还是看3y的公众号总结。
1. Redis底层数据结构实现
此处是 Redis 设计原则的书:http://redisbook.com/preview/object/string.html
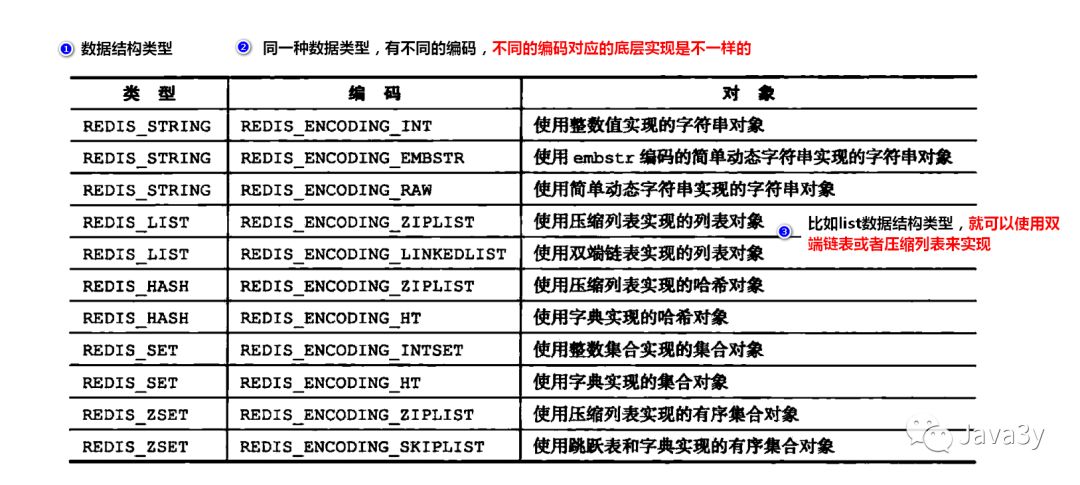
Redis底层是K-V对,其键值只能是String,但是Value可以是以下五种形式。
其创建一个新的K-V对的时候,K和V会分开创建,也就是说一次创建两个对象。
1.1 String
在上面的图我们知道string类型有三种编码格式:
-
int:整数值,这个整数值可以使用long类型来表示
-
- 如果是浮点数,那就用embstr或者raw编码。具体用哪个就看这个数的长度了
-
embstr:字符串值,这个字符串值的长度小于32字节
- raw:字符串值,这个字符串值的长度大于32字节
embstr和raw的区别:
- raw分配内存和释放内存的次数是两次,embstr是一次
- embstr编码的数据保存在一块连续的内存里面
编码之间的转换:
- int类型如果存的不再是一个整数值,则会从int转成raw
- embstr是只读的,在修改的时候回从embstr转成raw
1.2 list对象
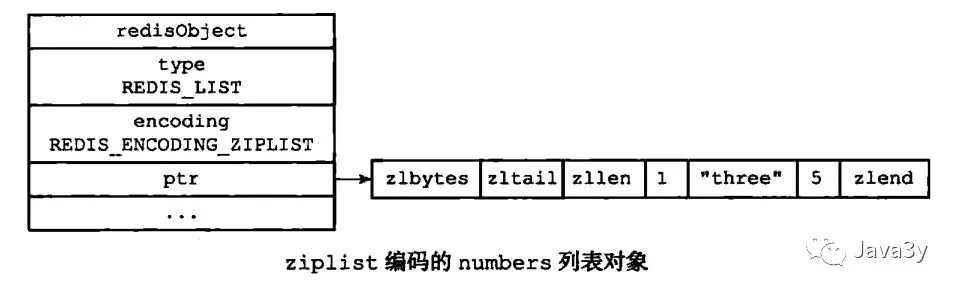
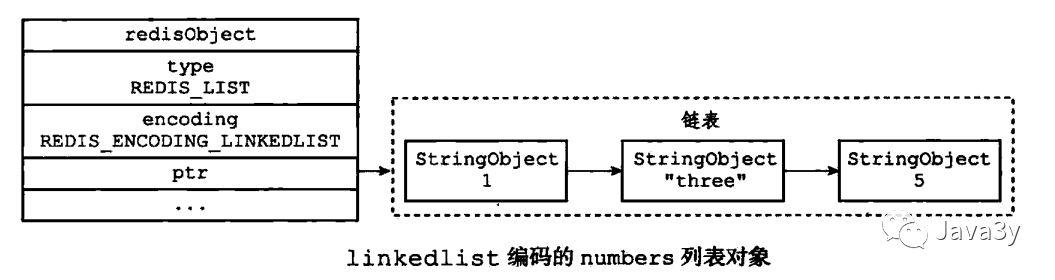
根据长度不一样有不同的编码格式,比如:
- ziplist: 字符串的元素长度都小于64个字节,并且总数量小于512个
- linkedlist:字符串的元素长度大于64字节,或者总数量大于512个
ziplist编码的list结构:
linkedlist编码的list结构:
而且原本是ziplist编码的,如果其保存的长度太大,或者是元素的数量过多,就会转换成linkedlist。
1.3 Hash对象
根据长度不一样也有两种编码格式:
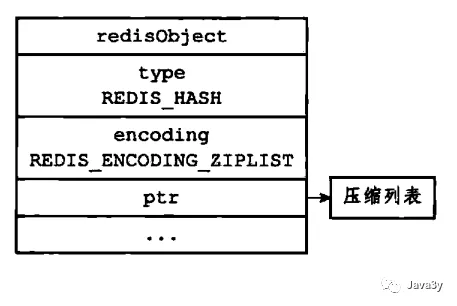
- ziplist:key 和 value的字符串长度都小于64字节,并且K-V对的数量小于512
- hashtable:key和value的字符串长度大于64字节,或者其K-V对的数量大于512
ziplist:
hashtable编码的hash结构:
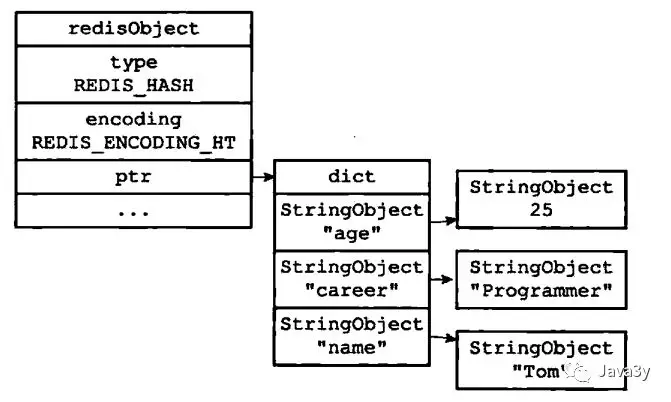
原本是ziplist编码的,如果保存的数据长度太大,或者元素数量过多,会转换成hashtable编码的。
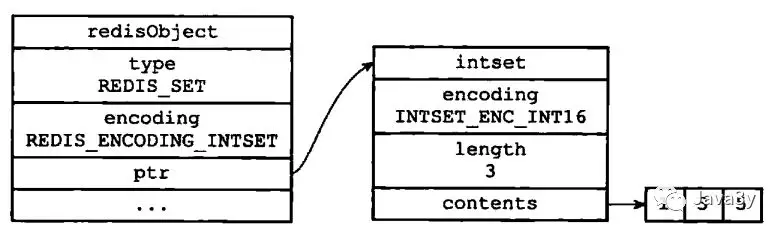
1.4 Set对象
根据不同长度还是有两种编码格式:
- intset:保存的元素全是整数,且总数量小于512
- hashtable:保存的元素不是整数,或者总数量大于512.
intset编码的集合结构:
hashtable编码的集合结构:
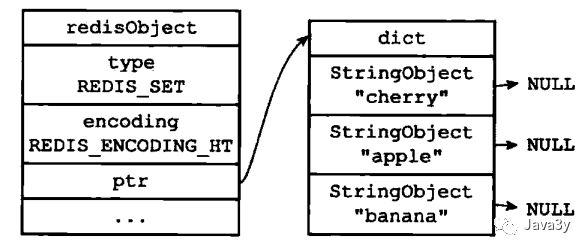
原本是intset编码的,如果保存的数据不是整数值或者元素数量大于512,会转换成hashtable编码的。
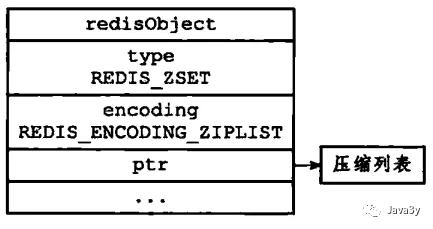
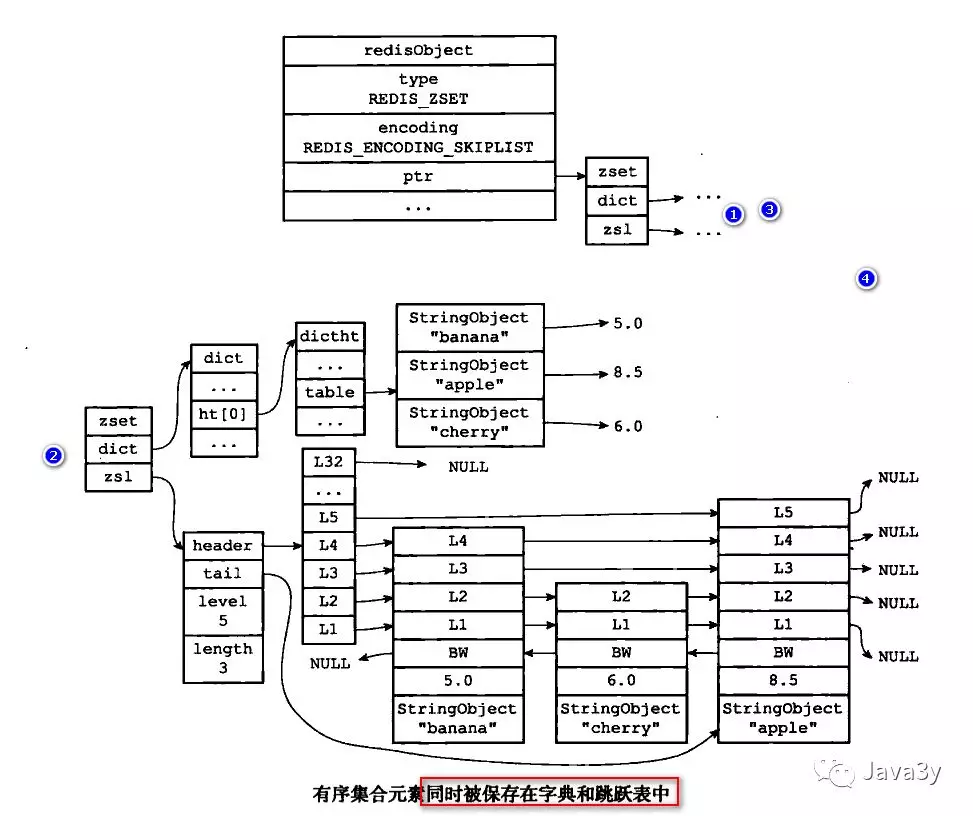
1.5 zset对象
有两种编码格式:
- ziplist:元素长度小于64,且总数量小于128
- skiplist:元素长度大于64或者总数量大于128
ziplist的zset结构:
skiplist的zset结构:
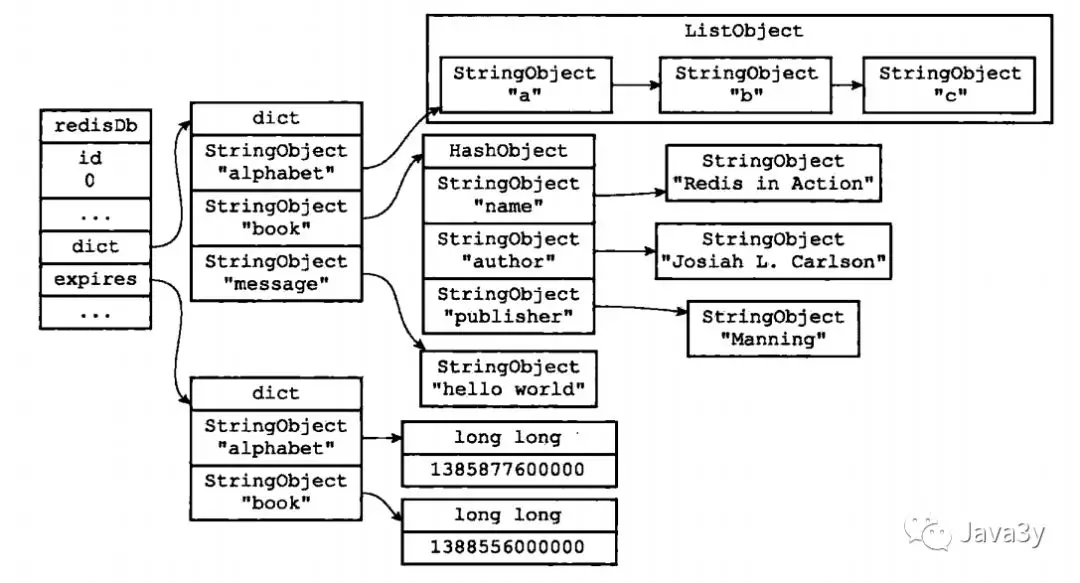
2. Redis的数据库
Redis的数据库之间彼此隔离。
3. Redis键的过期时间
3.1 如何使用?
- Redis的生存时间可使用EXPIRE或者PEXPIRE命令。
- Redis的过期时间可以使用EXPIREAT或者PEXPIREAT
另外三种的实现方式实际也是通过PEXPIREAT来实现的。
3.2 过期策略
Redis使用的是惰性删除+定期删除策略:
- 惰性删除:每次取这个键的时候判断一下这个键是否过期了,过期就直接删除
- 定期删除:每隔一段时间去删除过期键,限制删除的时长和频率。
3.3 内存淘汰机制
在定期删除漏掉了很多过期的key,且没有定期删除的时候,大量的过期key堆积在内存之中,导致Redis的内存快耗尽了,怎么办?
