1. WebSocket是什么原理?为何可以实现持久连接?
websocket是一个协议,其是借助HTTP进行连接,在连接完成之后切换成WebSocket协议。
且websocket可以主动推送信息给客户端。
2. 什么是JMM?
JMM,Java Memory Model,其是一种符合内存模型规范的,屏蔽了各种硬件和操作系统差异的,保证了Java程序在各种平台下面对内存的访问都能保持一直效果的规范。
其规定了所有的变量都在主内存之中存储,每个线程有自己的工作内存,线程的工作内存之中保存了主内存的副本拷贝,线程对变量的所有操作都必须在工作内存之中进行。不同线程之间无法直接访问对方工作内存之中的变量,线程之间变量的传递都需要自己的工作内存和主存之间进行数据同步进行。
3. ping的原理是什么
ping的原理是:对于每个网络上的IP地址,我们都需要去给目标IP地址发送一个数据包,对方也得返回一个同样大小的数据包。那么根据返回的数据包就可以确认对方存在。
4. traceroute和原理
是什么?
是让我们看到IP数据包从一台主机到另一台主机所经过的路由。
原理?
计数多发:将报文之中的TTL字段每次加一并发送,那么就能知道从近到远的IP地址,继续这个过程,直到达到目的主机,那么就知道了所有路径上面的IP地址。
5. Spring循环依赖问题与如何解决
Spring之中的循环依赖问题分为三种:
- 在constautor()之中的循环依赖:没法解决,看到实例化的时候自己在池子之中直接报错
- 单例模式下的循环依赖:通过三级缓存:
- singletonFactories:三级,进入实例化阶段的单例对象工厂的cache
- earlySingletonObjects::二级,完成实例化,但是尚未初始化的,提前曝光了的对象的cache
- singletonObjects:完成初始化的单例对象的cache(一级缓存)
其中的singletonFactoried的类型是ObjectFactory,定义之中有getObject:
public interface ObjectFactory<T> {
T getObject() throws BeansException;
}
那么在createBeanInstance之后,populateBean()之前,这时候单例对象已经被构造器创建出来了,这个时候将这个对象提前曝光,让大家使用。
- 非单例循环依赖:无法完成依赖注入,因为Spring不缓存prototype作用域的bean
6. Redis如何实现分布式锁
命令之中是setnx key value,那么这个时候如果这个key已经有人占用了,就直接返回0.
但是这样会有超时时间的问题,比如线程1拿到了锁,但是死了,那么其他的线程就拿不到锁了。这种情况的对应方式就是设置一个超时时间,expiretime。
看起来完美了?实际不是这样。在java之中设置锁和设置超时时间是分开的,那么如果执行完第一句,拿到锁了之后死了,该怎么办?
两种方法:
- 使用lua脚本,这样可以保证这个操作的原子性,即一定同时成功或者失败
- 在value之中放入过期时间,其他机器检查时间是否过期,过期的话就直接
getset jey value。这个是获取当前key的值,并设置新的值。如果这个返回的值也是过期的,说明修改成功了。没过期,说明自己拿到的锁是别人修改过的,那么自己就不要再去尝试拿锁了。——一点小问题是会延长锁的时间,因为可能getset好几次。但是无伤大雅。
7. Collections.sort() 原理
短的时候使用的是归并排序,长的时候是TImSort,就是找到其中有序的子区间,然后直接对两个子区间进行排序。
8. Spring有哪些依赖注入方式?都有什么区别?
Spring主要有两种依赖注入方式,其区别在于要不要在初始的时候传参:
- 构造器注入:容器触发另一个类的有参构造器实现的,其有一系列的参数,每个参数都代表一个对于其他类的依赖
- setter注入:容器调用的是无参构造器,然后对于这个bean进行setter的方式来注入
两种依赖方式都可以使用,最好的方案是使用构造器参数实现强制依赖,使用setter注入实现可选依赖。
9. Spring 之中的bean的生命周期
- 从XML或者annotation之中得到bean defination。
- 使用bean defination 实例化 bean。
- 根据 bean 的定义填充所有的属性——constructor或者是setter
- 调用相应的postProcesser 等等,进行AOP注入
- 实例化 bean,如果有初始化方法,那么调用初始化方法
-
将初始化之后的bean放入applicationContext之中。
- 需要的话调用destroy
10 反射
反射的主要作用有两个:
- 创建实例
- 反射调用方法
首先,当一个类被加载之后,其会产生四个对象:Class,Fields,Methods 和 Constructors。 相当于把类做了一个拆分。
那么怎么用上面的四个类来进行实例创建和方法调用呢?
