在很多流系统之中,比如 Flink,kafka和其他的等等之中有一个被广泛讨论的特性:精确一次(Exactly once),但是到底什么是“Exactly once”?怎么才算是实现了”exactly once”?下面进行一下浅析。
1. 背景
本文分析了流计算系统中常说的”exactly once”特性,主要观点是:exactly once 并不保证完全一样。
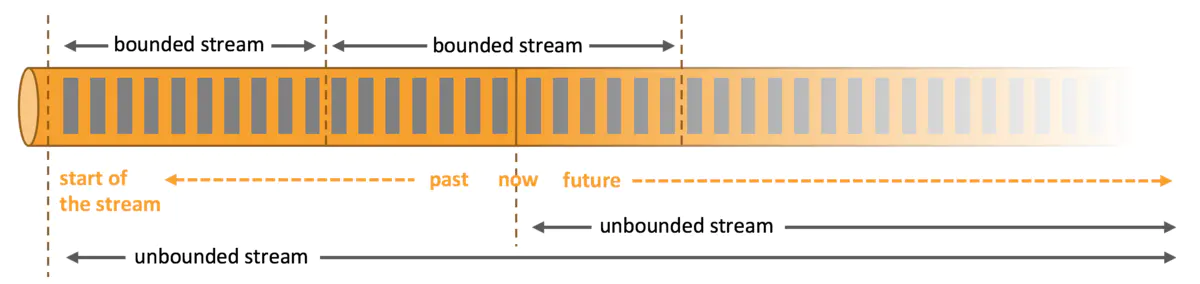
什么是有界数据集和无界数据集?
有界数据:在常规处理之中,我们都会从Mysql等之中拿到信息进行处理,那么处理此类数据的时候,特点是数据为静止不动的,没有进行追加,或者是再处理的时刻不需要考虑追加写入操作。这种又称为批处理,batch processing。
无界数据:对于某些场景而言,类似Kafka的持续计算等等都是无界数据集。无界数据集在处理的当下要发生持续变更,追加等等。这种又称为流计算,Stream Processing。
场景比较:无界数据集和有界数据集,很像池塘和大河,在计算池塘之中的数据时候,只需要将池塘之中当前所有的鱼计算一起就可以了。但是无界数据集,就像江河之中的鱼,在奔流到海的过程之中,每时每刻都有鱼流过而进入大海,那么计算鱼的数量就是持续追加的。
二者的数据集相对而言是一个模糊的概念,将粒度拉细,如果只是一条一条的处理,那么就可以认为是无界的,如果将粒度做粗,在一个时间段之中做一定的数据处理,那么数据又可以认为是有界的。既然二者之间可以互换,那么业界也就开始追寻批流统一的框架。
可以同时实现批处理和流处理的框架有Apache Spark和Apache Flink。
- Apache Spark的流处理场景就是微批场景,也就是会在特定的时间间隔之内发起一起计算,而不是每条都触发计算。
