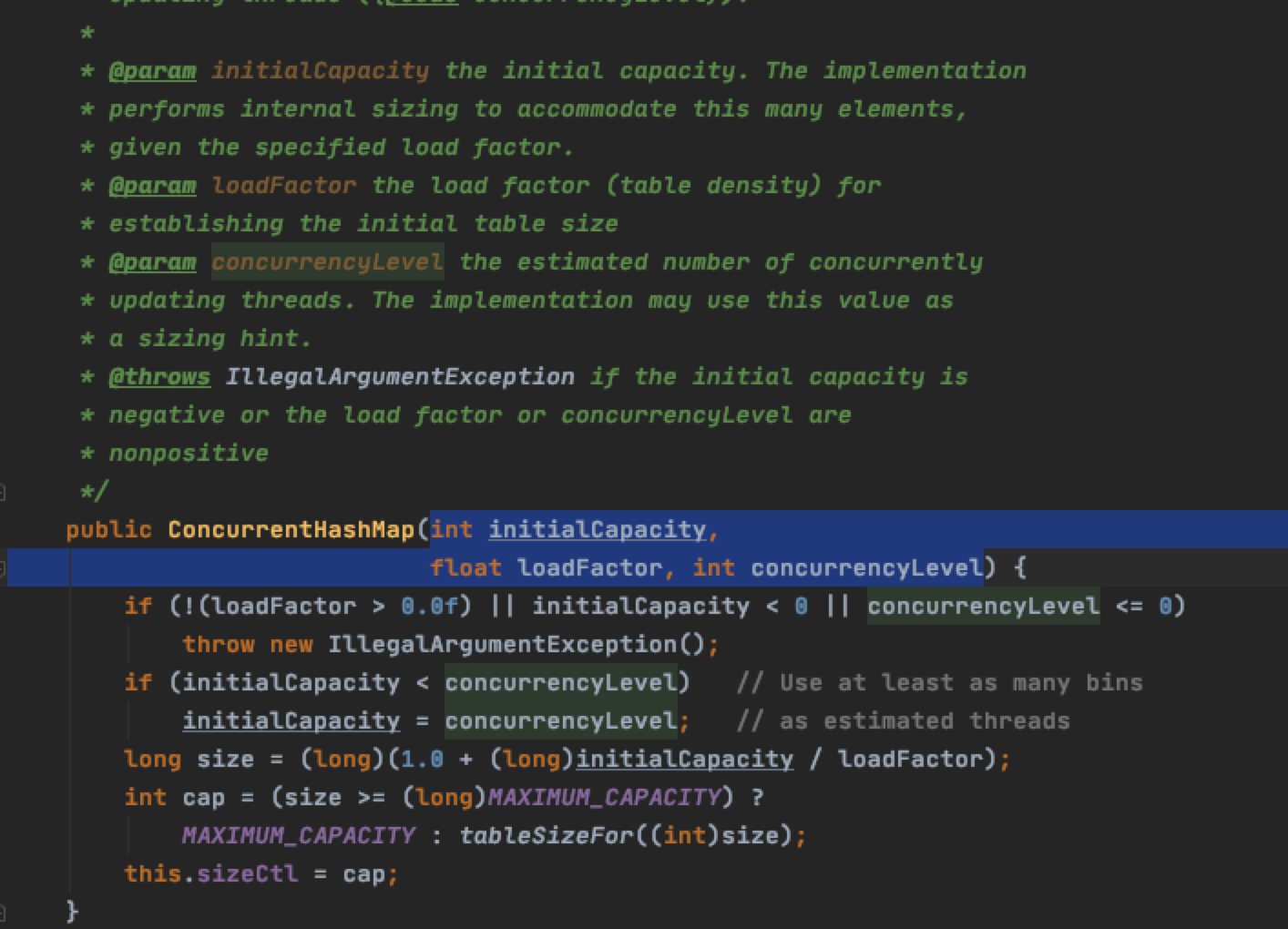
无非就是在HashMap的基础之上加了一个并发度:允许多少个线程同时修改。其中的tableSizeFor() 和HashMap之中的一样,就是将其变成离这个值最近的2的n次幂。
7.2.1 put(), initTable()
之前已经总结过,不再赘述。
7.2.2 get()
get是不加锁的,因为其使用了volatile修饰,所以每次获取的都是最新设置的值。
7.3 有什么坑?