可以设置内存最大使用量,当使用量超出的时候,使用数据淘汰策略。
Redis的淘汰策略:

这个LRU看着熟不熟悉?
4. Redis持久化
Redis提供了两种不同的持久化方法来将数据存储到硬盘之中:
- RDB:基于快照,将某时刻的全部数据保存到一个RDB文件之中
- AOF(append-only-file),当Redis服务器执行写命令的时候,将执行的写命令保存到AOF文件之中。
4.1 RDB(快照持久化)
RDB生成的文件是一个经过压缩的二进制文件,Redis可以通过这个文件还原数据库的数据。
两个命令生成:
save,会阻塞Redis服务器进程,服务器不接受任何请求直到创建完成——不可接受,没人用BGSAVE:创建一个子进程,子进程创建RDB文件,服务器进程接着来。
4.2 AOF(文件追加)
原理:通过保存Redis服务器执行的写命令来记录数据库之中的数据的。
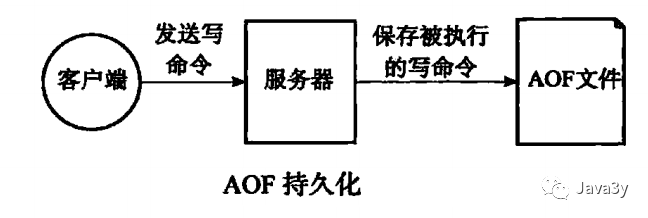
redis> SET meg "hello"
OK
redis> SADD fruits "apple" "banana" "cherry"
(integer) 3
redis> RPUSH numbers 128 256 512
(integer) 3
