一转眼一月过去,这一个月主要在忙业务,忙代码,很难空出专门的时间进行自我学习。既然看起来这个状况不会有什么改变,那就改变自己的学习习惯,见缝插针,也会有很大收获。
最近在学习的就是极客时间上面的《从0开始学大数据》。
下面的标题是课程的节号。有些自己觉得有新的想法的点会记在这里。
9. 为什么我们管Yarn叫作资源调度框架
下面是Yarn的本身的架构图:
实际上我们可以看到有两套主从:
- 在任务的角度,一个任务会有一个
ApplicationMaster,其对应的是其向ResourceManager拿到的container的内容,container可以有多个 - 从资源框架的角度,一个
ResourceManager会对应多个NodeManager
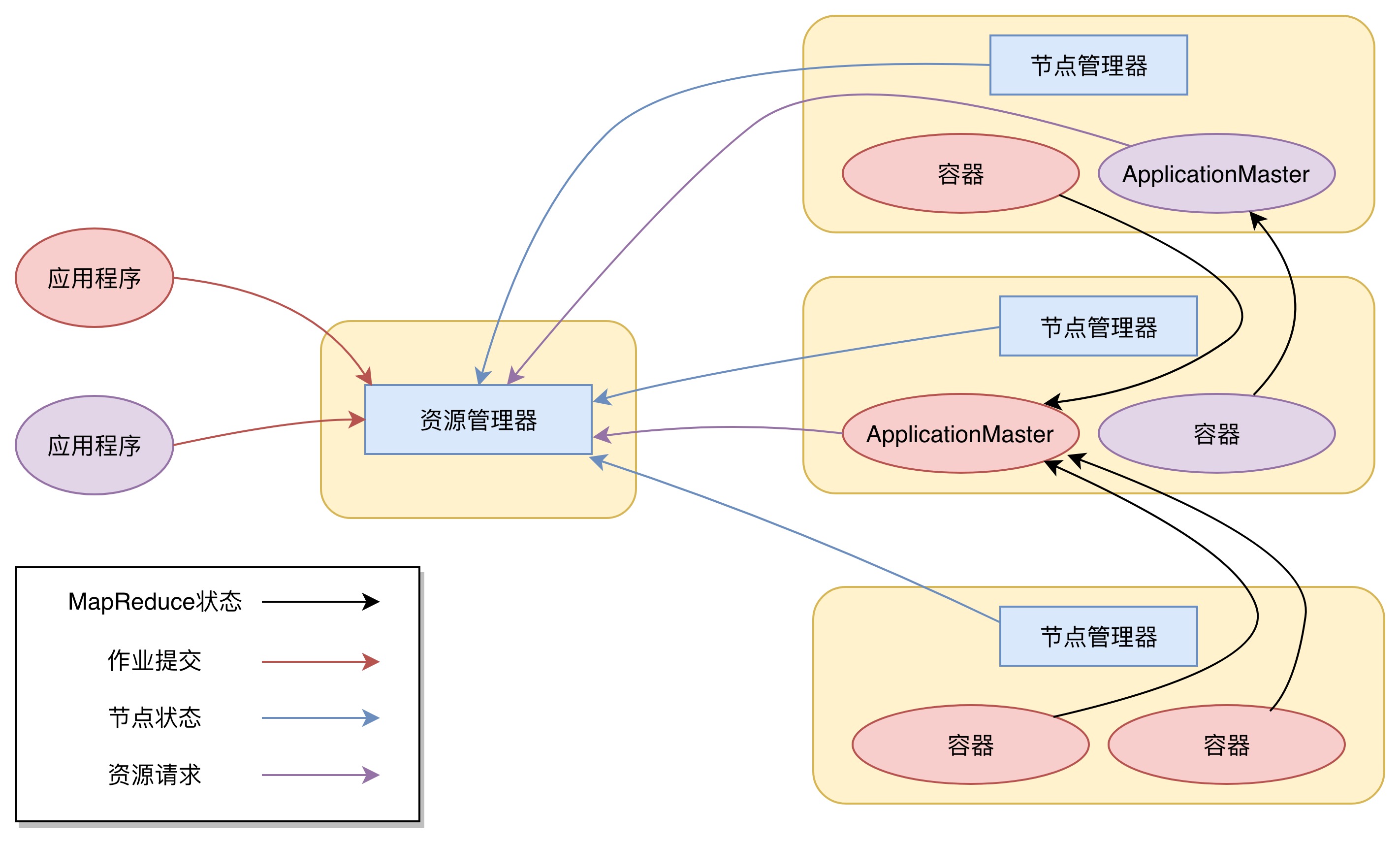
资源管理器,分为两方面的管理:调度器和应用程序管理器。一方面是从资源的分配角度得到的调度器,一方面是从程序的提交,监控等等角度看到的节点管理器。
9.2 框架和系统的区别
框架需要做到“依赖倒转”,即高层模块不能依赖低层模块,而是高层模块定义一个标准,由低级模块实现。
高层模块和低层模块之间的区别在于,在一个过程之中越靠前的就越高级(因为要从前面往后面调用,所以前面的模块给后面的模块规定标准)。
所谓高层模块和低层模块的划分,简单说来就是在调用链上,处于前面的是高层,后面的是低层。我们以典型的Java Web应用举例,用户请求在到达服务器以后,最先处理用户请求的是Java Web容器,比如Tomcat、Jetty这些,通过监听80端口,把HTTP二进制流封装成Request对象;然后是Spring MVC框架,把Request对象里的用户参数提取出来,根据请求的URL分发给相应的Model对象处理;再然后就是我们的应用程序,负责处理用户请求,具体来看,还会分成服务层、数据持久层等。