ConcurrentHashMap的key和value都不为null。
8. Set
- HashSet: 底层数据是哈希表+红黑树。就是V为特殊形式的HashMap
- TreeSet:底层数据是红黑树,其保证元素的排序方式
- LinkedHashSet:底层数据是哈希表和双向链表组成
啥是哈希表?就是一个元素为链表的数组
8.1 HashSet
特点:
- 允许元素为null
- 底层是一个HashMap
- 初始容量非常影响迭代性能。
/**
* Constructs a new, empty set; the backing <tt>HashMap</tt> instance has
* default initial capacity (16) and load factor (0.75).
*/
public HashSet() {
map = new HashMap<>();
}
看,底层的确就是一个HashMap。
那么我们说了对于HashSet,其中的Node<K,V>之中的V就是一特殊的东西。是啥?
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
所有的Value相同,都是一个Object而已。
8.2 TreeSet
底层是TreeMap,时间复杂度什么的都相同:log(n)。其value和上面的一样,就是一个叫做PRESENT的Object。
8.3 LinkedHashSet
迭代有序,允许为null,底层实际是一个HashMap+双向链表的实例——就是一个LinkedHashMap的实现。
初始容量和迭代无关,因为其迭代的是双向链表。
9. Copy on Write
9.1 是什么
COW在每次修改的时候,比如add(),clear(),remove(),get()等等,都会先加锁,然后复制一个新的数组出来,在这个上面进行修改,然后再将指针指向新的数组。在遍历的时候则不会使用新数组,支持多个线程同时遍历。
9.2 为什么会出现?
一般在一些比较基础的部分,比如Vector,之中是将所有的方法都synchronized来保证线程安全的。
但是多线程情况下还是可能出现问题,比如一个要getLast(),一个要removeLast(),然后线程a刚执行完找下标的部分就挂起了,然后removeLast()执行完毕,那么getLast()恢复的时候就会发现自己要拿的东西没了。
那么如何避免呢?有一种方法是将整个对象都锁起来,那真的太麻烦了。这个时候就出现了CopyOnWrite这种方式来进行同步的替代。
9.3 以CopyOnWriteArrayList为例
9.3.1 写加锁,读不加锁
在修改的时候,复制出一个新的数组,修改的操作全在新数组之中完成,最后把新数组交给array变量指向。
写加锁,读不加锁。
9.3.2 在容器遍历的时候对其进行修改而不抛出异常
// 1. 返回的迭代器是COWIterator
public Iterator<E> iterator() {
return new COWIterator<E>(getArray(), 0);
}
// 2. 迭代器的成员属性
private final Object[] snapshot;
private int cursor;
// 3. 迭代器的构造方法
private COWIterator(Object[] elements, int initialCursor) {
cursor = initialCursor;
snapshot = elements;
}
// 4. 迭代器的方法...
public E next() {
if (! hasNext())
throw new NoSuchElementException();
return (E) snapshot[cursor++];
}
//.... 可以发现的是,迭代器所有的操作都基于snapshot数组,而snapshot是传递进来的array数组
这里面的snapshot,传进来的就是原来的数组。所以如果一个线程正在修改老的数组,其他线程也可以读到值,但是是原数组的值。
9.4 缺点?
- 内存占用高:每一次修改的时候都是新建一个副本,在副本上面进行操作,内存占用率过高。
- 数据一致性:只能保证最终一致性,保证不了实时一致性。