- 使用Class对象获取Method的时候,需要传入方法名+参数的Class 类型。 原因是同样的一个方法名可能参数的类型不同,比如在重载的情况下。那么这个时候就得需要传入相应的方法的参数进行比较。
- 怎么创建一个实例呢?实际上
clazz.getInstance原理就是调用Constructor对象的newInstance()。所以如果想要使用反射来创建一个新的实例,必须内部有一个无参构造器。 - 调用method.invoke(obj,args)的时候为什么要传入一个目标对象?因为方法是在方法区之中的,是归属于类的,那么如果指定对象的话,可能会造成操作对象错误情况发生。
11. 如何让hashMap线程安全?
-
使用Collections.synchronizedMap来包装一下,原理就是在某些方法上面加入Synchronized:
public static <K,V> Map<K,V> synchronizedMap(Map<K,V> m) -
使用concurrentHashMap
12. 什么是Blocking?如何使用?底层原理?
BlockingQueue是一个可以队列满时让生产者阻塞,队列空时让消费者等待,当消费者消费了一个队列中的元素后,会通知生产者当前队列可用的这么一个queue。
其中主要使用的是put() 和 take()。
原理:
生产者通知消费者可以取数据,或者消费者通知生产者可以拿数据,使用的是Condition。其会满的时候await,但是在消费完一个数据之后发送一个signal。
在向队列之中插入或者取数据的时候,如果队列不可用,那么使用的是LockSupport.park(this)。
顺带一提,可以使用这个机制完成顺序输出123这种的指令。
13. MySQL主从复制是全双工还是半双工?
MySQL主从复制之中是半双工的。一旦一端开始发送消息,那么另一端需要等待发送完成之后才能响应它,所以在同步的时候一定要limit好要的信息数量,不然会多传很多冗余信息但是还没法打断。
14. 为什么wait是Object的方法?sleep不是?Lock和Condition的用法?
因为synchronized之中的锁可以是任意的Object,所以其是Object的方法。而且后来觉得这样耗费资源(每次notifyAll都是全部线程唤醒),就提出了用Condition之中的await(), signal().signalAll()代替Object中的wait(),notify(),notifyAll()。signal可以唤醒消费方或者是生产方,那么就是有选择的唤醒。
15. Redis之中的集群作用与实现
Redis集群之中如何确定每个数据都在哪?
使用``CRC16(key) mod 16834`之后得到对应的节点。
那么如何得到某个节点的位置?如何保证信息的传输?