上面的命令,会生成下面的AOF文件:

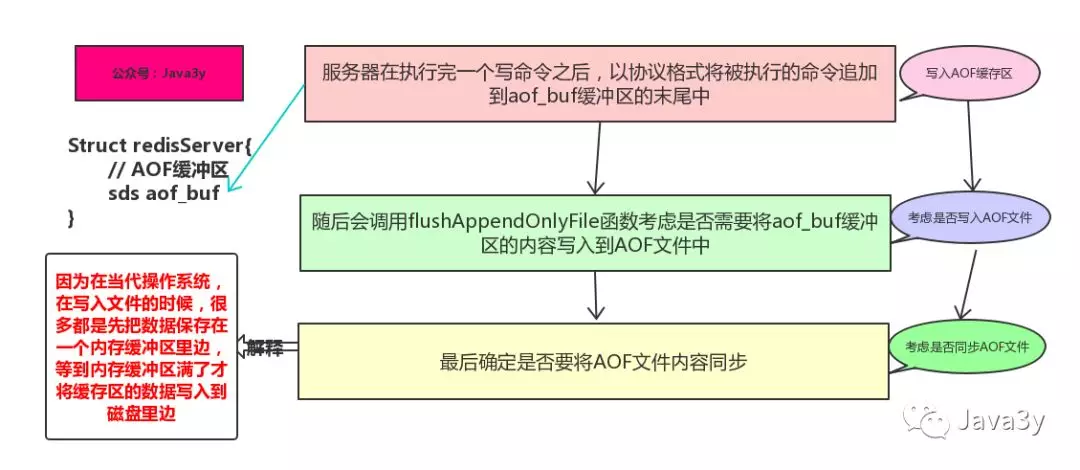
AOF的持久化分为三个步骤:
- 命令追加:命令写入aof_buf缓冲区
- 文件写入:调用flushAppendOnluFile函数,考虑是否将aof_buf之中的数据写入AOF文件之中
- 文件同步:考虑是否将内存缓冲区之中的数据真的写入硬盘
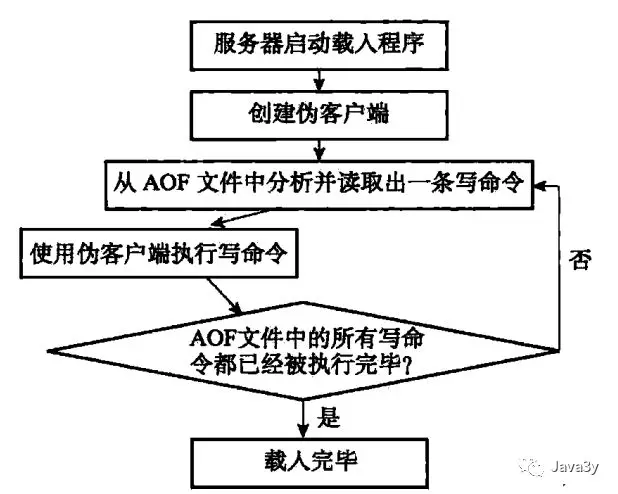
4.2.1 AOF载入和数据还原
创建一个伪客户端执行AOF的命令,直到AOF命令全部执行完毕。
4.2.2 AOF重写
有的时候,一些命令可以合并起来作为一条,这样可以让AOF的体积变得更小。
AOF重写不需要对当前的AOF文件进行任何的读取或者分析!是通过读取服务器当前数据库的数据来实现的。
这是重写之后的AOF文件:没有再合并的可能

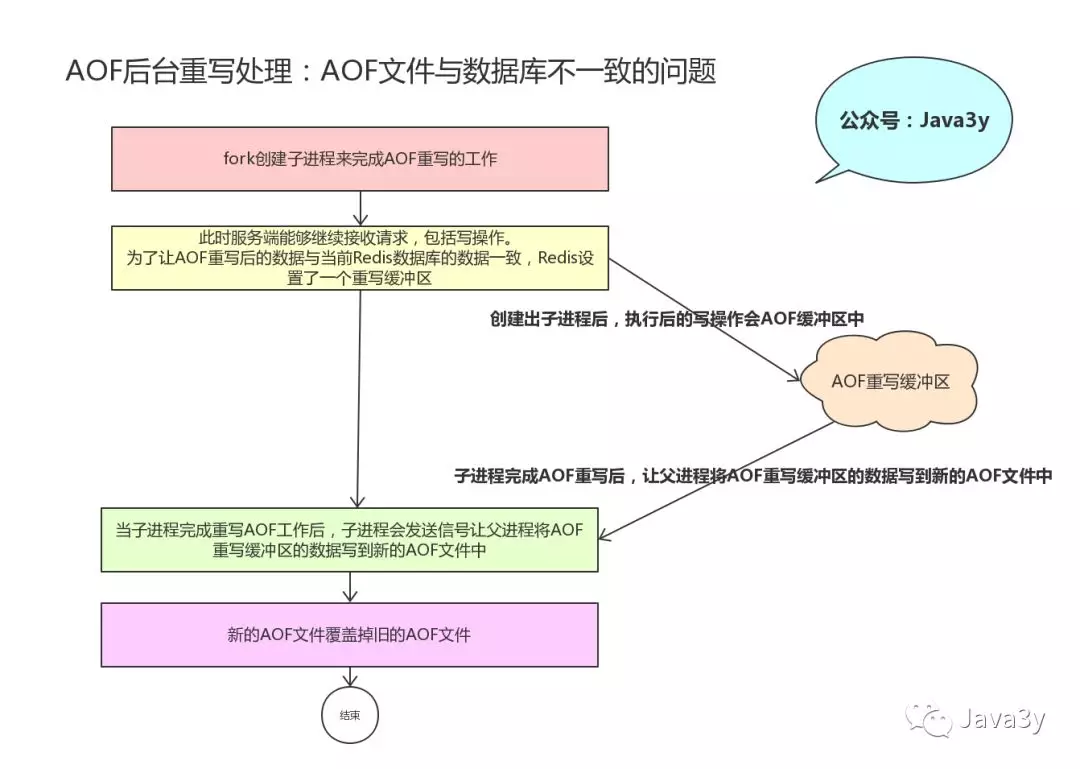
4.2.3 AOF后台重写
后台fork一个子线程来进行重新写AOF的操作,但是在这个期间Redis的数据可能已经改变,那么可能造成数据不一致的情况。
Redis设置了一个AOF缓冲区,这个缓冲区会在服务器创建出子进程之后使用。
