本文之中会先将对应的执行步骤做一个梳理,然后对每一个模块之中的大致功能做一个介绍。
参考:https://time.geekbang.org/course/detail/100058801-278257
Flink 集群架构
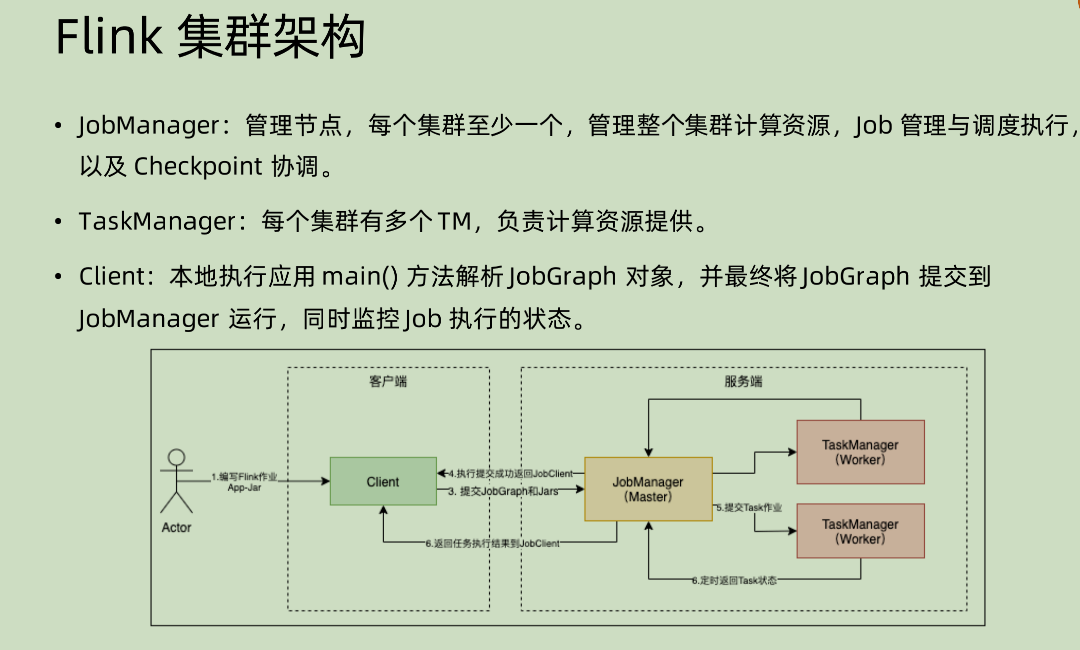
其中需要注意的点是:
- 和 Spark 不同,这里面的 Client 只是用来做一个解析生成的工作,本身不需要和 taskManager 通信来获得相应信息,管理全程是 JobManager 来执行的
JobManager
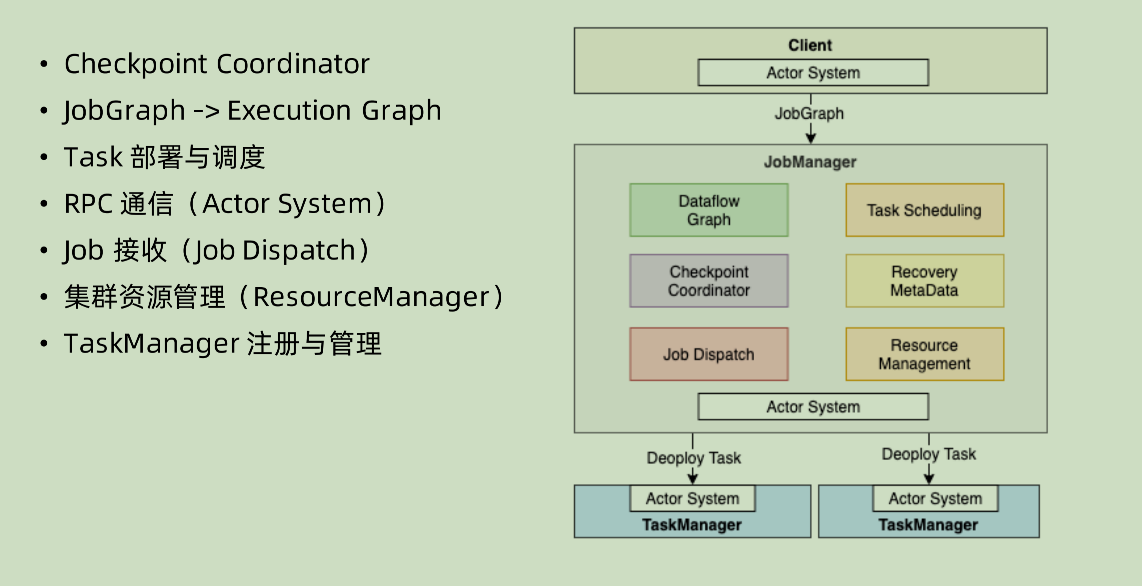
我们一点一点讲:
- CheckPoint Coordinator: 在 Flink 之中,是用 checkpoint 来做相关的管理的,比如如何保证 exactly once。 那么这里面就需要 JobManager 对当前的 Job 做相应管理。
- JobGraph -> Execution Graph: Execution Graph 本身是一个物理层面的逻辑执行图。JobGraph 是Client 将对应的 JAR 包进行解析之后生成的,但是 JobGraph 之中仅仅是对于整个流程的一个比较粗略的概括,对于最后的执行,比如并行度,数据之间的 shuffle 传输,这些都是由 Execution Graph 进行解析得出来的。
- Task 的部署和调度:显然 Task Scheduling 这个部分是 JobManager 所必须的,因为其要将任务具体分配到对应的执行节点。
-