- Apache Flink最终将批处理和流处理混合到同一引擎当中,使用Apache Flink可以同时实现批处理和流处理任务。
那么,流处理在一般情况下可以简单的描述为对无界数据或者事件的连续处理。
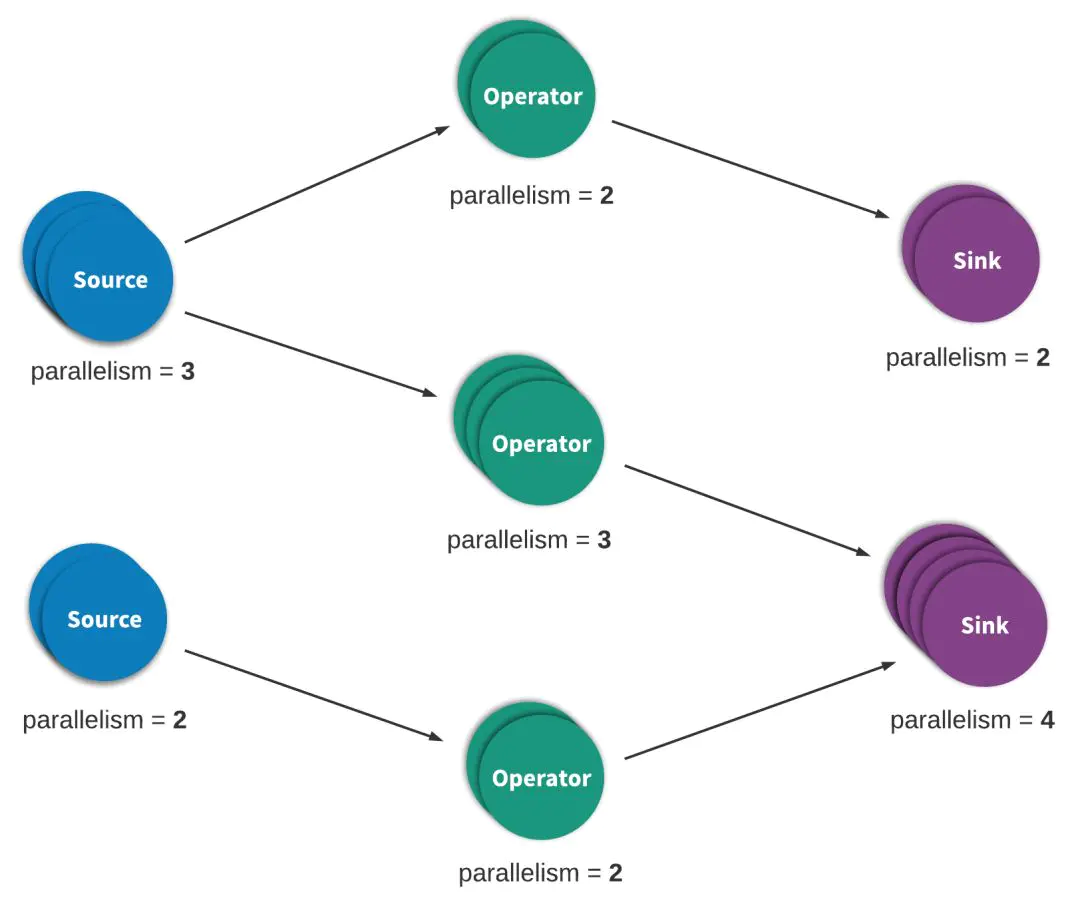
流处理程序,一般可以被看做是有向图,而且一般都是有向无环图。这种图中,每个边表示数据或者事件流,每个顶点表示运算符,会使用程序之中定义的逻辑处理来处理来自相邻边的数据和事件。
两种特殊的顶点,为source 和 sink。source 读取外部数据/事件到应用程序之中,而sink通常会收集应用程序生成的结果。示例如下:
那么相应的, 流处理引擎就要允许用户指定可靠性语义,因为网路或者机器等原因,无法保证每次信息都被准确传递。一般而言,流处理隐情为应用程序提供了三种数据处理语义:至多一次,至少一次和精确一次。
宽松来看的三者定义:
- 最多一次 at-most-once: 本质上是一种“尽力而为”的方法,保证数据或者事件由应用程序之中的所有算子处理最多一次。这意味着,如果数据在被流应用程序完全处理之前就丢失了,则不会进行其他重新尝试,或者重新发送。

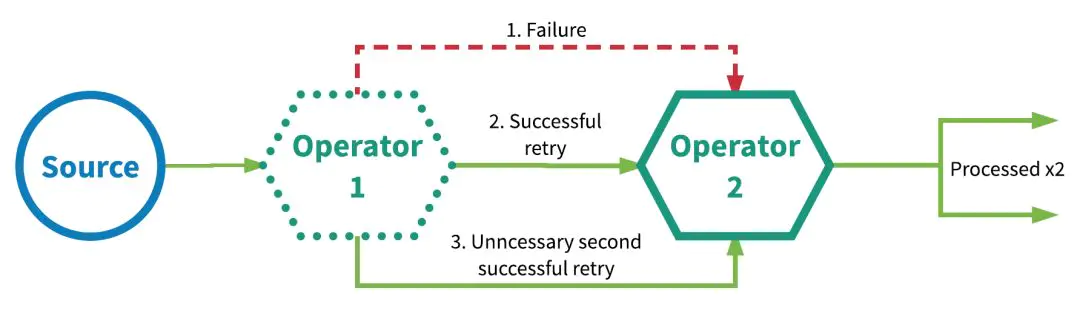
- 至少一次 at-least-once:应用程序之中,所有算子都保证数据或者事件被处理至少一次,那么如果事件在流应用程序完全处理之前丢失,是会重传的。如果重传且没有去重,那么后果就是有些数据被处理不止一次。下面图中描述了重传不止一次导致数据最终输出不止一份:
-
精确一次 exactly-once:即使在系统之中存在各种故障的情况下,所有算子都保证事件被“精确一次”的处理。有两种流行的机制来实现“精确一次”的处理语义:
- 分布式快照/状态检查点
- 至少一次事件传递和对重复数据去重