4.2.4 RDB和AOF对过期键的策略
RDB持久化对过期键的策略:
- 执行
SAVE或者BGSAVE命令创建出的RDB文件,程序会对数据库中的过期键检查,已过期的键不会保存在RDB文件中。 - 载入RDB文件时,程序同样会对RDB文件中的键进行检查,过期的键会被忽略。
RDB持久化对过期键的策略:
- 如果数据库的键已过期,但还没被惰性/定期删除,AOF文件不会因为这个过期键产生任何影响(也就说会保留),当过期的键被删除了以后,会追加一条DEL命令来显示记录该键被删除了
- 重写AOF文件时,程序会对RDB文件中的键进行检查,过期的键会被忽略。
复制模式:
- 主服务器来控制从服务器统一删除过期键(保证主从服务器数据的一致性)
5. Redis NIO和事件
Redis事件分为两种:
- 文件事件,实际就是对socket的抽象,服务器通过监听并且处理这些事件来完成一系列的网络操作
- 时间事件,是定时操作的抽象,比如RDB,AOF,这些都可以由服务端去定时或者周期完成。
6. Redis主从复制
主负责写,从负责读
6.1 复制功能
复制功能的具体实现:
- 同步(Sync):将从服务器的状态更新至主服务器的数据库状态。
- 命令传播:主服务器的数据库状态被修改,主从服务器的数据库状态不一致,那么让主从服务器的数据库状态回到一致。