RPC 通信:这部分是通过 Actor System 进行处理的,Actor System 基于 Akka 实现的,这部分 RPC 通信主要是用来对 TaskManager 本身的状态信息和某些指令,比如启停这种做传输。注意,这里面的 task 传输也是通过 actor system 这个 RPC,本人认为是 task 本身是信息性质的,而不是大规模的数据 shuffle 所需要的。
- Job 接收:很多时候一个 Job Manager 要接受很多 Job,那么对于这种多个 Job 之间的协调统筹,就是需要 Job DisPatcher 进行相关的操作,比如拿到 JobGraph 之后拆分并且分发。
- 集群资源管理:这部分针对于不同的模式有不同的实现,比如 standalone,yarn 和 k8s 其实现的方式就不同
- TaskManager 的注册和管理:这也应该是基本的 JobManager 所具有的功能了,毕竟要为下游进行一个任务的分配。
TaskManager
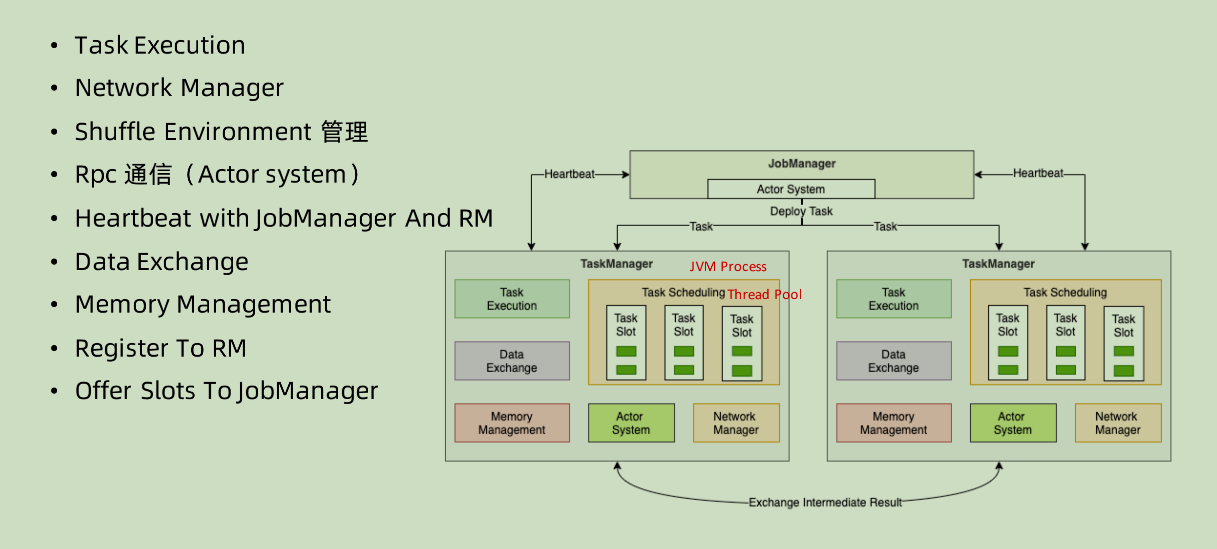
什么是 task?实际上就是一系列的 Operator 节点的组合。
- 作为整个系统之内的 worker 节点,其本身肯定要具备任务执行的功能
- Network manager: 管理网络相关的事务
- Shuffle Environment:这个部分是使用 Netty 来做的,因为在 Shuffle 这个过程之中,涉及到的数据量比较大,所以不能用基于 akka 实现的 actor system 进行信息性质的传递。和 Spark 之中相同,如果涉及到 groupByKey() 或者是分组操作,基本上都是需要 shuffle 的。
- RPC 通信:和上面提到过的一样,actor system
- Heartbeat with JobManager And RM: 心跳肯定还是要做的
- memory management:用来做序列化和反序列化
Client