redis集群之中,每个节点都可以和客户端连接。当其发送的消息不是这个节点所有的时候,节点会返回正确的节点位置和信息,进行重定向。重定向之中包含着负责该键的节点地址信息。
在扩容或者缩容之后,对应的节点要有所改变。在数据已经改变完成之后,就需要一个完整的重定向。redis之中使用的是gossip协议来做这个事情。每次随机选取一部分节点,进行一部分的信息广播。并且redis会和某些最老的节点进行同步通信,来保证这样一个集群的活性。
16. 分库分表的几种方式和其中区别,与分库分表之后可能造成的问题
参考:彻底搞清分库分表(垂直分库,垂直分表,水平分库,水平分表) - 战猿的文章 - 知乎 https://zhuanlan.zhihu.com/p/98392844
主要分为四种方式:
- 水平分库
- 水平分表
- 垂直分库
- 垂直分表
对于不同种类而言:
- 分库:按照业务将表进行分类,分布到不同的数据库上面。每个库可以放在不同的服务器上——突破单机瓶颈。
- 分表:将表按照一定规则进行拆分,从而使单表的容量下降。
- 水平:按条目进行分配
- 垂直:将部分列拆出单独做一张表
结合上面的基础知识,我们来讲下这四种方式的不同:
-
水平分库:将同一个表的数据按照一定的规则拆到不同的数据库之中,每个库可以放在不同的服务器上。
优点:
- 解决了单库高并发的性能瓶颈——单机瓶颈
缺点:
- 需要额外进行数据的路由操作——比如单数的表项在一个库,双数的表项在另一个,那么就需要额外的路由在操作的时候将数据引向对应的库
-
水平分表:还是在同一个库之中,只是其内容根据不同规则放在不同的表里面——比如还是按照单双数,或者是按照时间来分表
优点:
- 避免单一表数据量过大而产生的性能问题——比如没有索引的插入等等就会搞个表锁,要是全在一张表的话当场GG,或者是由于数据量过大,单表的查询性能不够快
缺点:
- 只是将表进行拆分,单个服务器上面的IO并发瓶颈还是存在。
-
垂直分库:将某些列拆分出去到另一个库,比如order表之中的数据就可以按照概要(名字,id,价格)和详情(介绍,备注等等)进行一个拆分,因为后者大家并不经常访问。
优点:
- 解决业务层面的耦合(我不想要这么多但是还得查这么多)
- 可以对不同业务进行分级管理和维护
- 重点:都拆出来了,当然可以降低单机的IO瓶颈
缺点:
- 没有解决单表的数据过大的问题
-
垂直分表:将一个表按照字段分成多个表,每个表存储一部分字段。
做法:
- 将不常用的字段单独拆一张表
- 将大字段拆成一张表,比如text,blob等等
- 将经常组合查询的列放一张表
优点:
- 避免锁表
缺点:
- 还是在一个库之中,单机IO没有提升
- 每张表的大小还是很大,没有做到单表的条目数量性能优化
- 每次写数据的时候要写多张表
上面是对其进行一个细致的梳理,下面是分库分表的劣势:
主要而言,分库分表增加了系统的复杂度,尤其是在目前的分布式系统之中,有以下的问题:
- 事务一致性问题:万一哪个表写错了,或者出问题了,要全部回滚
- 跨节点关联查询:如果分库了,那么就没法进行表的join了,某一条数据想要拿齐可能得走很多个节点,进行很多次查询
- 跨节点分页,排序
- 主键不重复——要设计全局主键,避免跨库主键重复问题。我个人的想法是可以找一个主键分配的节点,每次给某个库批量的主键,可以解决一段时间之内的插入问题。
- 公共表:有些表数据量小,变动少,而且高频查询——比如地理区域等等,那么可以在每个数据库之中都保存一份
17. 如果MySQL的主从分离的情况,怎么样进一步优化?
优化方法有很多,此处只是拿主写从读的情况举例,并且分析:
我们都知道mysql之中如果设置了索引的话可以加快读取数据的效率,也知道mysql之中的主从同步是使用binlog实现的。
按理来讲,他们的打开都是对系统的效率和稳定性有帮助的,但是此处我们的优化方式却是选择性的关闭:
- 主库直接关闭索引
- 从库关闭binlog
为什么?主库只写,那么就省去了维护索引的时间(本来也不读),从库只读,因此直接禁止其写入binlog(反正没人从你这备份,你要是宕机了也是去主库那里拿取数据)
18. Java之中的 Thread.sleep() 原理
参考:https://blog.csdn.net/yb223731/article/details/94560006
两个问题:
- 假设现在是 20018-12-03 12:00:00.000,如果我调用一下 Thread.Sleep(1000) ,在 20018-12-03 12:00:01.000 的时候,这个线程会不会被唤醒?
- 某人的代码中用了一句看似莫明其妙的话:Thread.Sleep(0) 。既然是 Sleep 0 毫秒,那么他跟去掉这句代码相比,有啥区别么?