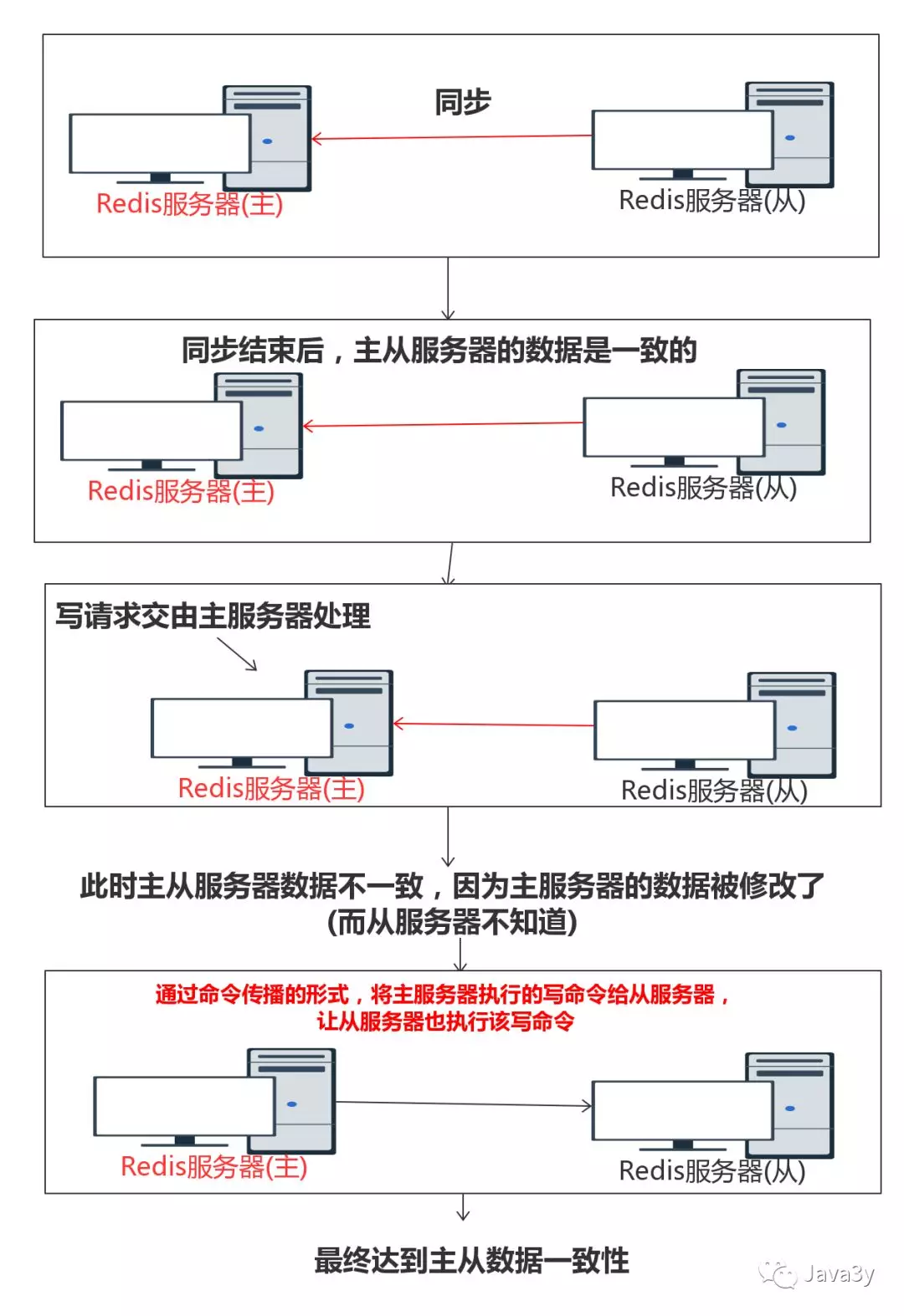
那么同步就会分为两种:
- 初次同步:从服务器没有和这个主服务器同步过
- 断线后同步:在命令传播阶段的主从服务器因为网络原因产生了断链,从服务器自动重连主服务器,并且继续复制主服务器。
Redis2.8之前断线之后的同步也是全量复制,之后就是断点续传了。
6.1.1 复制的前置工作
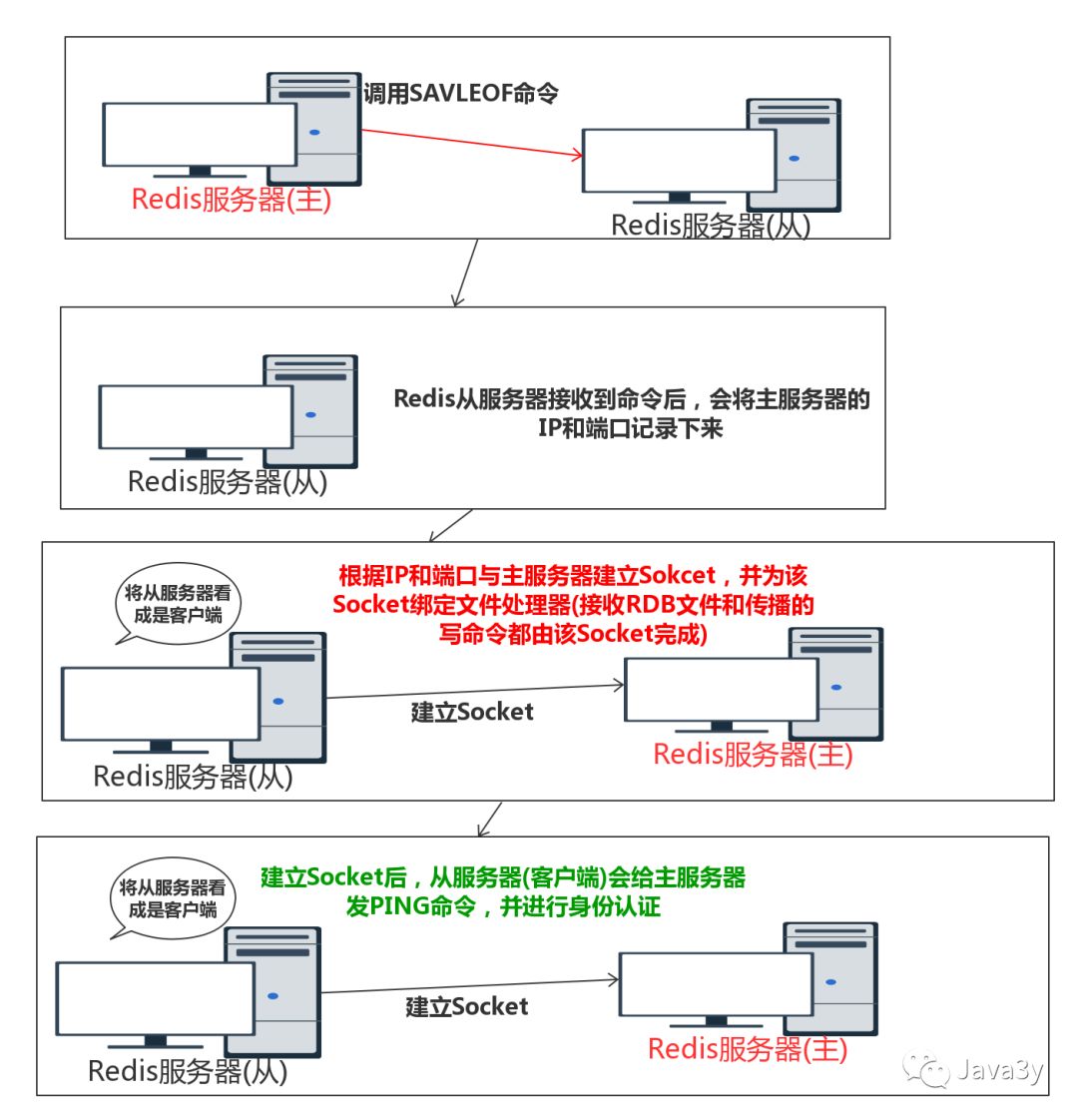
从2.8开始,redis使用psync命令替代sync命令执行复制同步的操作。
6.1.2 完整重同步
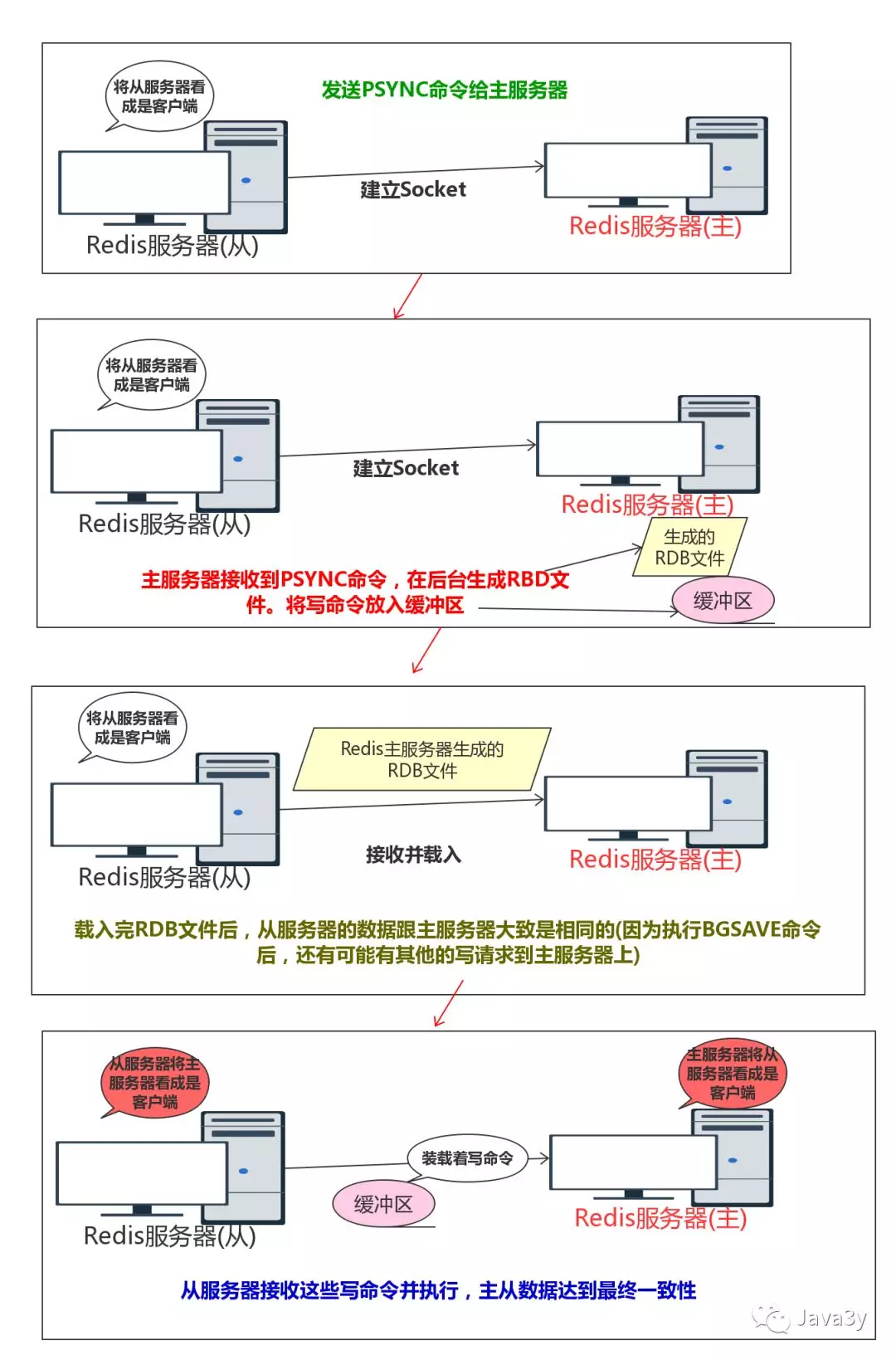
从服务器发送PSync,然后主服务器自己执行BgSave,生成的RDB文件发送给从服务器。之后从服务器接收和载入RBD文件并还原,之后主服务器将所有缓冲区的写命令发送给从服务器,从服务器执行这些写命令,达到最终一致性。
6.1.3 部分重同步
部分重同步功能由以下部分组成:
- 主从服务器的复制偏移量
- 主服务器的复制积压缓冲区
- 服务器运行的ID(run ID)
主要是这个偏移量。