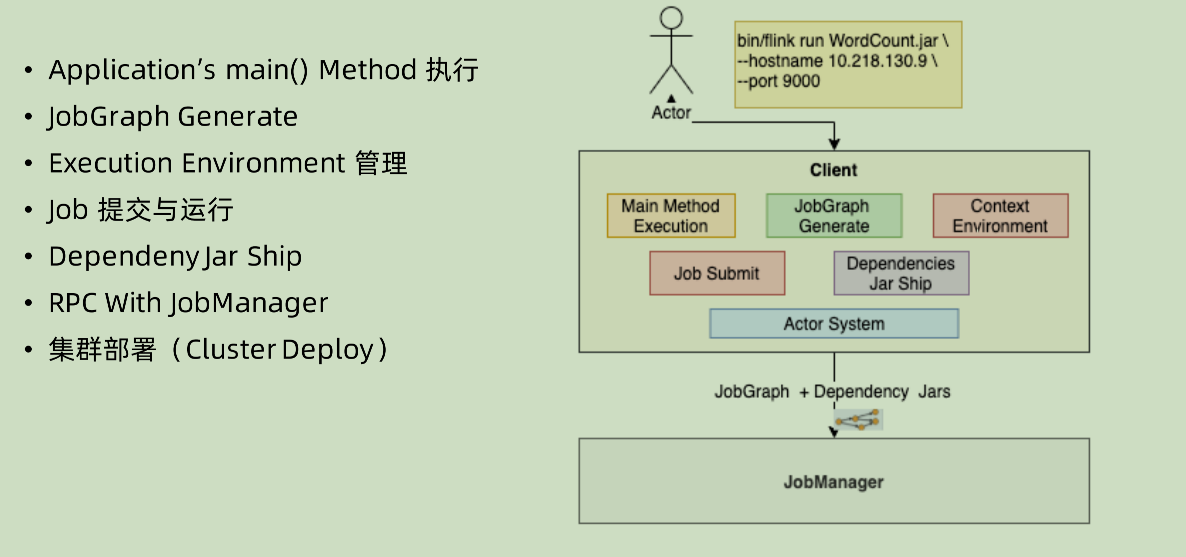
Client 之中,本身虽然只是用来生成 Jobgraph,但是也不能仅仅是对图的生成做操作。其实际上是生成相应的环境,并且在环境之中做相应的生成行动。
- Application main() 方法执行: client 端,是要将 main()方法在本地进行抽取,并且执行生成相应流程图的。
- Context Environment:在执行 application 的 main()的时候,也是需要一个环境来对应的生成相应的DAG。
- Job 提交和运行,dependency jarship: 其实在 flink 的架构里面,可以当做 client 是一个静态编译,jobManager 是一个动态执行的过程。在编译好之后,jobGraph 和dependency jar 一起被送到 jobManager 之中。
- 集群部署:在启动 yarn session 或者 k8s session 的时候,实际上也是在 client 之中启动相应的方法进行操作。
JobGraph
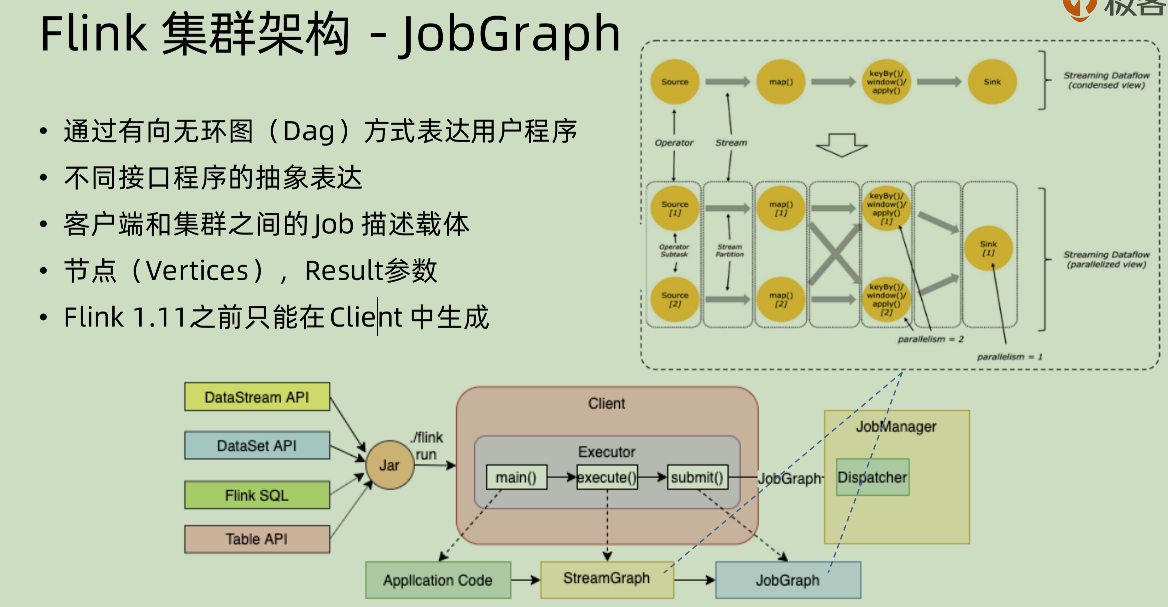
先按照中间的 client 进行讲解:
executor 是根据不同的部署来有不同的实现,比如 on yarn, on k8s 这些的实现都不同
- 首先是通过反射的方式,进行 application code 之中的 main() 方法的执行。这一步需要我们指定对应的类。
- 用 execute()来进行相关的 streamGraph 的生成,streamGraph 之中主要就是dataStream 的一些 transformation
- 使用 submit()来进行相关的 JobGraph 的提交,提交是直接提交到 dispatcher 之中,然后再做相应的分发