答案:
- 不一定。只是参与排队,能不能排到你和你醒不醒无关
- 有区别。Linux和Windows的进程轮转方式不同。Linux之中是时间片轮转,按照时间片公平分配每个进程。Windows是抢占式,先将进程根据优先级,饥饿时间(多长时间未使用CPU)来排序出总的优先级。然后将CPU的控制权直接给这个进程,只要这个进程自己不放弃CPU,那么CPU会一直被其独占。对这种情况,
Thread.sleep(0)可以触发操作系统进行一次进程CPU竞争。这样就给了其他的进程,比如Paint获得CPU控制权的能力,不至于程序假死。
18.1 sleep的底层实现
挂起线程,且用其提供的参数设置一个定时器。时间结束之后,定时器触发,内核修改线程或者进程的状态,比如标记线程为就绪从而进入就绪队列等待调度。
可变定时器原理:
硬件层面是一个固定时钟+计数器实现的。每一个时钟周期,计数器递减。计数器为0的时候产生中断,对外表现为触发。内核注册一个定时器之后可以收到中断。
19. Java内存泄露几种方式
参考:详解Java应用程序中的内存泄露是如何发生的 - 嘶吼RoarTalk的文章 - 知乎 https://zhuanlan.zhihu.com/p/32540739
内存泄露,即对象已经不会被使用到,但是仍然被引用,从而GC无法将其回收的情况。一般而言,我们说的内存泄露都是在堆之中(栈之中会跟着方法的调用而产生或者清除)。
19.1 静态字段保持对象引用
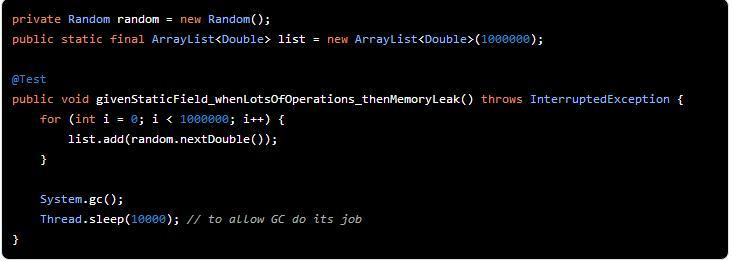
此处的ArrayList是一个静态对象,在赋值之后就再没有使用了。但是由于是静态对象,即使再没有使用也不会被回收。
19.2 在长字符串上面调用String.intern()
String.intern()方法作用为将字符串放在常量池之中。常量池之中的内容当然不会被释放,始终存在。如果你读了一个80M的txt file进来,你将会收获内存泄露带来的OOM。
当然,Java8之后没有这种问题,因为使用了meta Space来替换了 Perm Gen 空间,只要你内存够,自然不会OOM。但是内存泄露却是实打实发生了。
19.3 数据库连接,URL链接等等
数据库,FTP,URL链接等等,只要没能正确关闭,就会有问题。
比如在使用一个URLConnection,一直在获取数据并且写入InputStream,那么只要不关闭连接,就会一直写入,比如一些保活报文等等。那么就会一直写入,且这部分内存不会被GC清除(因为其一直打开),那么就会造成内存泄露。
19.4 将没有hashCode()和 equals()的对象放入HashSet之中

比如这个类放入HashSet之中。
我们都知道,hashMap和HashSet之中无论是查找还是修改,都是先比较hashCode再比较equals()方法的。那么如果这两个方法都没有的一个class,没有办法进行判定,也就无从谈起使用了。