当主服务器进行命令传播时,不仅仅会将写命令发送给所有的从服务器,还会将写命令入队到复制积压缓冲区里面(这个大小可以调的)。如果复制积压缓冲区存在丢失的偏移量的数据,那就执行部分重同步,否则执行完整重同步。
6.1.4 命令传播
从服务器每秒一次,向主服务器之中发送命令,其中带有自己当前的复制偏移量。
这个可以用来检测网络状态,除此之外还有:
- 辅助实现min-slaves选项
- 检测命令丢失
7. Redis集群
集群之中会有哨兵机制。哨兵是监控各个主机的状态,并且根据状态来进行主从切换以及选举等等。
脑裂的产生和后果:
- 有时候主服务器脱离了正常网络,跟其他从服务器不能连接。此时哨兵可能就会认为主服务器下线了(然后开启选举,将某个从服务器切换成了主服务器),但是实际上主服务器还运行着。这个时候,集群里就会有两个服务器(也就是所谓的脑裂)。
- 虽然某个从服务器被切换成了主服务器,但是可能客户端还没来得及切换到新的主服务器,客户端还继续写向旧主服务器写数据。旧的服务器重新连接时,会作为从服务器复制新的主服务器(这意味着旧数据丢失)。
主要就是其数据丢失问题。
如何解决:
min-slaves-to-write 1
min-slaves-max-lag 10
第一个规定一个master必须有至少一个salve,第二个规定数据的同步和延迟不能超过10秒,不然master直接拒绝写请求。