在我个人看来,第一种方式是“真正的”精确一次,即各个算子之中都有checkpoint,在发生故障时候统一进行回滚,这也是分布式事务的实现方式,比如Spring之中。而第二种,更多的是“补救”,即我通过传递不止一次和将传递的结果进行去重,来达到实际上的“精确一次”。
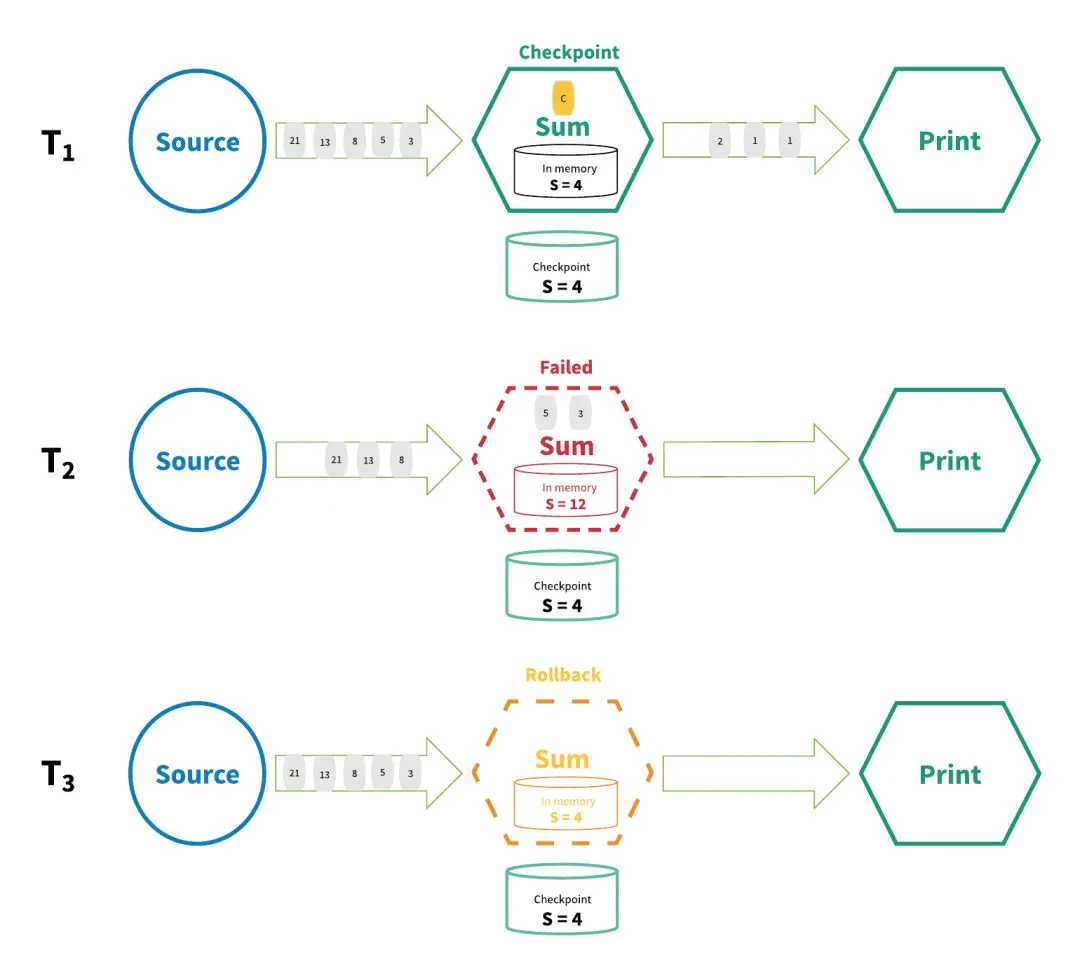
精确一次的第一种,分布式快照/状态检查点,机制之中,所有算子的状态都会定期做ckeckpoint,如果系统之中的任何地方发生失败,那么所有算子统一回滚到最新的全句一致checkpoint。在回滚期间,暂停所有处理,源(source)也会重置为和最近的checkpoint相对应的正确偏移量。
那么在这种情况下,实际上整个系统变成了最近的一次“正常”状态,在此基础上再进行重新启动。如下图:
分析下另一种“补救”的方式:在每个算子上面至少一次的事件传递和重复去重,二者叠加来实现“exactly once‘。这种机制要求为每个算子维护一个事务日志,以跟踪其处理的事件。事务日志是机制实现的关键。如下图所示:
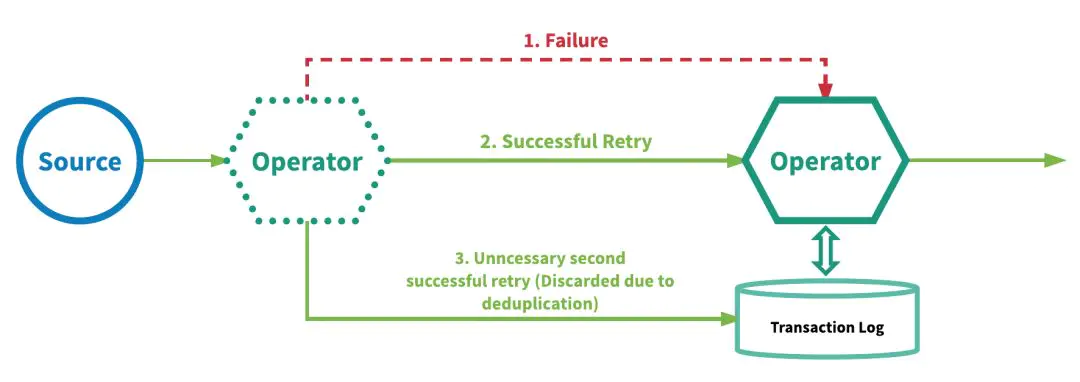
2. “精确一次”是真正的”精确一次吗“
根据前面的分析,我们可以得知,“精确一次”并不是真正的“精确一次”,因为时时刻刻系统都有可能出现故障。这里的’精确一次’,指的实际上是保证引擎管理的状态更新只提交一次到后端的持久化存储。
上面的两种机制,都使用持久的后端存储来作为其真实性的来源。这个后端存储,可以保存每个算子的状态,并且向整个系统提供更新。对于分布式快照这种方式,持久后端状态用于保存流的全局一致状态检查点(每个算子的检查点状态),对于至少一次数据或者事件传递并删除重复数据,持久后端状态不仅存储每个算子本身的状态(和前面的要区分开,不需要存储检查点状态,因为后面的log机制会进行保证),还要存储每个算子的事务日志,该日志跟踪其已经完全处理的所有事件。