20. waiting和blocked的区别
二者之间只是感觉很像,实际上是南辕北辙。
waiting的意义是线程正在等待notify(),(wait, notify,notifyAll不分家),收到通知之后再进行下一步活动。和拿不拿锁没关系。
但是blocked之中的意义是线程正在等待获取锁,等锁拿到了才能进行下一步。
21. CPU之中的lock前缀原理
参考:https://zhuanlan.zhihu.com/p/34556594
看到多线程的很多情况下,比如volatile, CAS等等操作在CPU的指令上面都是加上了lock前缀,下面是lock前缀的特点:
- 确保对内存的读-改-写操作原子执行。
- 禁止该指令之前和之后的读/写指令重排序
- 将写缓存区的所有数据刷到内存之中
第一点保证了其指令的不可打断,第二条和第三条构成了volatile的语义,那么结合起来就是CPU的lock前缀的原理。
22. happens-before
happens-before用来描述两个操作之间的顺序关系,这两个操作可以在一个线程之内,也可以不在一个线程之内。
其也并不一定严格意味着执行时间上面的顺序,而是意味着前一个的操作结果对后一个操作结果可见。
23. InnoDB 的意向锁
参考:InnoDB 的意向锁有什么作用? - 发条地精的回答 - 知乎 https://www.zhihu.com/question/51513268/answer/127777478
我个人看来,意向锁是用来减少锁之间冲突的一种有效办法。
在InnoDB之中,根据粒度不同,有行锁和表锁。那么考虑一下下面这个例子:
有两个事务:A和B。事务A锁住了表之中的一行,让其可读不可写。这个时候事务B想要去申请表锁,那么这个时候如果B申请到了表锁,就意味着其可以对整个表做写操作,那么和行锁的含义冲突了。
数据库想要避免冲突,就得让B的申请被阻塞,直到A释放了行锁。
那么数据库本身如何判断这个冲突呢?
- 判断是否整张表上面已经有了表锁。
- 判断表之中的每一行是否已经被行锁锁住。
第一个可能比较好判断,第二个的话看情况需要遍历整张表才行。那么遍历的复杂度是O(n),如果这张表很大,比如数据量在200万,那么这个开销是不可接受的。
在这种情况之下,就出现了”意向锁“。
在意向锁存在的情况之下, 上面的判断就可以改成:
- 不变
- 发现表上面有共享意向锁,那么说明某些行被共享行锁锁住,因此事务B的申请表的写锁的操作会被阻塞。
注意:申请意向锁的动作是数据库完成的,就是说,事务A申请一行的行锁的时候,数据库会自动先开始申请表的意向锁
24. Nginx反向代理下面拿到客户端的真实IP
参考:https://blog.csdn.net/Zps_258147/article/details/78665027
有了Nginx作为反向代理之后,服务器一直拿不到真实的IP,只能拿到Nginx的IP。