在这个例子中,Tomcat相对于Spring MVC就是高层模块,Spring MVC相对于我们的应用程序也算是高层模块。我们看到虽然Tomcat会调用Spring MVC,因为Tomcat要把Request交给Spring MVC处理,但是Tomcat并没有依赖Spring MVC,Tomcat的代码里不可能有任何一行关于Spring MVC的代码。
现在我们再回到MapReduce和Yarn。实现MapReduce编程接口、遵循MapReduce编程规范就可以被MapReduce框架调用,在分布式集群中计算大规模数据;实现了Yarn的接口规范,比如Hadoop 2的MapReduce,就可以被Yarn调度管理,统一安排服务器资源。所以说,MapReduce和Yarn都是框架。
相反地,HDFS就不是框架,使用HDFS就是直接调用HDFS提供的API接口,HDFS作为底层模块被直接依赖。
10. 模块答疑:我们能从Hadoop学到什么
10.1 水平伸缩和垂直伸缩
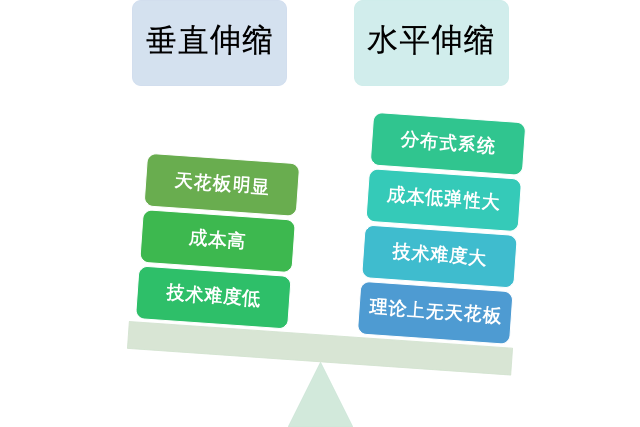
垂直伸缩和水平伸缩
通常将通过升级或增加单台机器的硬件来支撑访问量及数据量增长的方式称为垂直伸缩,垂直伸缩的好处是技术难度相对较低,对于小型应用而言是一种不错的选择。其缺点是机器的硬件是无法不断升级和增加的,很容易达到瓶颈,而如果想升级为更高级别的机器时通常带来的成本是指数级的,因此对于大型应用而言,垂直伸缩不是一种好的选择。
通常将通过增加机器来支撑访问量及数据量增长的方式称为水平伸缩,水平伸缩从理论上来说并没有瓶颈,其缺点是对技术上有较高的要求,另外在增加机器时,要考虑机器的增加对于空间、能源的占用。空间的占用要求机柜要足够充足,能源的占用则意味着电力、网络带宽的消耗,这些都会给应用的运营带来更高的成本。除此之外,当机器数量大幅度增加后,机器硬件出现故障的几率也将大幅度上升),此时软件上的容错、机器的管理和维护就显得至关重要了。
假如东西太多了,一个屋子没法全都放下,该怎么办?
- 水平伸缩:多建几个屋子
- 垂直伸缩:把屋子建的更大