3. “分布式快照”和“至少一次事件传递和删除重复数据”的比较
二者的性能差异还是比较大的:
-
分布式快照:其性能开销是最小的,状态检查点checkpoint可以在后台异步执行。但是对于大型流应用程序,故障可能会频繁发生,导致引擎需要暂停应用程序并且回滚所有算子的状态。环节越多,故障发生的可能性就越大。反过来,流式应用程序性能收到的影响也就越大。但是,这种机制是非侵入性的,相对而言资源的影响最小。
-
至少一次传递+重复事件删除:可能需要更多资源,尤其是存储部分(因为还要维持一个log去保存对应的事件),这意味着要跟踪大量的数据,尤其是在流应用程序很大的情况下,在每个算子上面进行重复删除会造成大量的性能开销。但是相较第一种方式而言,这种对于性能的影响更小,相较于机制一的整体回滚,机制二之中失败的影响会更加局部性。
分布式快照 / 状态检查点的优缺点:
- 优点:
- 较小的性能和资源开销
- 缺点:
- 对性能的影响较大
- 拓扑越大,对性能的潜在影响越大
至少一次事件传递以及重复数据删除机制的优缺点:
- 优点:
- 故障对性能的影响是局部的
- 故障的影响不一定会随着拓扑的大小而增加
- 缺点:
- 可能需要大量的存储和基础设施来支持
- 每个算子的每个事件的性能开销
4. kafka 是如何实现的呢
这个特性是怎么实现的呢?在底层,它和TCP的工作原理有点像,每一批发送到Kafka的消息都将包含一个序列号,broker将使用这个序列号来删除重复的发送。和只能在瞬态内存中的连接中保证不重复的TCP不同,这个序列号被持久化到副本日志,所以,即使分区的leader挂了,其他的broker接管了leader,新leader仍可以判断重新发送的是否重复了。这种机制的开销非常低:每批消息只有几个额外的字段。你将在这篇文章的后面看到,这种特性比非幂等的生产者只增加了可忽略的性能开销。
可见是使用第二种方式。