好在转发的请求之中在头部会多一个X-FORWARDED_FOR的信息,用来跟踪原来的客户端地址和原来客户端请求的服务器地址。
如果在多级的反向代理之后,X-FORWARDED-FOR之中的值不只是一个,而是一串IP值。如果这种情况的话,可以去取其中第一个非unknown的有效IP字符串。

然后将Nginx的Nginx.conf改写成:
location / {
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
25. 段页式剖析
为什么有分段,还有分页?
原文链接:https://blog.csdn.net/zouliping123/article/details/8869455
分段的意义在于,代码被分成几个具有意义的段,比如:
进程是操作系统资源分配的最小单元。操作系统分配给进程的内存空间中包含五种段:数据段、代码段、BSS、堆、栈。
-
数据段:存放程序中的静态变量和已初始化且不为零的全局变量。
-
代码段:存放可执行文件的操作指令,代码段是只读的,不可进行写操作。这部分的区域在运行前已知其大小。
-
BSS段( Block Started By Symbol):存放未初始化的全局变量,在变量使用前由运行时初始化为零。
-
堆:存放进程运行中被动态分配的内存,其大小不固定。
-
栈:存放程序中的临时的局部变量和函数的参数值。
那么每个段的大小是不需要一致的,但是每个段而言其本身是要占据连续空间的。其分配有意义,但是粒度还是较大。
而且每一个段都含有一组意义相对完整的信息,分段的目的是为了满足用户的需要,因此更容易实现共享。
对于分页而言,其粒度就小很多了,一个页4KB,那么带来的不便就是其本身不带有任何意义(都指定大小了咋有特殊意义)。虽然页本身不可再分,但是页和页之间是完全没必要连在一起的,相比之下粒度就细了很多。
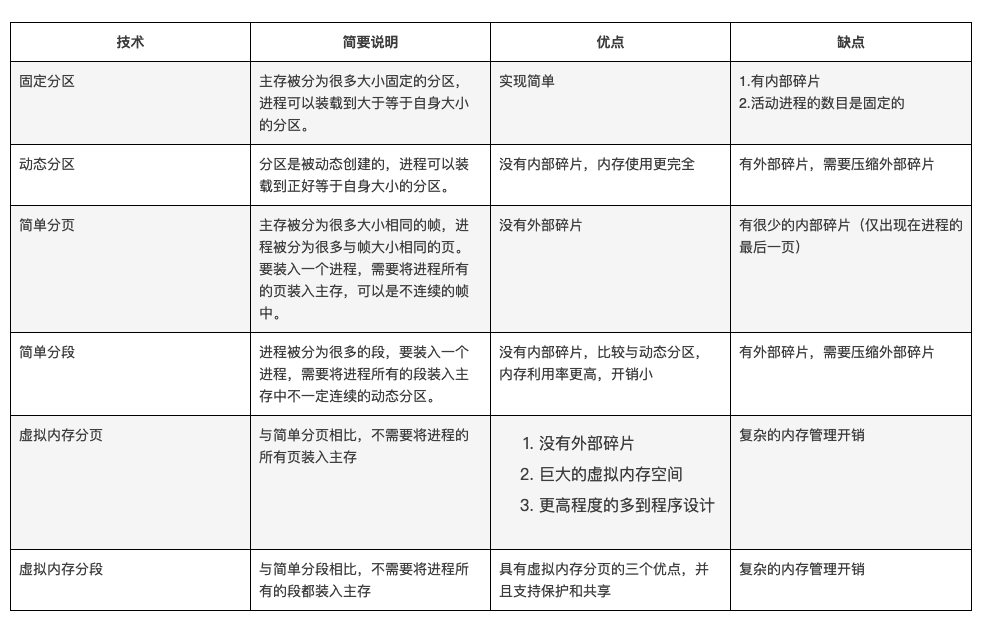
那么如果段页式结合呢?实际上就是去根据段号找相应该段的段表,然后页号用来检索页表并且查找到帧号。
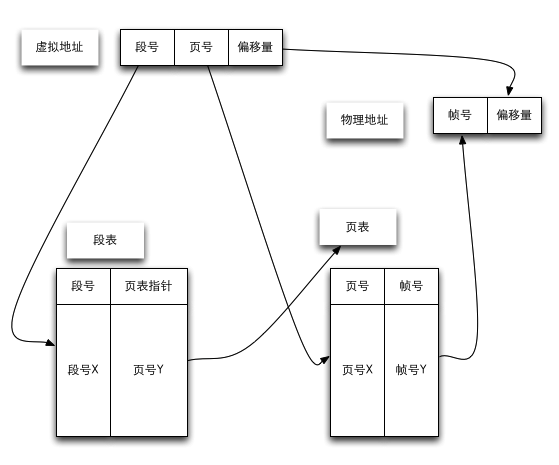
最后来一个网上发烂了的答案:
分页和分段有许多相似之处,比如两者都不要求作业连续存放.但在概念上两者完全不同,主要表现在以下几个方面:
(1)页是信息的物理单位,分页是为了实现非连续分配,以便解决内存碎片问题,或者说分页是由于系统管理的需要.段是信息的逻辑单位,它含有一组意义相对完整的信息,分段的目的是为了更好地实现共享,满足用户的需要.
(2)页的大小固定,由系统确定,将逻辑地址划分为页号和页内地址是由机器硬件实现的.而段的长度却不固定,决定于用户所编写的程序,通常由编译程序在对源程序进行编译时根据信息的性质来划分.
26. finally 代码块一定会被执行吗?finally代码块和try代码块,catch代码块的执行顺序如何?
参考:https://blog.csdn.net/qq_39135287/article/details/78455525
https://blog.csdn.net/hj7jay/article/details/68483039
答案:不一定会被执行。
-
未进入try模块,则不会进入catch
-
如果进入了try模块:
- 如果在try之中加入了
System.exit(0),那么也不会执行。因为其代表退出当前Java虚拟机。 - 当一个线程在执行try语句块,或者catch语句块的时候被打断或者终止。例如守护线程在执行中途遇到所有的非守护线程都结束了,那么守护线程也会立刻结束,对应的catch语句块也肯定不会执行。
public class Test { public static void main(String[] args) { Thread t = new Thread(new Task()); t.setDaemon(true); //置为守护线程 t.start(); try { TimeUnit.SECONDS.sleep(1); } catch (InterruptedException e) { throw new RuntimeException("the "+Thread.currentThread().getName()+" has been interrupted",e); } } } class Task implements Runnable { @Override public void run() { System.out.println("enter run()"); try { System.out.println("enter try block"); TimeUnit.SECONDS.sleep(5); //阻塞5s } catch(InterruptedException e) { System.out.println("enter catch block"); throw new RuntimeException("the "+Thread.currentThread().getName()+" has been interrupted",e); } finally { System.out.println("enter finally block"); } } } /******************* 控制台打印如下 enter run() enter try block ********************/ - 如果在try之中加入了
下面梳理多种情况之下,try代码块,catch代码块和return代码块的顺序和赋值关系:
- try之中有return,finally之中没有return:
package com.test;
public class MyTest {
public static void main(String[] args) {
System.out.println("main 代码块中的执行结果为:" + myMethod());
}
public static int myMethod() {
int i = 6;
try {
System.out.println("try 代码块被执行!");
// i = i/0;
return 1;
} catch (Exception e) {
System.out.println("catch 代码块被执行!");
return 2;
} finally {
System.out.println("finally 代码块被执行!");
}
}
}
结果:
try 代码块被执行!
finally 代码块被执行!
main 代码块中的执行结果为:1
可见这种情况下,try执行之后,返回值返回之前,会先执行finally。
- 当将
i=i/0的注释去掉(产生Exception)的时候,catch也会进入,其执行顺序为:
try 代码块被执行!
catch 代码块被执行!
finally 代码块被执行!
main 代码块中的执行结果为:2
可见顺序是try-catch-finally-返回catch的返回值
- 如果try,catch,finally之中都具有返回值,而且都进去过,怎么办?
package normalTest.TryCatchTest;
public class AllHaveReturnValueTest {
public static void main(String[] args) {
System.out.println("main 代码块中的执行结果为:" + myMethod());
}
@SuppressWarnings("finally")
public static int myMethod() {
try {
System.out.println("try 代码块被执行!");
int i = 1 / 0;
return 1;
} catch (Exception e) {
System.out.println("catch 代码块被执行!");
return 2;
} finally {
System.out.println("finally 代码块被执行!");
return 3;
}
}
}
这种情况下,三部分的代码都会进入,但是最后的返回值就是finally之中的返回值。
try 代码块被执行!
catch 代码块被执行!
finally 代码块被执行!
main 代码块中的执行结果为:3
- 在方法之中有变量定义,在try之中返回了这个变量,但是在finally之中对变量做了操作,最后的返回值如何?
package com.test;
public class MyTest {
public static void main(String[] args) {
System.out.println("main 代码块中的执行结果为:" + myMethod());
}
public static int myMethod() {
int i = 1;
try {
System.out.println("try 代码块被执行!");
return i;
} finally {
++i;
System.out.println("finally 代码块被执行!");
System.out.println("finally 代码块中的i = " + i);
}
}
}
结果:
try 代码块被执行!
finally 代码块被执行!
finally 代码块中的i = 2
main 代码块中的执行结果为:1
为什么这个时候输出结果居然是1呢?
原因:程序会先将try或者catch之中代码块的返回值保留,然后执行finally代码块之中的语句。那么finally哪怕把变量改出花,其也不会对最终的返回值造成任何的影响。
注意:保留返回值,只是用于return和throw语句,不适用于break或者continue语句,因为这二者根本没有返回值。